社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
目录:
一、Python介绍
二、Python发展史
三、Python安装
四、语法结构:语句块缩进、注释、 文档字符串
五、Python 入门:
第一句Python代码、python内部执行过程、字符编码、模块初识、pyc文件、变量、流程控制和循环(if语句、条件表达式 (三元运算符)、while 循环、for循环、else语句、break语句 、continue语句 、pass语句 )
六、迭代
七、列表解析
八、生成器表达式
Python,英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
根据2017 TIOBE排行榜,Python已经位列第四。

Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
目前Python主要应用领域:
Python在一些公司的应用:
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言。
1、编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
1.先看优点
2.再看缺点:
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码
以上除PyPy之外,其他的Python的对应关系和执行流程如下:

Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。

1、下载安装包 https://www.python.org/downloads/ 2、安装 默认安装路径:C:python27 3、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 如:原来的值;C:python27,切记前面有分号
""" Clear Window Extension Version: 0.2 Author: Roger D. Serwy roger.serwy@gmail.com Date: 2009-06-14 It provides "Clear Shell Window" under "Options" with ability to undo. Add these lines to config-extensions.def [ClearWindow] enable=1 enable_editor=0 enable_shell=1 [ClearWindow_cfgBindings] clear-window=<Control-Key-l> """ class ClearWindow: menudefs = [ ('options', [None, ('Clear Shell Window', '<<clear-window>>'), ]),] def __init__(self, editwin): self.editwin = editwin self.text = self.editwin.text self.text.bind("<<clear-window>>", self.clear_window2) self.text.bind("<<undo>>", self.undo_event) # add="+" doesn't work def undo_event(self, event): text = self.text text.mark_set("iomark2", "iomark") text.mark_set("insert2", "insert") self.editwin.undo.undo_event(event) # fix iomark and insert text.mark_set("iomark", "iomark2") text.mark_set("insert", "insert2") text.mark_unset("iomark2") text.mark_unset("insert2") def clear_window2(self, event): # Alternative method # work around the ModifiedUndoDelegator text = self.text text.undo_block_start() text.mark_set("iomark2", "iomark") text.mark_set("iomark", 1.0) text.delete(1.0, "iomark2 linestart") text.mark_set("iomark", "iomark2") text.mark_unset("iomark2") text.undo_block_stop() if self.text.compare('insert', '<', 'iomark'): self.text.mark_set('insert', 'end-1c') self.editwin.set_line_and_column() def clear_window(self, event): # remove undo delegator undo = self.editwin.undo self.editwin.per.removefilter(undo) # clear the window, but preserve current command self.text.delete(1.0, "iomark linestart") if self.text.compare('insert', '<', 'iomark'): self.text.mark_set('insert', 'end-1c') self.editwin.set_line_and_column() # restore undo delegator self.editwin.per.insertfilter(undo)
[ClearWindow] enable=1 enable_editor=0 enable_shell=1 [ClearWindow_cfgBindings] clear-window=<Control-Key-l>
C:Userszgy>python -V Python 2.7.14
2.安装readline模块
C:Userszgy>python -m pip install pyreadline Collecting pyreadline Downloading pyreadline-2.1.zip (109kB) 100% |████████████████████████████████| 112kB 46kB/s Installing collected packages: pyreadline Running setup.py install for pyreadline ... done Successfully installed pyreadline-2.1 C:Userszgy>
完成后在Python27Libsite-packages目录下生成两个目录:pyreadline和pyreadline-2.1-py2.7.egg-info。
import sys
import readline
import rlcompleter
import atexit
import os
# tab completion
readline.parse_and_bind('tab: complete')
# history file
histfile = os.path.join(os.environ['HOMEPATH'], '.pythonhistory')
try:
readline.read_history_file(histfile)
except IOError:
pass
atexit.register(readline.write_history_file, histfile)
del os, histfile, readline, rlcompleter 注:win 下写成 HOMEPATH linux 下HOME 否则会报错
import sys import readline import rlcompleter import atexit import os # tab completion readline.parse_and_bind('tab: complete') # history file histfile = os.path.join(os.environ['HOMEPATH'], '.pythonhistory') try: readline.read_history_file(histfile) except IOError: pass atexit.register(readline.write_history_file, histfile) del os, histfile, readline, rlcompleter
注:win 下写成 HOMEPATH linux 下HOME 否则会报错
查看默认Python版本 python -V 1、安装gcc,用于编译Python源码 yum install gcc 2、下载源码包,https://www.python.org/ftp/python/ 3、解压并进入源码文件 4、编译安装 ./configure make all make install 5、查看版本 /usr/local/bin/python2.7 -V 6、修改默认Python版本 mv /usr/bin/python /usr/bin/python2.6 ln -s /usr/local/bin/python2.7 /usr/bin/python 7、防止yum执行异常,修改yum使用的Python版本 vi /usr/bin/yum 将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6 备注:软链接指向 Python2.7 版本后, yum 将不能正常工作,因为 yum 是 2.6 写的不兼容 2.7, 所以 需要指定下 yum 命令里默认 Python 版本为原来的 2.6.6 版本 。
pycharm设置文件头注释:
File->settings->Editor->File and Code Templates->Python Script
#!/usr/bin/env python
#coding:utf-8
__author__ = '$USER'
# @file: ${NAME}.py
# @time: ${DATE} ${TIME}
vim ~/.vimrc set ai set tabstop=4
#!/usr/bin/env python """star module just a sample module. only include one function.""" def pstar(): "do not accept args. Used to print 50 stars" print '*' * 50
导入模块后,就可以查看到在线文档:
[root@localhost bin]# python >>> import star >>> help(star) NAME star - star module FILE /root/bin/star.py DESCRIPTION just a sample module. only include one function. FUNCTIONS pstar() do not accept args. Used to print 50 stars
1.在linux下创建一个文件叫hello.py,输入一下内容:
print "hello,world"
然后执行命令:python hello.py ,输出
Hello World!

