社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
PostgreSQL , 数据库特性 , 数据库应用场景分析 , 数据库选型
数据库对于一家企业来说,相比其他基础组件占据比较核心的位置。
有很多企业由于最初数据库选型问题,导致一错再错,甚至还有为此付出沉痛代价的。
数据库的选型一定要慎重,但是这么多数据库,该如何选择呢?
我前段时间写过一篇关于数据库选型的文章,可以参考如下
另外,PostgreSQL这个数据库这些年的发展非常的迅猛,虽然国内还跟不上国外的节奏,但是相信国人逐渐会融合进去。
所以我专门针对PostgreSQL提炼了它的一些应用场景(普通的应用场景就不举例了),希望对你的选型可以起到一定的参考作用。
在一些前端的人机交互页面中,经常会有很多选择框,让用户进行选择,这些选择框可能对应的是数据库表中的不同字段。
这种画面经常出现在ERP,电商,网站,手机APP等场景中。
对于开发人员来说是一件很头疼的事情,因为不知道该对哪些字段创建索引,或者干脆对所有字段都建立索引,给数据库带来较大的性能和维护的问题。
PostgreSQL中有两个技术(gin, bloom索引),可以完美的解决这类业务场景的问题。
《宝剑赠英雄 - 任意组合字段等效查询, 探探PostgreSQL多列展开式B树》
《PostgreSQL 9.6 黑科技 bloom 算法索引,一个索引支撑任意列组合查询》
有些场景,经常要对值进行范围的比对。比如
物联网,对传感器上传的值,进行范围比对。
智能DNS,需要对来源IP进行判断,并找出其落在哪个IP地址段内。
金融行业,经常要设置一些指标范围,时刻判断指数是否落在某个区间,当一些指数落在某个范围区间时,触发下一步的操作(比如买入或卖出)。
传统的两个字段+复合B树的索引,效率低下,通常8核的机器只能达到3000多的QPS。
PostgreSQL通过(range类型和gist,sp-gist索引),可以将效率提升20多备,8核的机器可以达到8万的QPS。
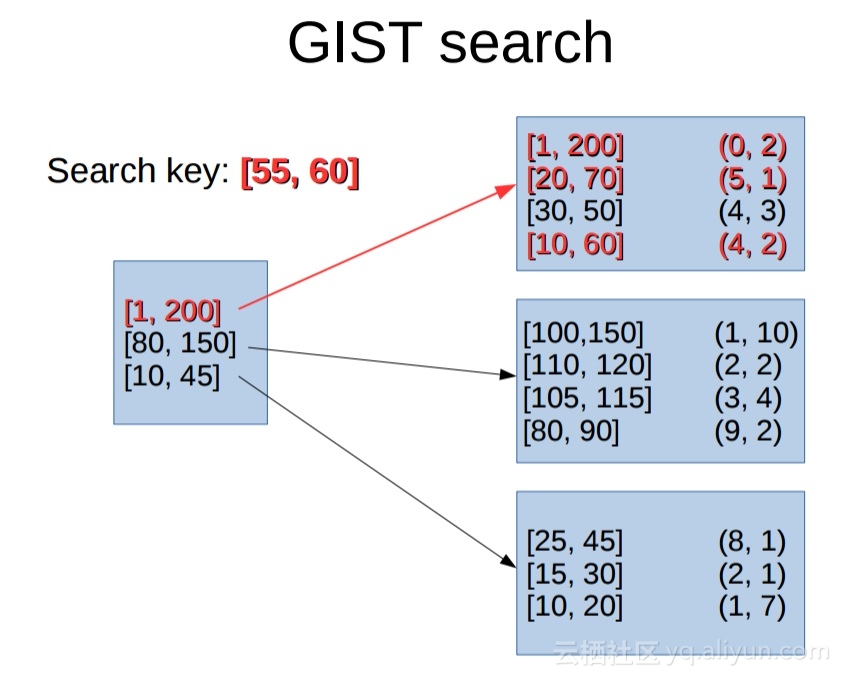
《PostgreSQL 黑科技 range 类型及 gist index 20x+ speedup than Mysql index combine query》
《PostgreSQL 黑科技 range 类型及 gist index 助力物联网(IoT)》
《从难缠的模糊查询聊开 - PostgreSQL独门绝招之一 GIN , GiST , SP-GiST , RUM 索引原理与技术背景》
