社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据库:MYSQL
一、概念:存储数据的仓库
二、分类:关系型数据库、非关系型数据库
1.关系型数据库:先有班级,再有学员
2.缓存数据库
三、库:
1.查看当前服务下的所有数据库
show databases;
2.创建数据库
create database DATABASE_NAME;
3.进入数据库
use DATABASE_NAME;
4.查看当前库中的数据表
show tables;
5.创建数据表
create table TABLE_NAME(
FIELD_NAME DATA_TYPE(n) SPECIAL_CONSTARAINT,
....
)
a.新增数据
insert into TABLE_NAME(FILED_NAME,....) value(value,....);
b.删除数据
delete from TABLE_NAME where CONDITION;
c.修改数据
update TABLE_NAME set FIELD_NAME1=VALUE1,FIELD_NAME2=VALUE2...where CONDITION
四、操作:
1.数据类型
mysql中数据类型后type(n):n表示允许的最大长度
2.字符串:
char(n) 固定长度 char(4) 张三 张三_ _(空格)
varchar(n) 动态长度 varchar(4) 张三 张三
固定长度举例:性别:一个汉字:男/女 char(1)
动态长度举例:姓名:2~4个汉字: varchar(4)
3.小数:
decimal:m代表最大长度,n代表精度(小数的长度)
decimal(8,2) 123456.18
4.日期:
date:年月日 datetime:年月日时分秒
timestamp<=>datetime:自动提供默认值
5.数据库中没有双引号,只有单引号:表示字符串:‘TB06’
日期用字符串表示‘2020-1-18’
五、SPECIAL_CONSTARAINT(特殊约束)表设计师表字段约束
1.符号:数值正负:数值默认有正负,unsigned:无符号(只有整数)
2.自增列整数:auto_increment 默认从1开始
3.非空:not null
4.默认值:default value
5.唯一键:unique key
6.主键:primary key
7.外键:foreign key


数据操作注意事项:
1.在实际开发中禁用删除操作,一般采用状态机制以修改操作代替删除,以确保数据的完整性。
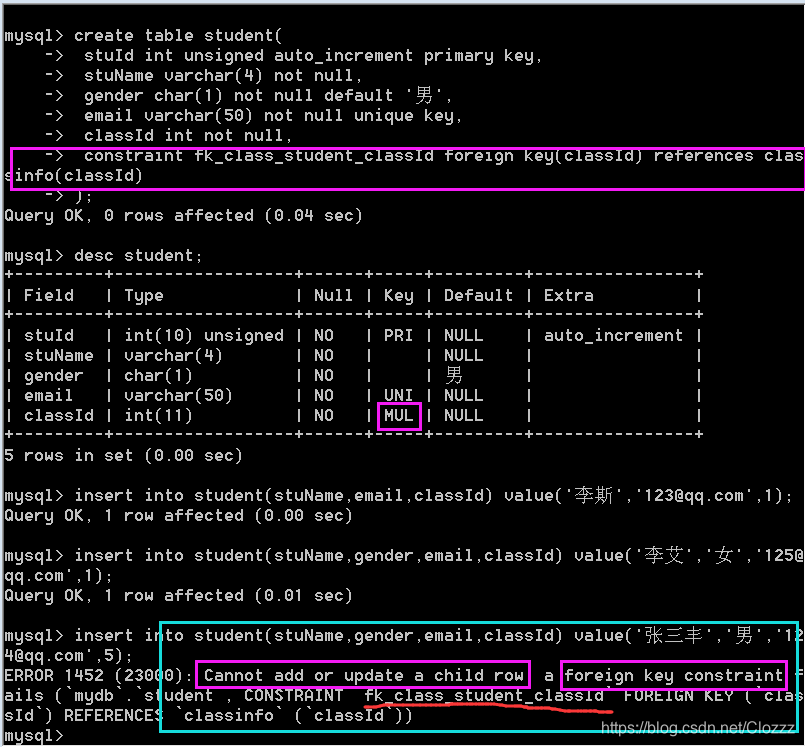
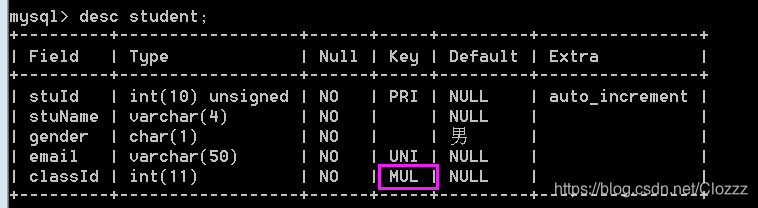
2.关系型数据库,一般每张表都需要设置一个无意义的自增列作为主键,主键为不可以重复,不可以为null的字段。




1.删除/修改/查询:CONDITION
(1)一般来说:删除和修改必须带条件,且条件是主键或唯一键
(2)查询条件非常丰富:
①select…where FIELD_NAME=VALUE
1)逻辑运算符:
②
select... where FIELD_NAME is [not] null; 筛选
③
select... where NUMBER_FILED between..and..;
注意:between(>= …and… <=) 区间
④
select...where FILED_NAME in (...) 列举
⑤
select...where FIELD_NAME like’...’ 模糊查
1)通配符
a.% 通配任意长度任意内容
b._ 通配一个长度任意内容
2.查询
(1)基础查询标准语法:
select
field1,[as] alias......fieldn 字段列表,*表示所有字段
from 别名主要用于合成字段或函数字段
table
where
(2)排序:
order by MAIN_FIELD ASC(升序)/DESC(降序),sub_FIELD ASC/DESC,…
注意:1.如果需要对查询结果排序,则排序一定是最后一句
2.多字段排序,左侧为主,右侧为辅,首先按照左侧的字段排序, 如果左侧字段出现同值,才可能参考右侧字段进行排序
3.如果ASC/DESC缺省,默认为升序ASC
(3)分页:
当前页面为pageNo,一页显示的数据量为pageSize
select …limit (pageNo-1)*pageSize,pageSize
(4)分组:
select
[MAIN_FIELD SUB_FIELD,....],聚合函数列表
....
