社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
学习了 apache calcite,基本上把 apache calcite 的官网看了一遍,也写了几个小例子,现在该分析一下 Flink SQL 的执行过程了,其中关于 apache calcite 的部分不深究,因为 apache calcite 有些复杂,真的要了解清楚需要大量时间,本次还是聚焦 Flink.
以 SQL Query 为例 select a.* from a join b on a.id=b.id
sql query 入口方法
// sql query 入口方法
override def sqlQuery(query: String): Table = {
// 最后生成是 PlannerQueryOperation,也就是 Flink 算子
val operations = parser.parse(query)
if (operations.size != 1) throw new ValidationException(
"Unsupported SQL query! sqlQuery() only accepts a single SQL query.")
operations.get(0) match {
case op: QueryOperation if !op.isInstanceOf[ModifyOperation] =>
createTable(op)
case _ => throw new ValidationException(
"Unsupported SQL query! sqlQuery() only accepts a single SQL query of type " +
"SELECT, UNION, INTERSECT, EXCEPT, VALUES, and ORDER_BY.")
}
}
接下来具体看一下如何生成 PlannerQueryOperation
首先生成 SqlNode
@Override
public List<Operation> parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
// parse the sql query
//SQL 解析阶段,生成AST(抽象语法树),作用是SQL–>SqlNode
SqlNode parsed = parser.parse(statement);
Operation operation =
SqlToOperationConverter.convert(planner, catalogManager, parsed)
.orElseThrow(() -> new TableException("Unsupported query: " + statement));
return Collections.singletonList(operation);
}
然后将 SqlNode 转化为 RelNode
private PlannerQueryOperation toQueryOperation(FlinkPlannerImpl planner, SqlNode validated) {
// transform to a relational tree
//语义分析,生成逻辑计划,作用是SqlNode–>RelNode
RelRoot relational = planner.rel(validated);
return new PlannerQueryOperation(relational.project());
}
在转化 RelNode 的过程会,基于 Flink 定制的优化规则以及 calcite 自身的一些规则
/**
* Support all joins. Flink定制的优化rules
*/
private class FlinkLogicalJoinConverter
extends ConverterRule(
classOf[LogicalJoin],
Convention.NONE,
FlinkConventions.LOGICAL,
"FlinkLogicalJoinConverter") {
override def convert(rel: RelNode): RelNode = {
val join = rel.asInstanceOf[LogicalJoin]
val newLeft = RelOptRule.convert(join.getLeft, FlinkConventions.LOGICAL)
val newRight = RelOptRule.convert(join.getRight, FlinkConventions.LOGICAL)
FlinkLogicalJoin.create(newLeft, newRight, join.getCondition, join.getJoinType)
}
}
生成 物理执行计划,对应的都是 RelNode
class StreamExecJoinRule
extends RelOptRule(
......
// 基于Flink rules 将optimized LogicalPlan转成 Flink 物理执行计划
override def onMatch(call: RelOptRuleCall): Unit = {
val join: FlinkLogicalJoin = call.rel(0)
val left = join.getLeft
val right = join.getRight
def toHashTraitByColumns(
columns: util.Collection[_ <: Number],
inputTraitSets: RelTraitSet): RelTraitSet = {
val distribution = if (columns.isEmpty) {
FlinkRelDistribution.SINGLETON
} else {
FlinkRelDistribution.hash(columns)
}
inputTraitSets
.replace(FlinkConventions.STREAM_PHYSICAL)
.replace(distribution)
}
val joinInfo = join.analyzeCondition()
val (leftRequiredTrait, rightRequiredTrait) = (
toHashTraitByColumns(joinInfo.leftKeys, left.getTraitSet),
toHashTraitByColumns(joinInfo.rightKeys, right.getTraitSet))
val providedTraitSet = join.getTraitSet.replace(FlinkConventions.STREAM_PHYSICAL)
val newLeft: RelNode = RelOptRule.convert(left, leftRequiredTrait)
val newRight: RelNode = RelOptRule.convert(right, rightRequiredTrait)
// Stream physical RelNode,物理执行计划
val newJoin = new StreamExecJoin(
join.getCluster,
providedTraitSet,
newLeft,
newRight,
join.getCondition,
join.getJoinType)
call.transformTo(newJoin)
}
}
然后通过 translateToPlanInternal 生成 Flink 算子
class StreamExecJoin(
cluster: RelOptCluster,
traitSet: RelTraitSet,
leftRel: RelNode,
rightRel: RelNode,
condition: RexNode,
joinType: JoinRelType)
extends CommonPhysicalJoin(cluster, traitSet, leftRel, rightRel, condition, joinType)
with StreamPhysicalRel
with StreamExecNode[RowData] {
......
