社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本节任务是在上一节任务《Java文本处理7-查询文本中单个汉字的信息熵》的基础上统计文本中每一个汉字的信息熵,关于信息熵计算的方法在上一节任务中已经阐述过了,本节的第一个程序是将结果打印出来,而第二个程序是将结果保存到一个指定文本中。
统计指定文本中每一个汉字的信息熵,然后将统计结果打印出来。
关于具体思路使用到了上两节内容的知识,具体如下:
(1)首先需要使用InputStreamReader类和BufferedReader类实现文本的读取,由于我使用的《西游记》为utf-8编码,所以还需要指定编码格式为utf-8;
(2)然后需要定义一个空的字符串变量,在对文本逐行读出后将读出的内容追加到该空字符串后;
(3)逐行读出文档,然后使用for循环对该行中的每一个字符进行遍历,使用toString()方法得到每一个字符,再使用if语句和matches()方法检测字符是否为汉字,若匹配则对指定的变量进行自增,求出总的汉字数;
(4)需要使用TreeMap方法来进行字频的统计,需要使用public static构造一个静态方法,由于是对字频进行统计,所以还需要确保字符为汉字才能进行统计,故还需要使用Matcher类进行字符串的匹配操作,若该字符为汉字则进行统计;
(5)在主函数中调用构造出来的TreeMap方法,并进行降序排序,再使用信息熵的计算公式将该汉字的信息上计算出来,最后使用Collections.sort()构造排序比较器再将每一个汉字的key值、value值和熵值打印出来。
程序保存为shang2.java,代码如下:
import java.io.*;//导入java.io包中的所有类
import java.util.*;//导入java.util包中的所有类
import java.util.Map.Entry;//导入java.util.Map包中的Entry类
public class shang2 {//类名
public static void main(String[] args) {//程序主函数
try {//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
Scanner s = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
System.out.println("请输入想要打开的文本文档:");//输入提示信息
String a = s.nextLine();//定义字符串变量,并赋值为用户输入的信息
//创建类进行文件的读取,并指定编码格式为utf-8
InputStreamReader read = new InputStreamReader(new FileInputStream(a),"utf-8");
BufferedReader in = new BufferedReader(read);//可用于读取指定文件
StringBuffer b = new StringBuffer();//定义一个字符串变量b,便于后续进行内容追加的操作
String str = null;//定义一个字符串类型变量str
String d=null;//定义一个字符串类型变量d
double e = 0;//定义一个double型变量,用于统计总汉字数
int i = 0;//定义一个整型变量
while((str = in.readLine()) != null) {//readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
b.append(str);//将该行内容追加到字符串b的后面
for (int j = 0; j < str.length(); j++) {//for循环的条件,当j小于该行长度时就一直循环并自增
d = Character.toString(str.charAt(j));//返回一个字符串对象
if (d.matches("[\u4e00-\u9fa5]")) {//if语句的条件,判断是否为汉字
e++;//若为汉字则e自增
}
}
}
TreeMap<Character,Integer>tm =Pross(b.toString());//调用TreeMap函数