group by
MAIN_FIELD SUB_FIELD,....
having
CONDITION
注意:1.只有在group by之后出现的字段(分组字段),才可以出现在select之后的字段列表中。
2.先根据主字段分组,在根据辅字段分组。
3.分组聚合的结果筛选,必须放在group by之后,由having关键 字引出。
(5)复杂查询
①子查询:嵌套查询
select FILED1.....,FIELDN from TABLE where CONDITION
1)字段列表中可以出现子查询
2)表格部分可以出现子查询
3)条件部分可以子查询
②合并查询
select
T1.FILED1.....,S.FIELDN
from
TABLE1,TABLE2,Subquery s...
where
T1.field=T2.field
and
T1.field=subquery
....
③连接查询
1)内连接:inner join…on… 交集(两张表都有的数据)
2)外连接
a.左外
select... from A left [outer] join B on....
A表为主表:A表中的数据全部展示,若B表中无关联数据则以null填充
b.右外
select... from A right [outer] join B on....
B表为主表:B表中的数据全部展示,若A表中无关联数据则以null填充
3.函数
(1)字符串函数
①获取字符串的字节的长度:length(string)
②获取字符串字符的长度:char_length(string)
③拼接字符串:concat(‘…’,’…’,’…’)
④转小写/大写:lower(string)/upper(string)
⑤左右截取字符串:left(string ,length)/right(string ,length)
⑥指定位置截取指定长度:mid/substring(string,pos,length)
⑦去除字符串两端的空格:trim(string)
⑧字符串替换:repalce(string,src,dest)
(2)日期函数
①获取系统当前日期:cudate()
②获取系统当前时间:curtime()
③获取unix时间戳:unix_timestamp()
④获取指定日期的年/月/日:year/month/dayofmonth(date)
⑤获取指定日期是星期编号:dayofweek(date)
获取指定日期的星期索引:weekday(date)
⑥获取指定日期是该年的第多少天:dayofyear(date)
⑦在指定日期的指定部分加值后的日期:adddate(date,interval n format)
select adddate(‘2020-1-30’,interval 1 day);=>2020-1-31
subdate(date,interval n format)
select subdate(‘2020-1-30’,interval 1 day);=>2020-1-29
⑧ 获取两个日期之间的天数差:datediff(datebig,datesmall)
(3)数学函数
①绝对值:abs(num)
②向上取整:ceil(decimal(小数))
③向下取整:floor(decimal(小数))
(4)聚合函数
①计数:count(1/*/FIELD_NAME)
②求和:sum(num)
③均值:avg(num)
④最大值:max(num)
⑤最小值:min(num)
SQL优化
1.select字段列表:避免用*,写字段列表
2.select…from表列表:一般把数据量大的表前置
3.count(1)行/count(*)匹配所有字段/count(FILED)只看FIELD字段,如果为空则为0,否则为1
4.子查询的效率比较低
四、存储引擎
InnoDB:事务型的存储引擎,确保数据的安全性、一致性和稳定性
Memory:提取速度
MyIsam:…
(1)默认:InnoDB (insert/delete/update)
(2)查看:show engines:查看mysql支持的所有存储引擎
(3)查看某表的存储引擎:show table status from DB_NAME where name=’TABLE_NAME’
(4)设置:create table TABLE_NAME (…)engine=’ENGINE_NAME’
五、索引
(1)概念:为了方便检索,给数据表外挂一个数据结构,以存储数据的地址 没有索引的支持,检索数据的过程就是逐行扫描
(2)主键索引是聚焦索引么?
聚焦索引:决定表数据行物理存储顺序的索引
InnoDB存储引擎下:主键就是聚焦索引
(3)操作
① 添加索引:
create IX_TYPE index IX_NAME on TABLE_NAME(FIELD_NAME[,FIELD_NAME,…]);
索引类型:聚族索引,唯一索引unique,全文,普通索引[缺省]…
字段数量:组合索引[是一种普通索引]
② 删除索引:drop index INDEX_NAME on TABLE_NAME;
③ 查看索引:show index from TABLE_NAME;
六、底层数据存储结构:BTREE
七、InnoDB锁
(1)优势
①好处:安全(避免脏读…)
②劣势:检索效率低,并发性能低
(2)概念
①S:共享锁:面向读开发,面向写封闭
②X:排他锁:你在用时,别人既不能读,也不能写
(3)mysql innodb锁处理
①select:不上锁
②insert/delete/update:排它锁
八、读写分离
(1)读的数据放在一个数据库内:
一般存放在高速缓存数据库中(NoSql),比如:redis
(2)写的数据放在另一个数据库内
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