// 作用是生成 StreamOperator, 即Flink算子
override protected def translateToPlanInternal(
planner: StreamPlanner): Transformation[RowData] = {
val tableConfig = planner.getTableConfig
val returnType = InternalTypeInfo.of(FlinkTypeFactory.toLogicalRowType(getRowType))
val leftTransform = getInputNodes.get(0).translateToPlan(planner)
.asInstanceOf[Transformation[RowData]]
val rightTransform = getInputNodes.get(1).translateToPlan(planner)
.asInstanceOf[Transformation[RowData]]
val leftType = leftTransform.getOutputType.asInstanceOf[InternalTypeInfo[RowData]]
val rightType = rightTransform.getOutputType.asInstanceOf[InternalTypeInfo[RowData]]
val (leftJoinKey, rightJoinKey) =
JoinUtil.checkAndGetJoinKeys(keyPairs, getLeft, getRight, allowEmptyKey = true)
val leftSelect = KeySelectorUtil.getRowDataSelector(leftJoinKey, leftType)
val rightSelect = KeySelectorUtil.getRowDataSelector(rightJoinKey, rightType)
val leftInputSpec = analyzeJoinInput(left)
val rightInputSpec = analyzeJoinInput(right)
val generatedCondition = JoinUtil.generateConditionFunction(
tableConfig,
cluster.getRexBuilder,
getJoinInfo,
leftType.toRowType,
rightType.toRowType)
val minRetentionTime = tableConfig.getMinIdleStateRetentionTime
val operator = if (joinType == JoinRelType.ANTI || joinType == JoinRelType.SEMI) {
new StreamingSemiAntiJoinOperator(
joinType == JoinRelType.ANTI,
leftType,
rightType,
generatedCondition,
leftInputSpec,
rightInputSpec,
filterNulls,
minRetentionTime)
} else {
val leftIsOuter = joinType == JoinRelType.LEFT || joinType == JoinRelType.FULL
val rightIsOuter = joinType == JoinRelType.RIGHT || joinType == JoinRelType.FULL
new StreamingJoinOperator(
leftType,
rightType,
generatedCondition,
leftInputSpec,
rightInputSpec,
leftIsOuter,
rightIsOuter,
filterNulls,
minRetentionTime)
}
val ret = new TwoInputTransformation[RowData, RowData, RowData](
leftTransform,
rightTransform,
getRelDetailedDescription,
operator,
returnType,
leftTransform.getParallelism)
if (inputsContainSingleton()) {
ret.setParallelism(1)
ret.setMaxParallelism(1)
}
// set KeyType and Selector for state
ret.setStateKeySelectors(leftSelect, rightSelect)
ret.setStateKeyType(leftSelect.getProducedType)
ret
}
算子执行方式
public class StreamingJoinOperator extends AbstractStreamingJoinOperator {
private static final long serialVersionUID = -376944622236540545L;
// whether left side is outer side, e.g. left is outer but right is not when LEFT OUTER JOIN
private final boolean leftIsOuter;
// whether right side is outer side, e.g. right is outer but left is not when RIGHT OUTER JOIN
private final boolean rightIsOuter;
private transient JoinedRowData outRow;
private transient RowData leftNullRow;
private transient RowData rightNullRow;
// left join state
private transient JoinRecordStateView leftRecordStateView;
// right join state
private transient JoinRecordStateView rightRecordStateView;
public StreamingJoinOperator(
InternalTypeInfo<RowData> leftType,
InternalTypeInfo<RowData> rightType,
GeneratedJoinCondition generatedJoinCondition,
JoinInputSideSpec leftInputSideSpec,
JoinInputSideSpec rightInputSideSpec,
boolean leftIsOuter,
boolean rightIsOuter,
boolean[] filterNullKeys,
long stateRetentionTime) {
......