人们为了更好的描述一个东西,有一种将大化小的思路,比如时钟被分为了12个区域,每个区域表示一个小时,然后每个小的区域又被划分为更小的区域表示分钟。
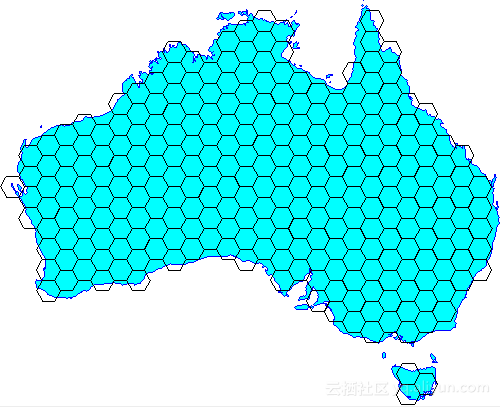
在GIS系统中,也有类似的思想,比如将地图划分成网格。通过编码来简化地理位置的判断(比如相交,包含,距离计算等),但是请注意使用网格带来的问题,比如精度的问题,网格的大小决定了精度,又比如相对坐标的问题,可能无法描述清楚边界的归属。
PostgreSQL可以提供给你更好的选择,矢量化的运算。


1. 在PostGIS中虽然也支持网格对象的描述方式,但是并不是使用这种方法来进行几何运算(比如相交,包含,距离计算等),所以不存在类似的精度问题,个人建议没有强需求的话,不必做这样的网格转换。
2. 如果是多种精度地图的切换(比如多个图层,每个图层代表一种地图精度),建议使用辐射的方式逐渐展开更精细的图层,以点为中心,逐渐辐射。(很多专业的地图软件是这样做的)
《蜂巢的艺术与技术价值 - PostgreSQL PostGIS's hex-grid》
电波表是一个非常典型的广播应用,类似的还有组播(注意不是主播哦),类似的应用也很多,比如广播电视,电台等。
在数据库中,其实也有类似的应用,比如利用PostgreSQL数据库的异步消息机制,往数据库的消息通道发送数据,应用程序可以监听对应的消息通道,获取异步消息数据。
通过异步消息在数据库中实现了一对多的广播效果。
在物联网中,也可以有类似的应用,例如结合PostgreSQL的流式计算,当传感器上报的数据达到触发事件的条件时,往异步消息通道发送一则消息,应用程序实时的接收异步消息,发现异常。
这样做的好处很多,即节省了空间(结合流式处理,完全可以轻量化部署),又能提高传播的效率(一对多的传播),程序设计也可以简单化。
在金融行业,也可以有类似的实现,比如对数据的实时流式监测,数据流经一系列的规则,触发异步消息。

《从电波表到数据库小程序之 - 数据库异步广播(notify/listen)》
《从微信小程序 到 数据库"小程序" , 鬼知道我经历了什么》
一个例子
这个例子使用PostgreSQL的异步消息通知机制(notify/listen),以及数据库的触发器,PostGIS地理库插件,结合nodejs, socket.io实现了一个实时的客户端GPS坐标更新的小业务。
1. 在数据库中新增GPS坐标,数据库端编写的"小程序"会自动发送异步消息给客户端,客户端马上就展示了当前新增的坐标

2. 修改GPS坐标,数据库端编写的"小程序"会自动发送异步消息给客户端,客户端刷新了当前坐标