System.out.println("汉字统计结果:");//输出结果
List<Map.Entry<Character,Integer>> list = new ArrayList<Map.Entry<Character,Integer>>(tm.entrySet());//将map转换为list便于进行排序
//构造一个排序比较器
Collections.sort (list,new Comparator<Map.Entry<Character,Integer>>() {//使用Collections.sort()方法对这个list进行排序
public int compare(Entry<Character,Integer> o1,Entry<Character,Integer> o2) {
//实现降序排序
int z = o2.getValue()-o1.getValue();
return z;
}
});
for(Map.Entry<Character,Integer> mapping:list) {//遍历list
int f = mapping.getValue();
double p = (double)f/e;//定义一个double型变量,计算该汉字在文章中的出现概率
double H = -p * (Math.log(p) / Math.log(2));//定义一个double型变量,计算该汉字的信息熵
System.out.println(mapping.getKey()+":"+mapping.getValue()+" 信息熵为:"+H+"比特/符号"); //输出降序排序的结果
}
Iterator<Integer>it = tm.values().iterator();//获取tm中values值并迭代
while(it.hasNext()) {//检查序列中是否含有元素,若有则为true
Integer j=(Integer)it.next();//定义变量获取元素
i+=j;//迭代求总字符数
}
in.close();//关闭流
System.out.println("总汉字数为"+i);//输出总的汉字数
} catch (IOException e) {//当try代码块有异常时转到catch代码块
e.printStackTrace();//printStackTrace()方法是打印异常信息在程序中出错的位置及原因
}
}
public static TreeMap<Character,Integer>Pross(String str) {//构造TreeMap统计方法
String d = null;//定义一个字符串类型变量
char[] charArray = str.toCharArray();//将字符串转换为字符数组
TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>();//定义一个TreeMap集合
for(int x = 0;x < charArray.length;x++) {//循环遍历字符数组
d=Character.toString(charArray[x]);//返回一个字符串对象
if (d.matches("[\u4e00-\u9fa5]")) {//if语句的条件,判断是否为汉字
if(!tm.containsKey(charArray[x])) {//if语句的条件,判断该汉字是否在tem中
tm.put(charArray[x], 1);//若该汉字不在tem中则初始化其value值为1
} else {//若该汉字在tem中
int count = tm.get(charArray[x])+1;//其出现次数增加1
tm.put(charArray[x],count);//若汉字在tem中则其value值为count
}
}
}
return tm;//返回
}
}
所有文件均保存在路径D:demo6下,在命令行中对程序进行编译,然后运行程序读取路径下的txt文档,结果如下: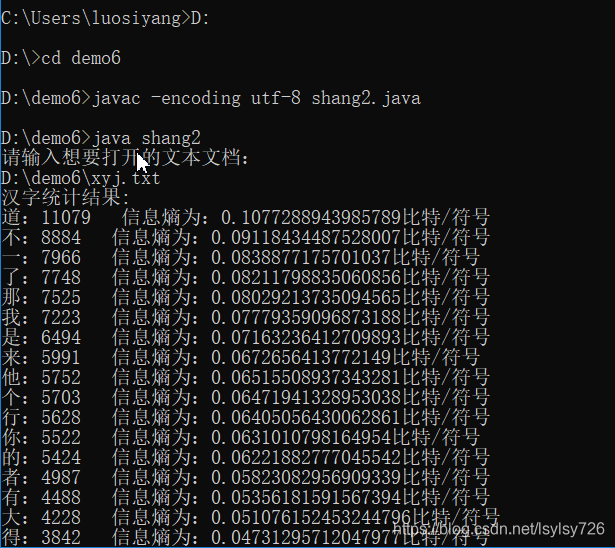
从图中可以看出汉字的出现次数及其信息熵已经打印到了黑屏幕上。
统计指定文本中每一个汉字的信息熵统计出来,并将结果输出到一个指定的文本文档中(将任务1的输出内容保存到指定文本文档中)。
