社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
有一个员工employees表简况如下:
建表语句如下:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
示例:
select * from employees where hire_date = (select max(hire_date) from employees);
有一个员工employees表简况如下:
请你查找employees里入职员工时间排名倒数第三的员工所有信息,以上例子输出如下:
select* from employees order by hire_date desc limit 2, 1;
有一个全部员工的薪水表salaries简况如下: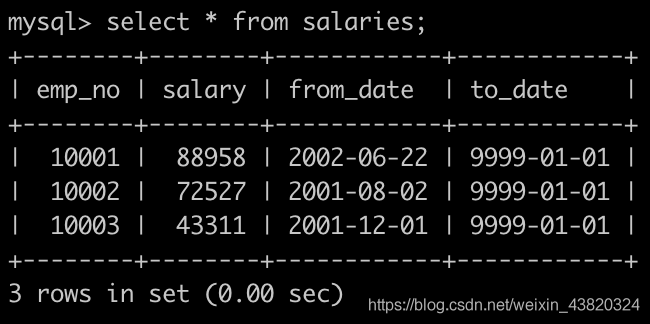
有一个各个部门的领导表dept_manager简况如下: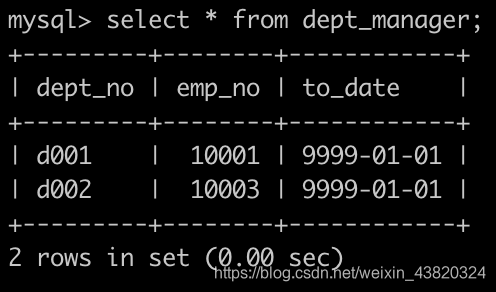
请你查找各个部门领导薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列,以上例子输入如下: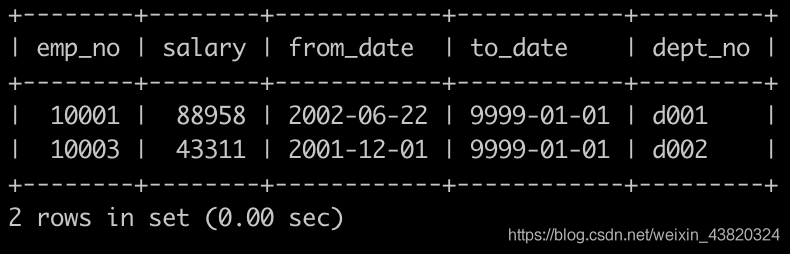
select s.*, d.dept_no
from salaries s, dept_manager d
where s.emp_no = d.emp_no
order by s.emp_no;
有一个员工表,employees简况如下:
有一个部门表,dept_emp简况如下:
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:
# 运行时间:36ms 占用内存:5496KB
select e.last_name, e.first_name, d.dept_no
from employees e, dept_emp d
where e.emp_no = d.emp_no;
# 运行时间:40ms 占用内存:5240KB
select e.first_name, e.last_name, d.dept_no
from employees e right join dept_emp d
on e.emp_no = d.emp_no;
表信息为Day4中相同
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工,以上例子如下:
select e.last_name, e.first_name, d.dept_no
from employees e left join dept_emp d
on e.emp_no = d.emp_no;
【注:本题与Day4题中的解法2区别在于left join和right join,连接好的左表是主表,若副(右)表无法与主表匹配,则自动模拟出NULL值】
有一个薪水表,salaries简况如下:
请你查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t,以上例子输出如下:
SELECT emp_no, COUNT(emp_no) AS t
FROM salaries
GROUP BY emp_no
HAVING t > 15
有一个薪水表,salaries简况如下: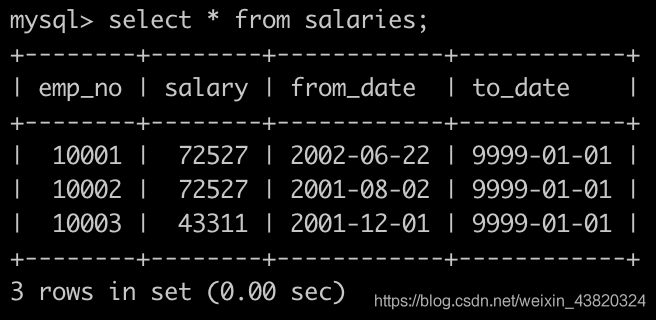
请你找出所有员工具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示,以上例子输出如下:
select distinct salary
from salaries
order by salary desc;
有一个员工表employees简况如下: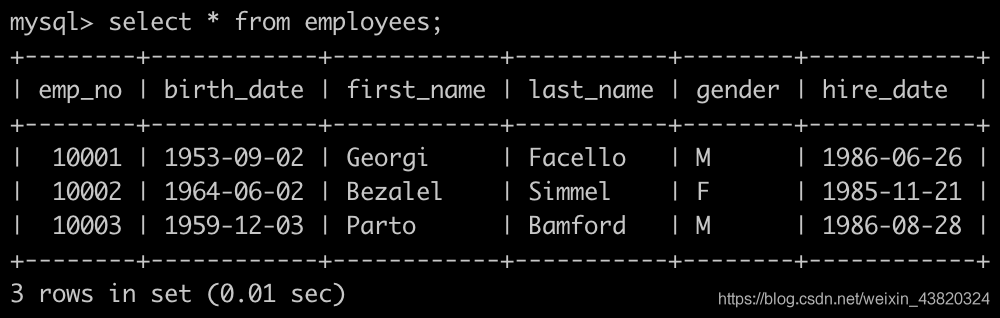
有一个部门领导表dept_manager简况如下: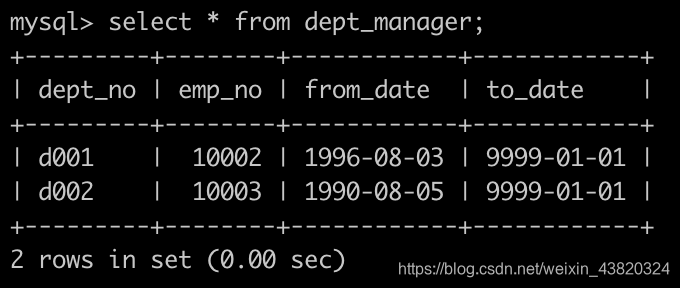
请你找出所有非部门领导的员工emp_no,以上例子输出: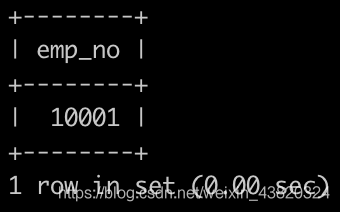
select e.emp_no
from employees e
where e.emp_no
not in (select d.emp_no from dept_manager d);
有一个员工表dept_emp简况如下:
第一行表示为员工编号为10001的部门是d001部门。
有一个部门经理表dept_manager简况如下:
第一行表示为d001部门的经理是编号为10002的员工。
获取所有的员工和员工对应的经理,如果员工本身是经理的话则不显示,以上例子如下:
SELECT e.emp_no, m.emp_no
FROM dept_emp e
JOIN dept_manager m
ON e.dept_no = m.dept_no
WHERE e.emp_no <> m.emp_no;
连接出所有的相同部门的‘员工—经理’组合,选择出员工≠经理的即可