3. 删除GPS坐标,数据库端编写的"小程序"会自动发送异步消息给客户端,客户端刷新了当前坐标

详见
《[转载] postgres + socket.io + nodejs 实时地图应用实践》
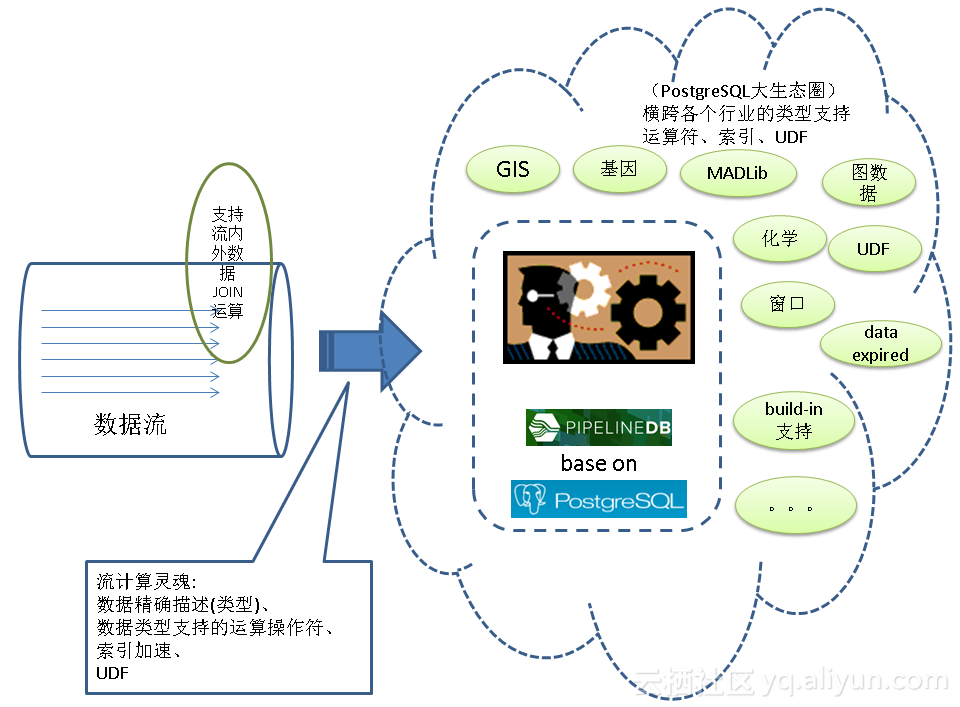
在物联网、金融行业中,有大量的数据产生,同时需要实时的对数据进行处理。
pipelinedb是基于PostgreSQL的一个流式计算数据库,纯C代码,效率极高(32c机器,单机日处理流水达到了250.56亿条)。同时它具备了PostgreSQL强大的功能基础,正在掀起一场流计算数据库制霸的腥风血雨。
在物联网(IoT)有非常广泛的应用场景,越来越多的用户开始从其他的流计算平台迁移到pipelineDB。
pipelinedb的用法非常简单,首先定义stream(流),然后基于stream定义对应的transform(事件触发模块),以及Continuous Views(实时统计模块)
数据往流里面插入,transform和Continuous Views就在后面实时的对流里的数据进行处理,对开发人员来说很友好,很高效。
值得庆祝的还有,所有的接口都是SQL操作,非常的方便,大大降低了开发难度。
《流计算风云再起 - PostgreSQL携PipelineDB力挺IoT》
除此之外,PostgreSQL的undo table,batch调度, 异步消息结合,也能达到与pipeline一样的效果。
《PostgreSQL 流式数据处理(聚合、过滤、转换...)系列 - 9》
《基于PostgreSQL的流式PipelineDB, 1000万/s实时统计不是梦》
《"物联网"流式处理应用 - 用PostgreSQL实时处理(万亿每天)》
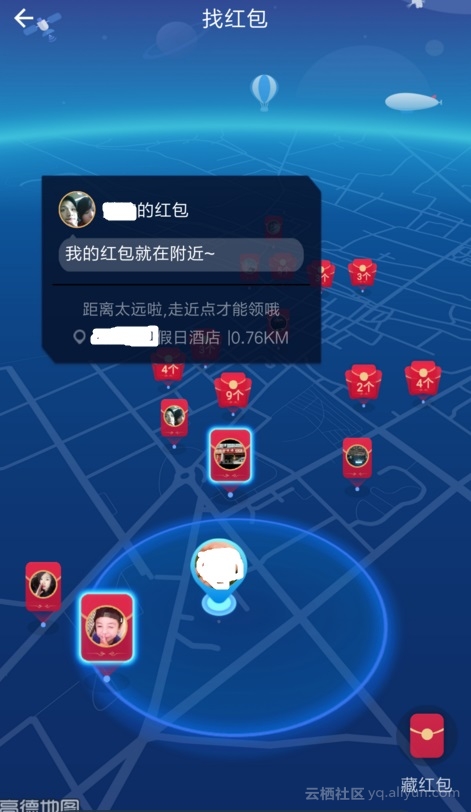
AR红包是GIS与图像、社交、广告等业务碰撞产生的一个全新业务场景。
需要做广告投放的公司,可以对着广告牌,或者店铺中的某个商品拍照,然后藏AR红包。
要找红包的人,需要找到这家店,并且也对准藏红包的物体拍摄,比较藏红包和找红包的两张图片,就可以实现抢红包的流程。
可以想象的空间很多。
使用的核心技术是GIS(地理位置)与图像近似度比较。
PostgreSQL对于这两项技术都可以很好的支持。

《(AR虚拟现实)红包 技术思考 - GIS与图像识别的完美结合》
在搜索引擎、数据公司、互联网中都会有网络爬虫的产品,或者有人机交互的产品。
有人的地方就有江湖,盗文、盗图的现象屡见不鲜,而更惨的是,盗图和盗文还会加一些水印。
也就是说,你在判断盗图、盗文的时候,不能光看完全一致,可能要看的是相似度。