(1)首先在任务1的基础上加上一个Scanner类,用于读取用户想要存入的文档路径和文档名;
(2)然后使用PrintStream类直接打印输出流,将内容保存到指定路径即可;
程序保存为shang3.java,代码如下:
import java.io.*;//导入java.io包中的所有类
import java.util.*;//导入java.util包中的所有类
import java.util.Map.Entry;//导入java.util.Map包中的Entry类
public class shang3 {//类名
public static void main(String[] args) {//程序主函数
try {//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
Scanner s1 = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
Scanner s2 = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
System.out.println("请输入想要打开的文本文档:");//输入提示信息
String a1 = s1.nextLine();//定义字符串变量,并赋值为用户输入的信息
System.out.println("请输入想要写入内容的文本文档:");//输入提示信息
String a2 = s2.nextLine();//定义字符串变量,并赋值为用户输入的信息
File file=new File(a2);//用命令行参数直接写入待写入文件
if(!file.exists()) {//if语句的条件,若指定路径下该文件不存在
file.createNewFile();//则在指定路径下新建该文件
}
//创建类进行文件的读取,并指定编码格式为utf-8
InputStreamReader read = new InputStreamReader(new FileInputStream(a1),"utf-8");
BufferedReader in = new BufferedReader(read);//可用于读取指定文件
StringBuffer b = new StringBuffer();//定义一个字符串变量b,便于后续进行内容追加的操作
String str = null;//定义一个字符串类型变量str
String d=null;//定义一个字符串类型变量d
double e = 0;//定义一个double型变量,用于统计总汉字数
int i = 0;//定义一个整型变量,用于统计字符串的出现次数
while((str = in.readLine()) != null) {//readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
b.append(str);//将该行内容追加到字符串b的后面
for (int j = 0; j < str.length(); j++) {//for循环的条件,当j小于该行长度时就一直循环并自增
d = Character.toString(str.charAt(j));//返回一个字符串对象
if (d.matches("[\u4e00-\u9fa5]")) {//if语句的条件,判断是否为汉字
e++;//若为汉字则e自增
}
}
}
TreeMap<Character,Integer>tm =Pross(b.toString());//调用TreeMap函数
PrintStream out = new PrintStream(file);//打印输出流,并指定保存路径
System.setOut(out);//改变输出流并将内容保存到指定路径
System.out.println("汉字统计结果:");//输出结果
List<Map.Entry<Character,Integer>> list = new ArrayList<Map.Entry<Character,Integer>>(tm.entrySet());//将map转换为list便于进行排序
//构造一个排序比较器
Collections.sort (list,new Comparator<Map.Entry<Character,Integer>>() {//使用Collections.sort()方法对这个list进行排序