有一个员工表dept_emp简况如下:
有一个薪水表salaries简况如下:
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列,以上例子输出如下:
SELECT d1.dept_no, d1.emp_no, s1.salary
FROM dept_emp as d1
INNER JOIN salaries as s1
ON d1.emp_no=s1.emp_no
WHERE s1.salary in (SELECT MAX(s2.salary)
FROM dept_emp as d2
INNER JOIN salaries as s2
ON d2.emp_no=s2.emp_no
AND d2.dept_no = d1.dept_no
)
ORDER BY d1.dept_no;
有一个员工表employees简况如下:
请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列,以上例子查询结果如下:
select *
from employees
where emp_no%2 = 1
and last_name != 'Mary'
order by hire_date desc;
有一个薪水表salaries简况如下: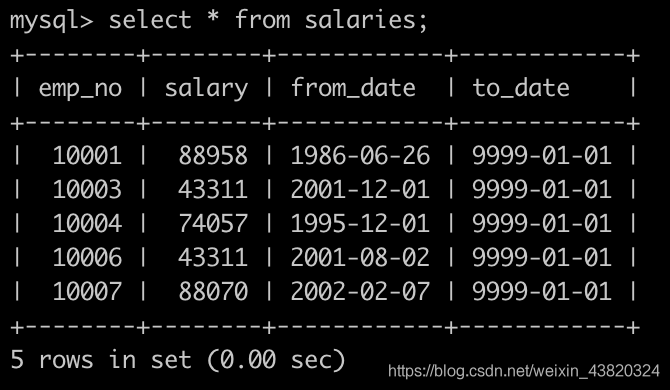
请你统计出各个title类型对应的员工薪水对应的平均工资avg。结果给出title以及平均工资avg,并且以avg升序排序,以上例子输出如下: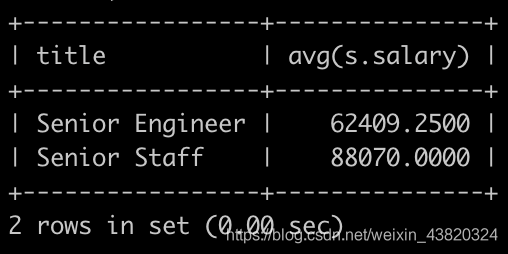
select t.title avg(s.salary)
from titles t join salaries s
on t.emp_no = s.emp_no
group by t.title;
有一个薪水表salaries简况如下:
请你获取薪水第二多的员工的emp_no以及其对应的薪水salary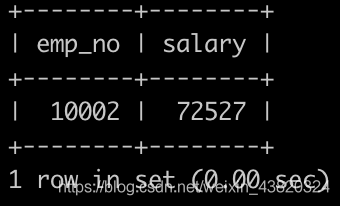
select emp_no, salary
from salaries
order by salary desc
limit 1, 1;
有一个员工表employees简况如下: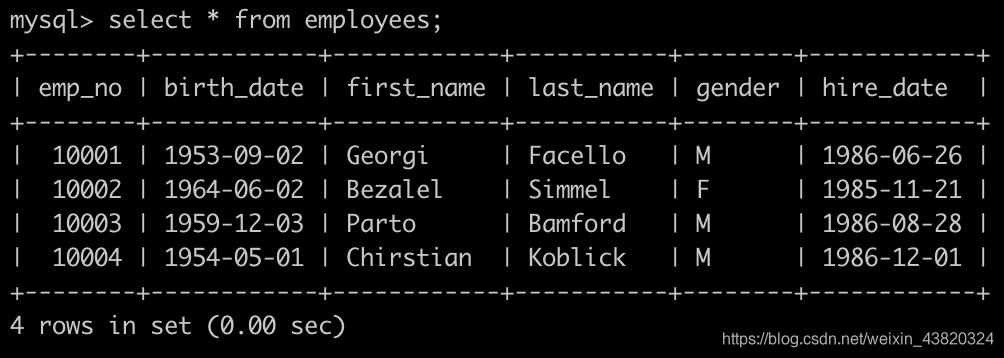
有一个薪水表salaries简况如下: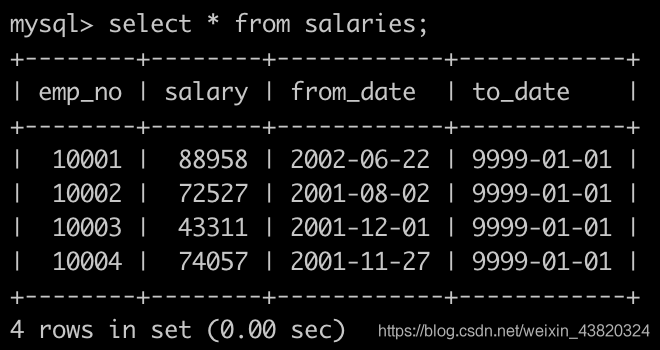