这给内容去重带来了很大的麻烦,不过还好,PostgreSQL数据库整合了相似度去重的算法和索引接口,可以方便的处理相似数据。
比如相似的数组、相似的文本、相似的分词、相似的图像的搜索和去重等等。
又比如鉴黄。


《电商内容去重内容筛选应用(如何高效识别转载盗图侵权?) - 文本相似、图片集相似、数组相似的优化和索引技术》
《PostgreSQL 在视频、图片去重,图像搜索业务中的应用》
《从相似度算法谈起 - Effective similarity search in PostgreSQL》
在一些应用程序中,可能需要对表的所有字段进行检索,有些字段可能需要精准查询,有些字段可能需要模糊查询或全文检索。
比如一些前端页面下拉框的勾选和选择。
这种需求对于应用开发人员来说,会很蛋疼,因为写SQL很麻烦,例子:
之前写过一篇文章来解决这个问题
使用的是全文检索,而当用户的需求为模糊查询时? 如何来解决呢?
PostgreSQL中可以很好的解决这个问题,适用于任意字符(包括英文、中文、等等)。
《PostgreSQL 全表 全字段 模糊查询的毫秒级高效实现 - 搜索引擎颤抖了》
《从难缠的模糊查询聊开 - PostgreSQL独门绝招之一 GIN , GiST , SP-GiST , RUM 索引原理与技术背景》
随着IT行业在更多的传统行业渗透,我们正逐步的在进入DT时代,让数据发挥价值是企业的真正需求,否则就是一堆废的并且还持续消耗企业人力,财力的数据。
传统企业可能并不像互联网企业一样,有大量的开发人员、有大量的技术储备,通常还是以购买IT软件,或者以外包的形式在存在。
数据的核心 - 数据库,很多传统的行业还在使用传统的数据库。
随着IT向更多行业的渗透,数据类型越来越丰富(诸如人像、X光片、声波、指纹、DNA、化学分子、图谱数据、GIS、三维、多维 等等。。。),数据越来越多,怎么处理好这些数据,怎么让数据发挥价值,已经变成了对IT行业,对数据库的挑战。
对于互联网行业来说,可能对传统行业的业务并不熟悉,或者说互联网那一套技术虽然在互联网中能很好的运转,但是到了传统行业可不一定,比如说用于科研、军工的GIS,和互联网常见的需求就完全不一样。
除了对数据库功能方面的挑战,还有一方面的挑战来自性能方面,随着数据的爆炸,分析型的需求越来越难以满足,主要体现在数据的处理速度方面,而常见的hadoop生态中的处理方式需要消耗大量的开发人员,同时并不能很好的支持品种繁多的数据类型,即使GIS可能也无法很好的支持,更别说诸如人像、X光片、声波、指纹、DNA、化学分子、图谱数据、GIS、三维、多维 等等。
那么我们有什么好的方法来应对这些用户的痛处呢?