public int compare(Entry<Character,Integer> o1,Entry<Character,Integer> o2) {
//实现降序排序
int z = o2.getValue()-o1.getValue();
return z;
}
});
for(Map.Entry<Character,Integer> mapping:list) {//遍历list
int f = mapping.getValue();
double p = (double)f/e;//定义一个double型变量,计算该汉字在文章中的出现概率
double H = -p * (Math.log(p) / Math.log(2));//定义一个double型变量,计算该汉字的信息熵
System.out.println(mapping.getKey()+":"+mapping.getValue()+" 信息熵为:"+H+"比特/符号"); //输出降序排序的结果
}
Iterator<Integer>it = tm.values().iterator();//获取tm中values值并迭代
while(it.hasNext()) {//检查序列中是否含有元素,若有则为true
Integer j=(Integer)it.next();//定义变量获取元素
i+=j;//迭代求总字符数
}
in.close();//关闭流
System.out.println("总汉字数为"+i);//输出总的汉字数
} catch (IOException e) {//当try代码块有异常时转到catch代码块
e.printStackTrace();//printStackTrace()方法是打印异常信息在程序中出错的位置及原因
}
}
public static TreeMap<Character,Integer>Pross(String str) {//构造TreeMap统计方法
String d = null;//定义一个字符串类型变量
char[] charArray = str.toCharArray();//将字符串转换为字符数组
TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>();//定义一个TreeMap集合
for(int x = 0;x < charArray.length;x++) {//循环遍历字符数组
d=Character.toString(charArray[x]);//返回一个字符串对象
if (d.matches("[\u4e00-\u9fa5]")) {//if语句的条件,判断是否为汉字
if(!tm.containsKey(charArray[x])) {//if语句的条件,判断该汉字是否在tem中
tm.put(charArray[x], 1);//若该汉字不在tem中则初始化其value值为1
} else {//若该汉字在tem中
int count = tm.get(charArray[x])+1;//其出现次数增加1
tm.put(charArray[x],count);//若汉字在tem中则其value值为count
}
}
}
return tm;//返回
}
}
(1)所有文件均保存在路径D:demo6下,在命令行中对程序进行编译,然后读取路径下的《西游记》文档xyj.txt,然后将内容保存到该路径下的xieru3.txt文档中,命令行操作如下: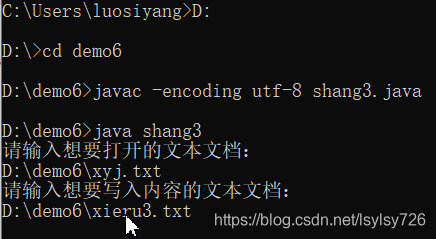
(2)打开路径D:demo6下的xieru3.txt文档,显示如下: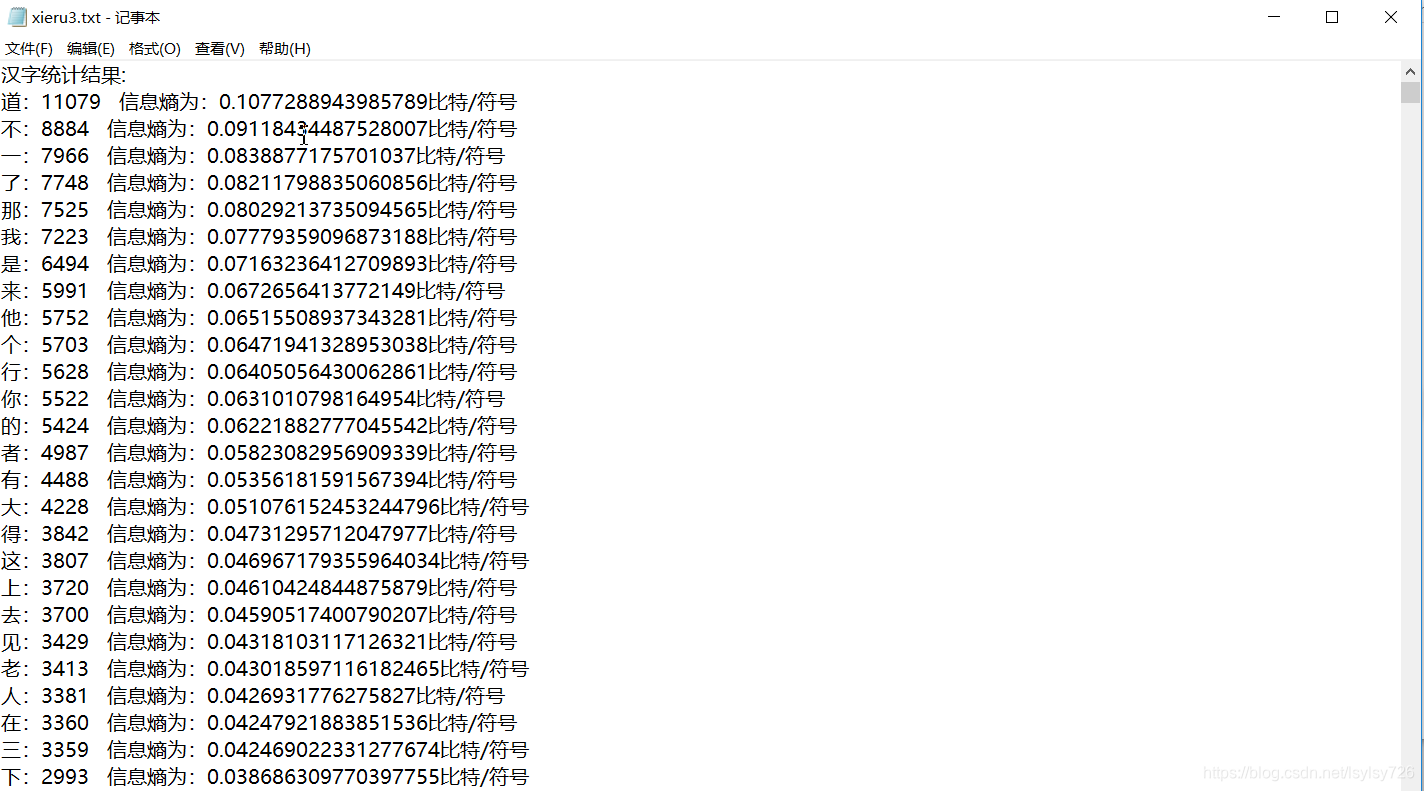
此时已经将任务1中打印到黑屏幕上的内容写入了一个指定的文本文档中。
将本节任务的统计结果与之前任务的结果相对比可以发现结果的一致性,如本节中道字的字频数为11079次,信息熵为0.1077288943985789比特/符号,使用上一节的程序计算结果如下: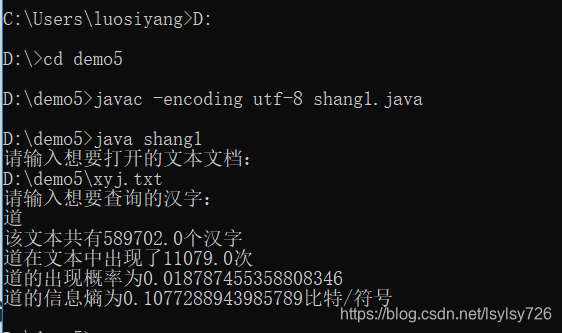
由此也提升了本节任务所写程序的准确性。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