请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成,以上例子输出为: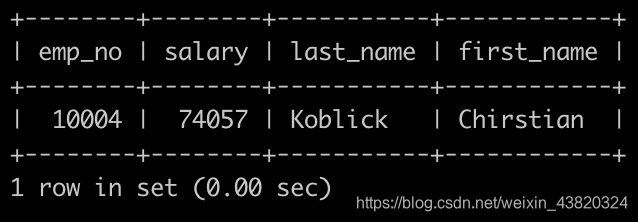
select s.emp_no, s.salary, e.last_name, e.first_name
from salaries s join employees e
on s.emp_no = e.emp_no
where s.salary = -- 第三步: 将第二高工资作为查询条件
(
select max(salary) -- 第二步: 查出除了原表最高工资以外的最高工资(第二高工资)
from salaries
where salary <
(
select max(salary) -- 第一步: 查出原表最高工资
from salaries
)
)
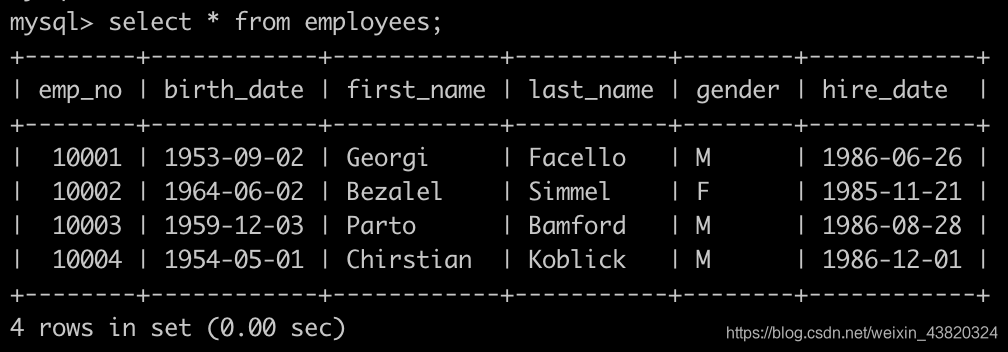
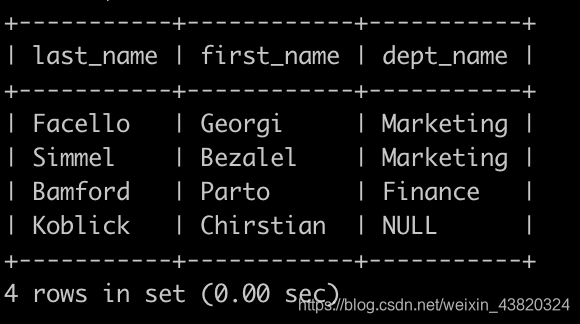
有一个员工表employees简况如下:
有一个部门表departments表简况如下: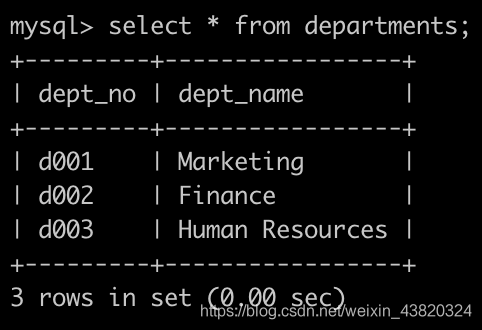
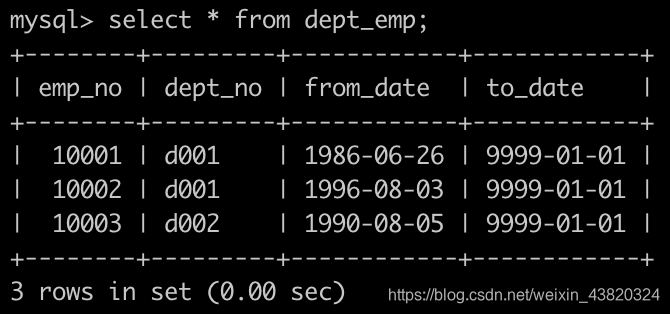
有一个,部门员工关系表dept_emp简况如下:
请你查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工,以上例子输出如下:
select e.last_name, e.first_name, d.dept_name
from employees as e
left join dept_emp as de
on e.emp_no = de.emp_no
left join departments as d
on de.dept_no = d.dept_no
有一个员工表employees简况如下: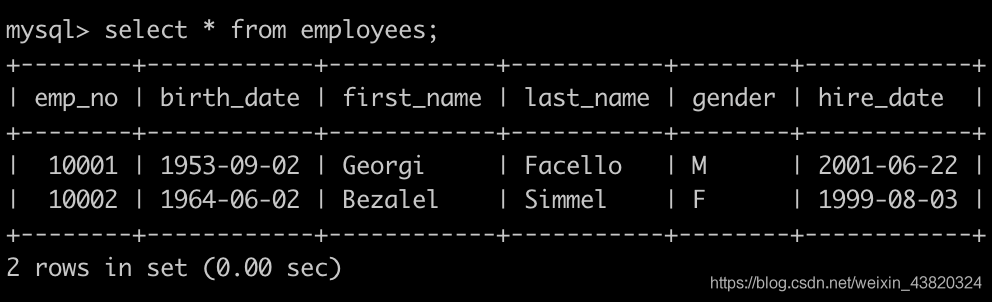
有一个薪水表salaries简况如下: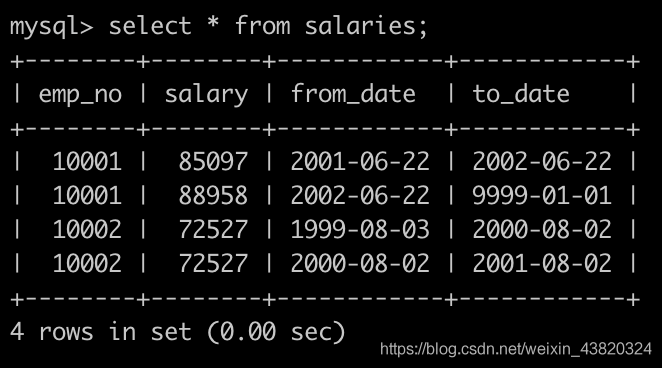
请你查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为
(注:可能有employees表和salaries表里存在记录的员工,有对应的员工编号和涨薪记录,但是已经离职了,离职的员工salaries表的最新的to_date!=‘9999-01-01’,这样的数据不显示在查找结果里面,以上emp_no为2的就是这样的)