且看ApsaraDB产品线的PostgreSQL与HybridDB如何来一招左右互搏,左手在线事务处理,右手数据分析挖掘,解决企业痛处。
对传统企业来说,OLTP系统大多数使用的是Oracle等商业数据库,使用PostgreSQL可以与Oracle的功能、性能、SQL语法等做到高度兼容。
而对于分析场景,使用MPP产品HybridDB(基于GPDB),则可以很好的解决PB级以上的AP需求。
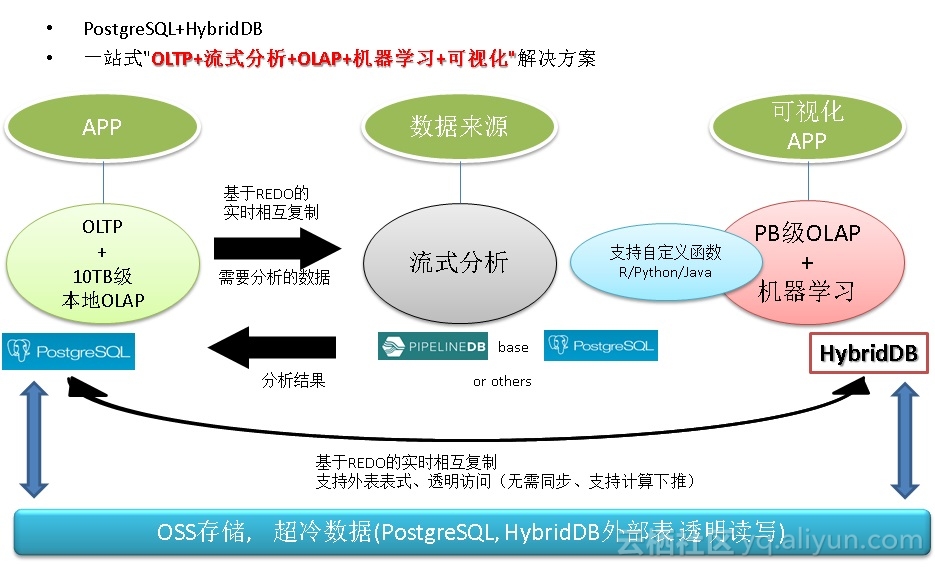
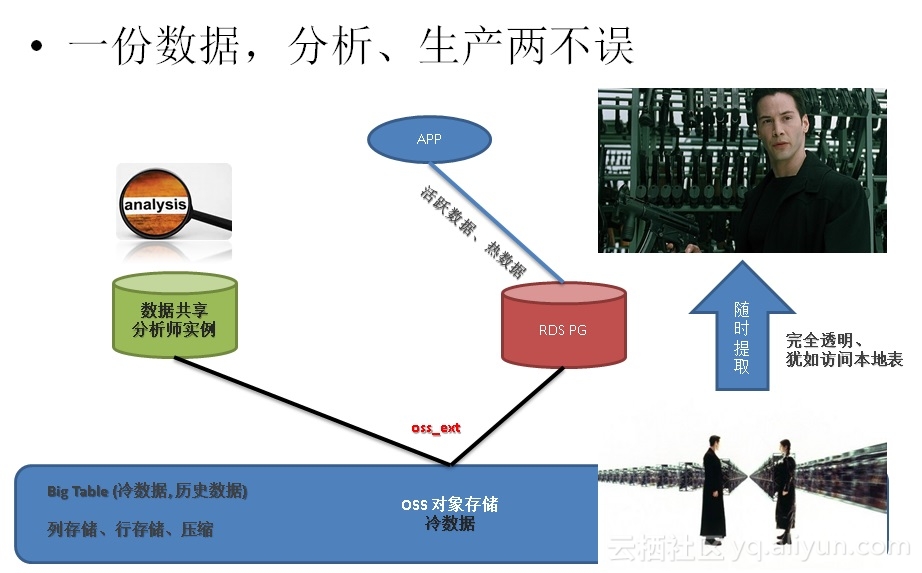
《元旦技术大礼包 - ApsaraDB的左右互搏术 - 解决企业痛处 TP+AP混合需求 - 无须再唱《爱你痛到不知痛》》