@Override
public void processElement1(StreamRecord<RowData> element) throws Exception {
processElement(element.getValue(), leftRecordStateView, rightRecordStateView, true);
}
@Override
public void processElement2(StreamRecord<RowData> element) throws Exception {
processElement(element.getValue(), rightRecordStateView, leftRecordStateView, false);
}
也是 join 最终执行的地方
sql 解析,生成抽象语法树,由SQL—> SqlNode,然后进行语义分析,生成 Logical Plan, SqlNode---->RelNode 未经过优化的 RelNode ----> 应用 Flink 定制的一些优化 rule,优化 Logical Plan
----> 转化为物理执行计划 Stream physical RelNode -----> 生成 StreamOperator Flink 算子
----> 算子执行
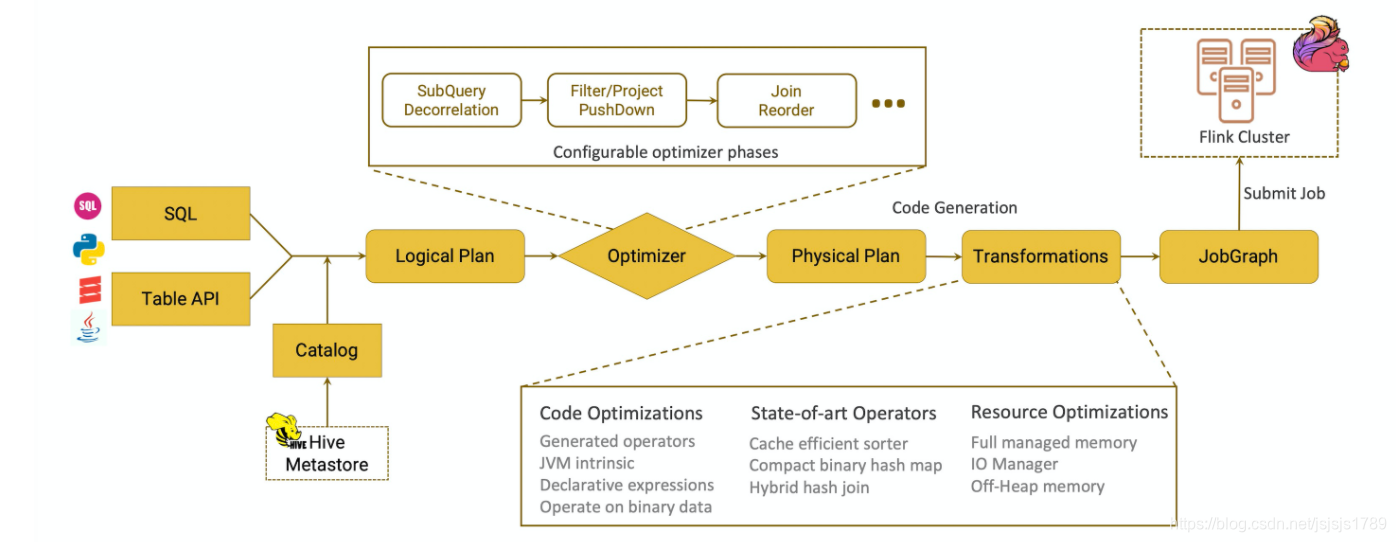
本文的主要目的是在大方向上明白 Flink SQL 的解析过程,具体细节读者感兴趣可以自行深入研究
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