/*
临时表a是员工入职时的薪水
临时表b是未离职员工当前的薪水
*/
select b.emp_no,(b.salary-a.salary) growth
from
(select s.emp_no,s.salary
from employees e,salaries s
where e.emp_no=s.emp_no
and e.hire_date=s.from_date) a,
(select emp_no,salary
from salaries
where to_date='9999-01-01') b
where b.emp_no=a.emp_no
order by growth
有一个部门表departments简况如下: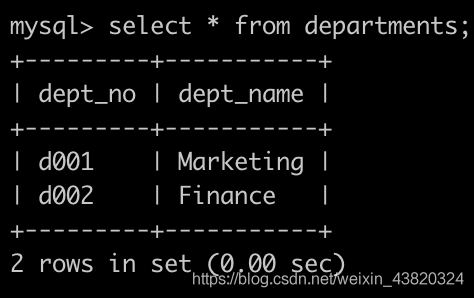
有一个,部门员工关系表dept_emp简况如下: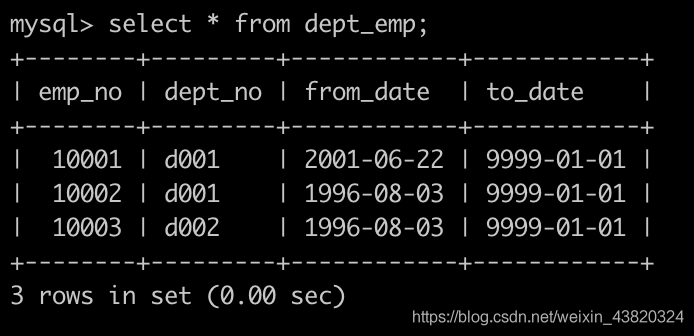
有一个薪水表salaries简况如下: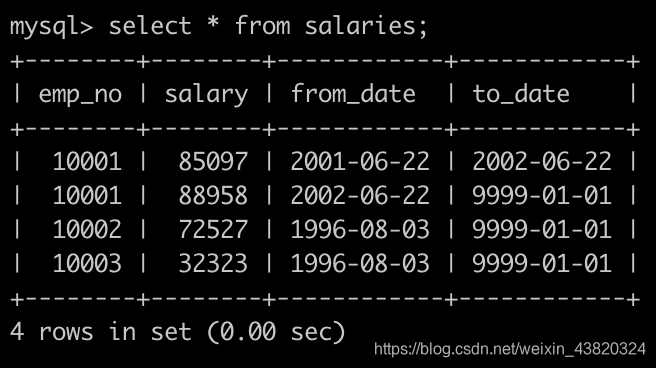
请你统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及部门在salaries表里面有多少条记录sum,按照dept_no升序排序,以上例子输出如下: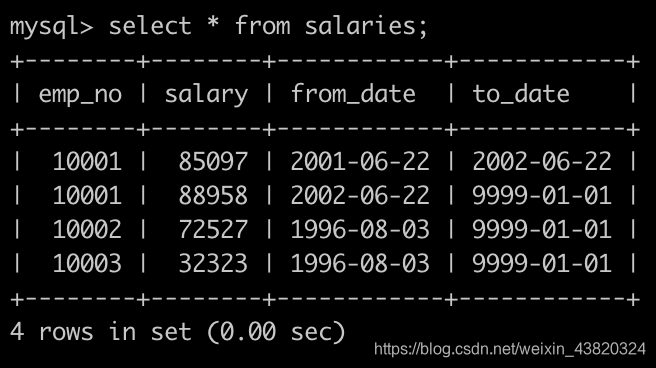
SELECT de.dept_no, dp.dept_name, COUNT(s.salary) AS sum
FROM (dept_emp AS de INNER JOIN salaries AS s ON de.emp_no = s.emp_no)
INNER JOIN departments AS dp ON de.dept_no = dp.dept_no
GROUP BY de.dept_no
ORDER BY de.dept_no
有一个薪水表salaries简况如下: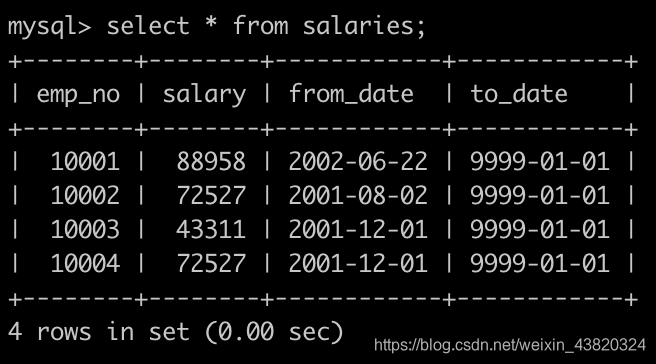
对所有员工的薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列:
select emp_no,salary,dense_rank() over(order by salary desc)as rank
from salaries
order by rank,emp_no;
注