对于中小型企业,数据量在10TB量级的,分析型的事务甚至也可以交给PostgreSQL来处理。
因为它具备了多核并行处理的能力、列存储、JIT、算子复用、甚至向量化执行等技术,相比传统的数据库,在OLTP方面有10倍以上的性能提升。(同时还可以使用LLVM技术,GPU卡FPGA卡来 硬件加速分析)
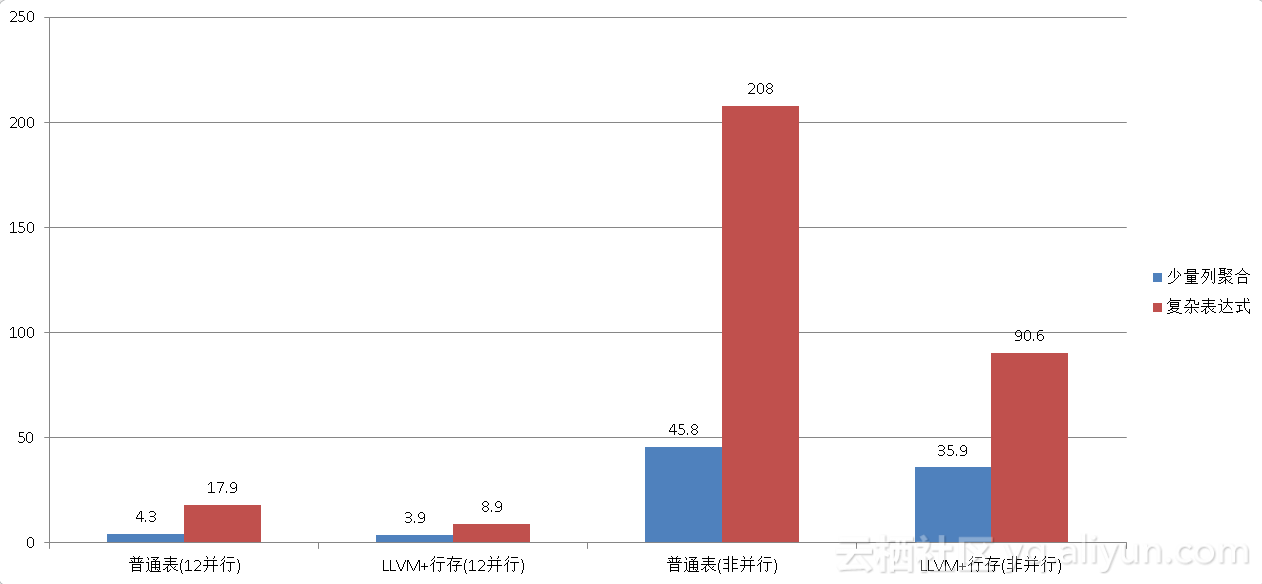
《分析加速引擎黑科技 - LLVM、列存、多核并行、算子复用 大联姻 - 一起来开启PostgreSQL的百宝箱》
《PostgreSQL 9.6 引领开源数据库攻克多核并行计算难题》
电商推荐系统 部分需求介绍
比如一家店铺,如何找到它的目标消费群体?