1.指定解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python print "hello,world"
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill) ,ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
1、关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
1#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
2、补充知识:
Python文件编码声明:
# -*- coding: utf-8 -*-是用来指定文件编码的
1、如果没有此文件编码类型声明,则Python默认以ASCII编码去处理
2、文件编码类型声明必须放在Python文件的第一行或第二行,即如果把文件编码类型声明放在其他行,则无法被识别
3、编码声明所支持的格式有3种:
3.1 带等号的
#coding=<encoding name>
3.2 带冒号的
#!/usr/bin/env python
#-*- coding:<encoding name> -*-
3.3 vim的配置
#!/usr/bin/env python
# vim : set fileencoding=<encoding name>
4.声明的格式的语法只要是符合正则表达式就可以
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import sys 5 6 print sys.argv
#!/usr/bin/env python
import sys
import readline
import rlcompleter
import atexit
import os
readline.parse_and_bind('tab: complete')
histfile = os.path.join(os.environ['HOME'], '.pythonhistory')
try:
readline.read_history_file(histfile)
except IOError:
pass
atexit.register(readline.write_history_file,histfile)
del os, histfile, readline, rlcompleter
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码
1、变量定义的规则:
1.变量名只能是 字母、数字或下划线的任意组合
2、变量名的第一个字符不能是数字
3.大小写敏感
4.以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
5.关键字列表和iskeyword()函数都放入了keyword模块以便查阅
通过导入import keyword可以查看关键字:

判断是否为关键字,是的话返回True,否则返回False

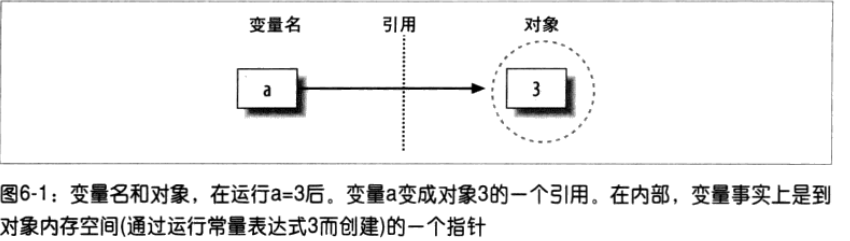
在Python中,从变量到对象的连接称作引用。也就是说,引用是一种关系,以内存中的指针的形式实现
一旦变量被使用(也就是说被引用),Python会自动跟随这个变量到对象的连接
1、变量是一个系统表的元素,拥有指向对象的连接的空间
2、对象是分配的一块内存,有足够的空间去表示它们所代表的值
3、引用是自动形成的从变量到对象的指针
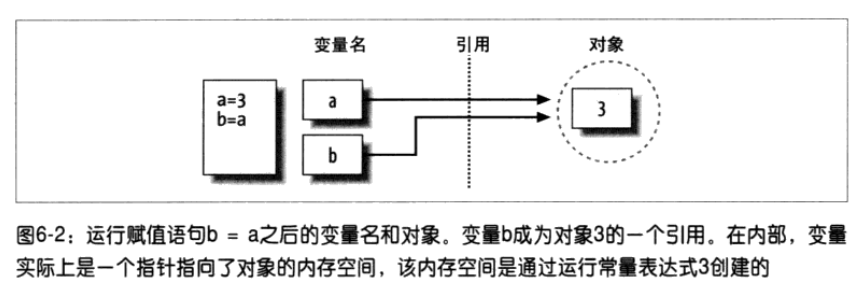
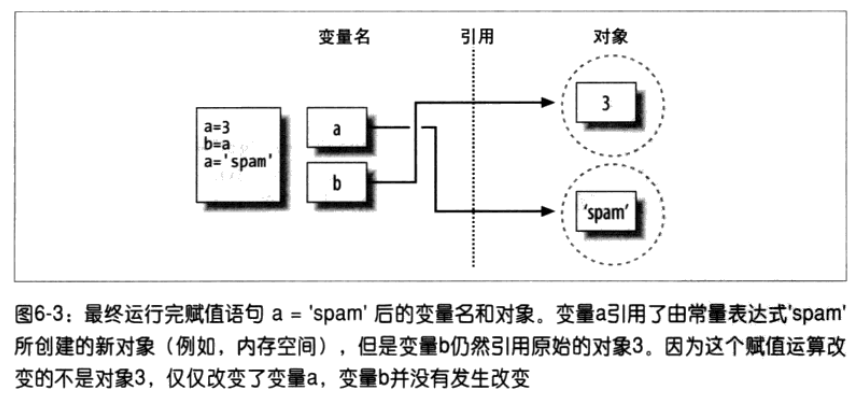
2、声明变量
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 name = "hello"
3、变量赋值
1.变量的类型和值在赋值那一刻被初始化
2. 变量赋值通过等号来执行
3 python也支持增量赋值
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name1 = "hello"
name2 = "world"
4、赋值运算符
1.python语言中,等号=是主要的赋值运算符
2.赋值并不是直接将一个值赋给一个变量
3.在python中,对象是通过引用传递的。在赋值时,不管这个对象是新创建的,还是一个已经存在的,
都是将该对象的引用(并不是值)赋值给变量
4.python也支持链式多重赋值
下面是几种赋值方式的例子:
链式赋值
1 | >>> x = y = 1 |
增量赋值
从python 2.0开始,等号可以和一个算术运算符组合在一起,
将计算结果重新赋值给左边的变量,这被称为增量赋值
>>> x += 1多元赋值
1、另一种将多个变量同时赋值的方法称为多元赋值,采用这种方式赋值时,等号两边的对象都是元组
>>> x, y, z = 1, 2, 'a string' >>> print 'x=%d, y=%d' % (x, y) x=1, y=2 >>> x, y = y, x >>> print 'x=%d, y=%d' % (x, y) x=2, y=1
5、使用raw_input()函数读取用户输入数据
#!/usr/bin/env python # -*- coding: utf-8 -*- # 将用户输入的内容赋值给 name 变量 name = raw_input("请输入用户名:") # 打印输入的内容 print name
输出结果:
请输入用户名:bob
bob 4.input()函数与raw_input()类似,但其接受的输入必须是表达式
5.input()接受表达式输入,并把表达式的结果赋值给等号左边的变量
python3版本中
没有raw_input()函数,只有input()
并且 python3中的input与python2中的raw_input()功能一样
>>> name = input("My name is : ") My name is : xiaoming Traceback (most recent call last): File "<pyshell#0>", line 1, in <module> name = input("My name is : ") File "<string>", line 1, in <module> NameError: name 'xiaoming' is not defined >>> >>> name = input("My name is : ") My name is : "xiaoming" >>> print name xiaoming >>>
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