下面介绍三种用于进行排序的专用窗口函数:
1、RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,4······
2、DENSE_RANK()
这就是题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,2······
3、ROW_NUMBER()
这个函数赋予唯一的连续位次。
例如,有3条排在第1位时,排序为:1,2,3,4······
窗口函数用法:
<窗口函数> OVER ( [PARTITION BY <列清单> ]
ORDER BY <排序用列清单> )
其中[ ]中的内容可以忽略
有一个员工表employees简况如下: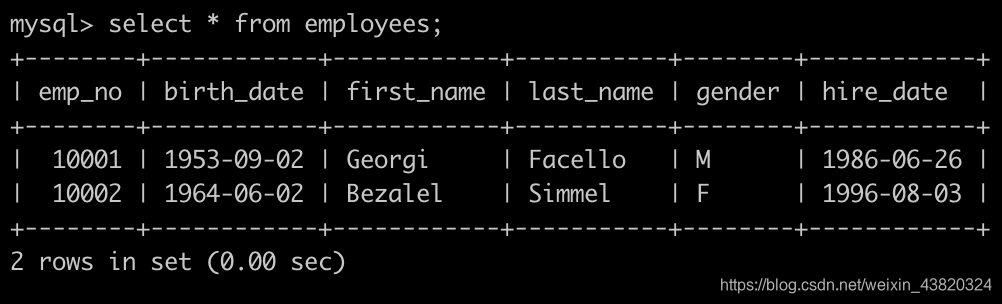
有一个,部门员工关系表dept_emp简况如下:
有一个部门经理表dept_manager简况如下: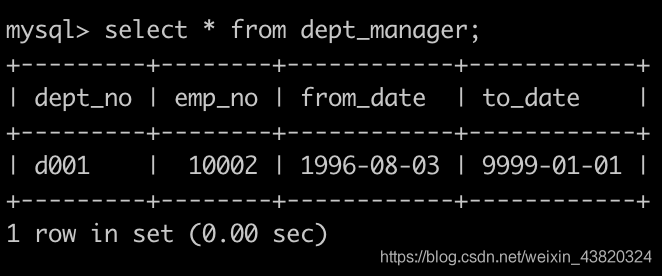
有一个薪水表salaries简况如下: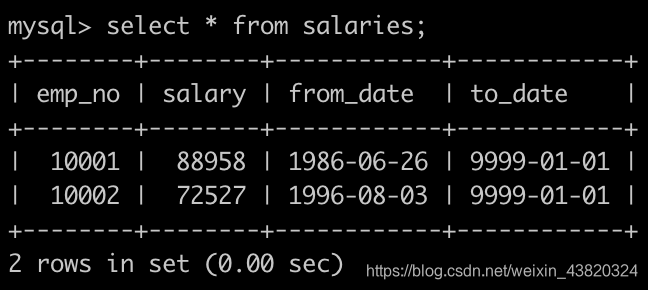
获取所有非manager员工薪水情况,给出dept_no、emp_no以及salary,以上例子输出: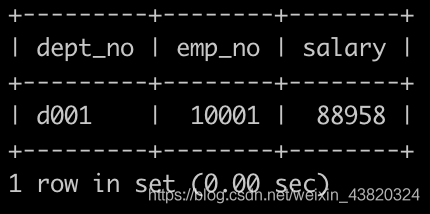
select de.dept_no, de.emp_no, s.salary
from dept_emp de inner join employees e on de.emp_no = e.emp_no
inner join salaries s on de.emp_no = s.emp_no
where de.emp_no not in (select emp_no from dept_manager);
有一个,部门关系表dept_emp简况如下:
有一个部门经理表dept_manager简况如下: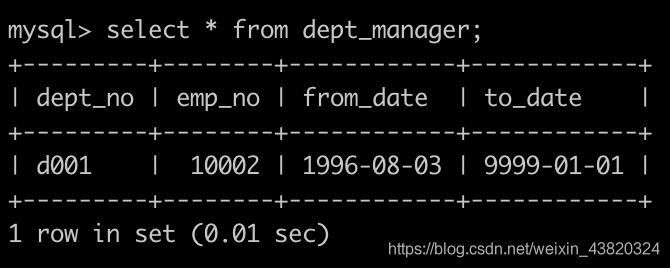
有一个薪水表salaries简况如下: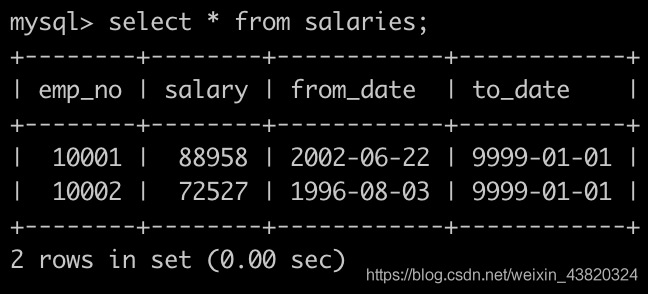
获取员工其当前的薪水比其manager当前薪水还高的相关信息,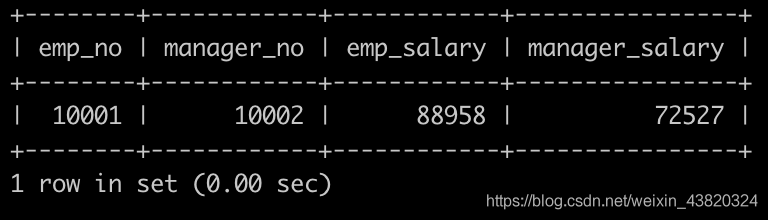
select a.emp_no,b.emp_no,a.salary,b.salary
from
(select de.emp_no,sa.salary,de.dept_no