要回答这个问题,首先我们需要收集一些数据,比如:
1. 这家店铺以及其他的同类店铺的浏览、购买群体。
我们在逛电商时,会产生一些行为的记录,比如在什么时间,逛了哪些店铺,看了哪些商品,最后在哪家店铺购买了什么商品。
然后,对于单个商店来说,有哪些用户逛过他们的商店,购买过哪些商品,可以抽取出一部分人群。
2. 得到这些用户群体后,筛选出有同类消费欲望、或者具备相同属性的群体。
对这部分人群的属性进行分析,可以获得一个更大范围的群体,从而可以对这部分群体进行营销。
以上是对电商推荐系统的两个简单的推理。
PostgreSQL, HybridDB解决了推荐系统的三个核心问题
精准,属于数据挖掘系统的事情,使用PostgreSQL, Greenplum 的 MADlib机器学习库可以实现。
实时,实时的更新标签,在数据库中进行流式处理,相比外部流处理的方案,节约资源,减少开发成本,提高开发效率,提高时效性。
高效,使用PostgreSQL以及数组的GIN索引功能,实现在万亿USER_TAGS的情况下的毫秒级别的圈人功能。

《恭迎万亿级营销(圈人)潇洒的迈入毫秒时代 - 万亿user_tags级实时推荐系统数据库设计》
危化品的种类繁多。包括如常见的易爆、易燃、放射、腐蚀、剧毒、等等。
由于危化品的危害极大,所以监管显得尤为重要,
1. 生产环节
将各个原来人工监控的环节数字化,使用 传感器、流计算、规则(可以设置为动态的规则) 代替人的监管和经验。
2. 销售环节
利用社会关系分析,在销售环节挖掘不法分子,挖掘骗贷、骗保的虚假交易。利用地理位置跟踪,掌控整个交易的货物运输过程。
3. 仓储环节
仓储环节依旧使用传感器、流计算、应急机制对仓管的产品进行实时的监管,而对于危化品本身,我们已经不能使用普通的数据类型来存储,很幸运的是在PostgreSQL的生态圈中,有专门支持化学行业的RDKit支持,支持存储化合物类型,以及基于化合物类型的数据处理
(包括化学反应,分解等等)。
4. 运输环节
小结一下,在危化品的运输环节,使用传感器对货车、集装箱内的危化品的指标进行实时的监控,使用流式数据库pipelineDB流式的处理传感器实时上报的数据;使用PostgreSQL+PostGIS+pgrouting 对于货车的形式路径进行管理,绕开禁行路段、拥堵路段。
当出现事故时,使用PostgreSQL的GIS索引,快速的找出附近的应急救助资源(如交警、消防中队、医院、120)。
同时对危化品的货物存储,使用化学物类型存储,可以对这些类型进行更多的约束和模拟的合成,例如可以发现化学反应,防止出现类似天津爆炸事件。
5. 消耗环节
增加剩余量的监控,在闭环中起到很好的作用,达到供需平衡,避免供不应求,或者供过于求的事情发生。
6. 动态指挥中心
在给生产、仓库、物流配送、消耗环节添加了终端、传感器后,就建立了一个全面的危化品监管数据平台。 构建实时的监管全图。
7. 缉毒、发现不法分子等
通过社会关系学分析,结合RDKit插件,在数据库中存储了人的信息,存储了人与化学物的关系(比如购买过),然后,根据社会关系学分析,将一堆的化合物(原材料)结合起来,看看会不会发生反应,生成毒品或危化品。
从而发现不法分子。

《从天津滨海新区大爆炸、危化品监管聊聊 IT人背负的社会责任感》
人类是群居动物,随着人口的增长,联络方式越来越无界化,人与人,人与事件,人与时间之间形成了一张巨大的关系网络。
有许多场景就是基于这张巨大的关系网络的,比如。
1. 猎头挖人
作为IT人士或者猎头、HR,对Linkedin一定不陌生,领英网实际上就是一个维护人际关系的网站。
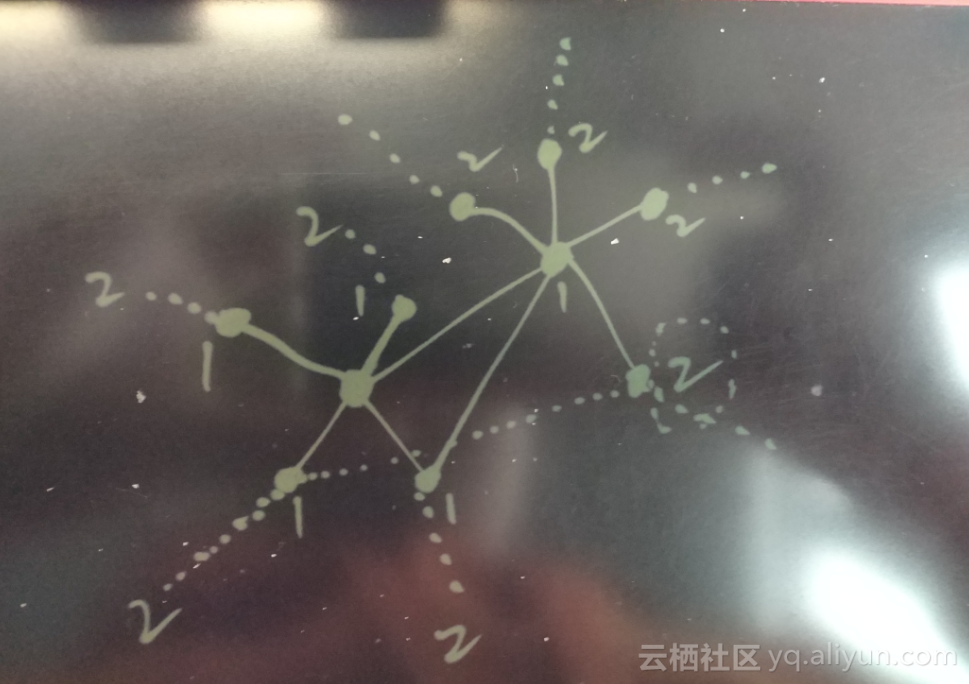
通过搜索你的一度人脉,可以找到与你直接相关的人,搜索2度人脉,可以搜索到与你间接相关的人。
当然你还可以继续搜索N度人脉,不过那些和你可能就不那么相关了。
如果你知道和美女范冰冰隔了几度人脉,是不是有点心动了呢?
其实在古代,就有这种社会关系学,还有这种专门的职业,买官卖官什么的,其实都是人脉关系网。看过红楼梦的话,你会发现那家子人怎么那么多亲戚呢?
2. 公安破案
公安刑侦学也是一类人脉相关的应用,只是现在的关系和行为越来越复杂,这种关系也越来越复杂,原来的人能接触的范围基本上就靠2条腿,顶多加匹马。
现在,手机,电脑,ATM机,超时,摄像头,汽车等等,都通过公路网、互联网连接在一起。
一个人的行为,产生的关系会更加的复杂,单靠人肉的关系分析,刑侦难度变得越来越复杂。
3. 金融风控
比如银行在审核贷款资格时,通常需要审核申请人是否有偿还能力,是否有虚假消息,行为习惯,资产,朋友圈等等。 同样涉及到复杂的人物关系,人的行为关系分析等等。
图片来自互联网

此类围绕人为中心,事件为关系牵连的业务催生了图数据库的诞生。
目前比较流行的图数据库比如neo4j,等。
详见
https://en.wikipedia.org/wiki/Graph_database
PostgreSQL是一个功能全面的数据库,其中就有一些图数据库产品的后台是使用PostgreSQL的,例如OpenCog, Cayley等。
除了这些图数据库产品,PostgreSQL本身在关系查询,关系管理方面也非常的成熟,十亿量级的关系网数据,3层关系运算仅需毫秒。
还可以用于运算人与人之间的最短关系,穷举关系等。
主要用到的技术plpgsql服务端编程、异步消息、数组、游标等。
《金融风控、公安刑侦、社会关系、人脉分析等需求分析与数据库实现 - PostgreSQL图数据库场景应用》
有一个这样的场景,一张小表A,里面存储了一些ID,大约几百个到万个。
(比如说巡逻车辆ID,环卫车辆的ID,公交车,微公交的ID)。
另外有一张日志表B,每条记录中的ID是来
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