from dept_emp de,salaries sa
where de.emp_no = sa.emp_no) as a,
(select dm.emp_no,sal.salary,dm.dept_no
from dept_manager as dm,salaries as sal
where dm.emp_no = sal.emp_no) as b
where a.dept_no = b.dept_no and a.salary>b.salary
有一个部门表departments简况如下:
有一个,部门员工关系表dept_emp简况如下: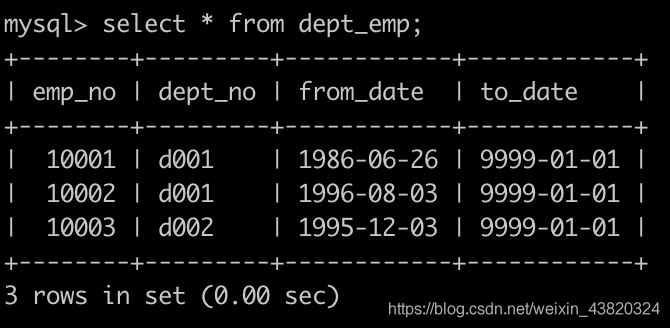
有一个职称表titles简况如下: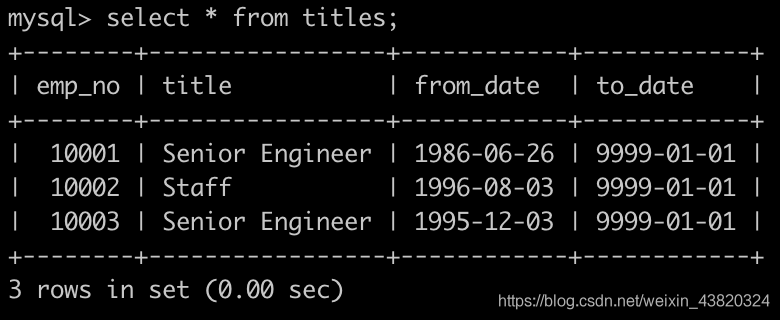
汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的员工的title以及该类型title对应的数目count,结果按照dept_no升序排序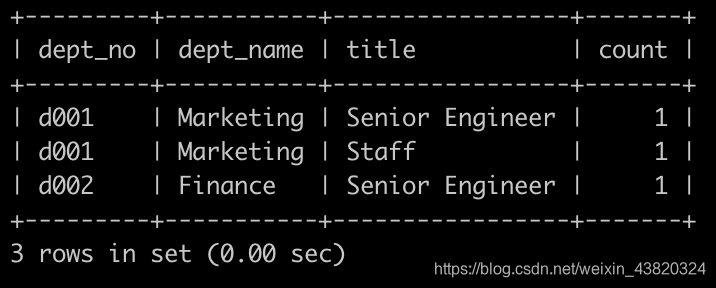
select de.dept_no, d.dept_name, title, count(de.emp_no) as count
from dept_emp de join titles t
on de.emp_no = t.emp_no
join departments d on de.dept_no = d.dept_no
group by de.dept_no, d.dept_name, title
order by de.dept_no;
牛客每天有很多人登录,请你统计一下牛客每个用户最近登录是哪一天。有一个登录(login)记录表,简况如下: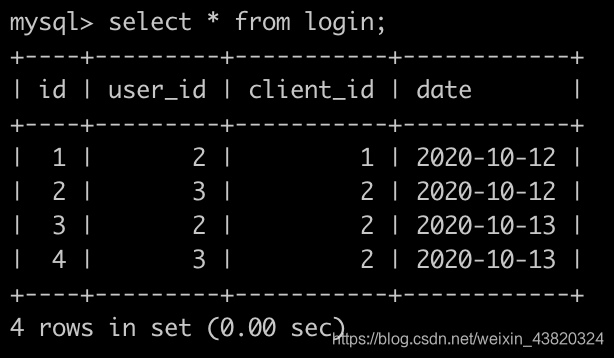
请你写出一个sql语句查询每个用户最近一天登录的日子,并且按照user_id升序排序,上面的例子查询结果如下: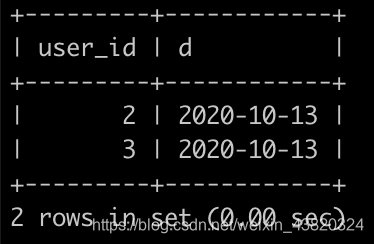
select user_id, max(date) as d
from login
group by user_id
order by user_id;
** 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。**
示例:
输入
[1,2,3,4,5,6,7],[3,2,4,1,6,5,7]
输出
{1,2,5,3,4,6,7}
JAVA
/**
* Definition for binary tree
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
public TreeNode reConstructBinaryTree(int [] pre,int [] in) {
// 树为空或长度不等则返回空值
if(pre.length == 0 || in.length == 0 || pre.length != in.length) return null;
/*
根据前序、中序的特点,还原二叉树构造:
1. 前序的第一个值为根节点;
2. 找到后序中的该值(1中的)所在位置,从而分出左右子树;
3. 分别记录左右子树的长度,根据各自的长度从前序中截取新的子前序;
4. 重复1~3.
*/
// 前序第一个值为根节点,创建节点
TreeNode node = new TreeNode(pre[0]);
// 循环,开始重建二叉树
for(int i = 0; i < in.length; i++) {
// 根据(子)前序的首个为根,寻找在(子)中序中的位置
if(pre[0] == in[i]) {
// 左子树所在前、中序的范围:pre[1, i]、in[0, i-1]
node.left = reConstructBinaryTree(subArray(pre, 1, i), subArray(in, 0, i-1));
// 右子树所在前、中序的范围:pre[i+1, pre.len-1]、in[i+1, in.len-1]
node.right = reConstructBinaryTree(subArray(pre, i+1, pre.length-1), subArray(in, i+1, in.length-1));
}
}
return node;
}
int[] subArray(int[] arr, int start, int end) {
// 左右子树的长度:end-start+1,之所以加1,因为有个根节点
int[] subTree = new int[end - start + 1];
for(int i=start; i <= end; i++) {
subTree[i-start] = arr[i];
}
return subTree;
}
}
Python
# -*- coding:utf-8 -*-
# class Tre
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
