社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
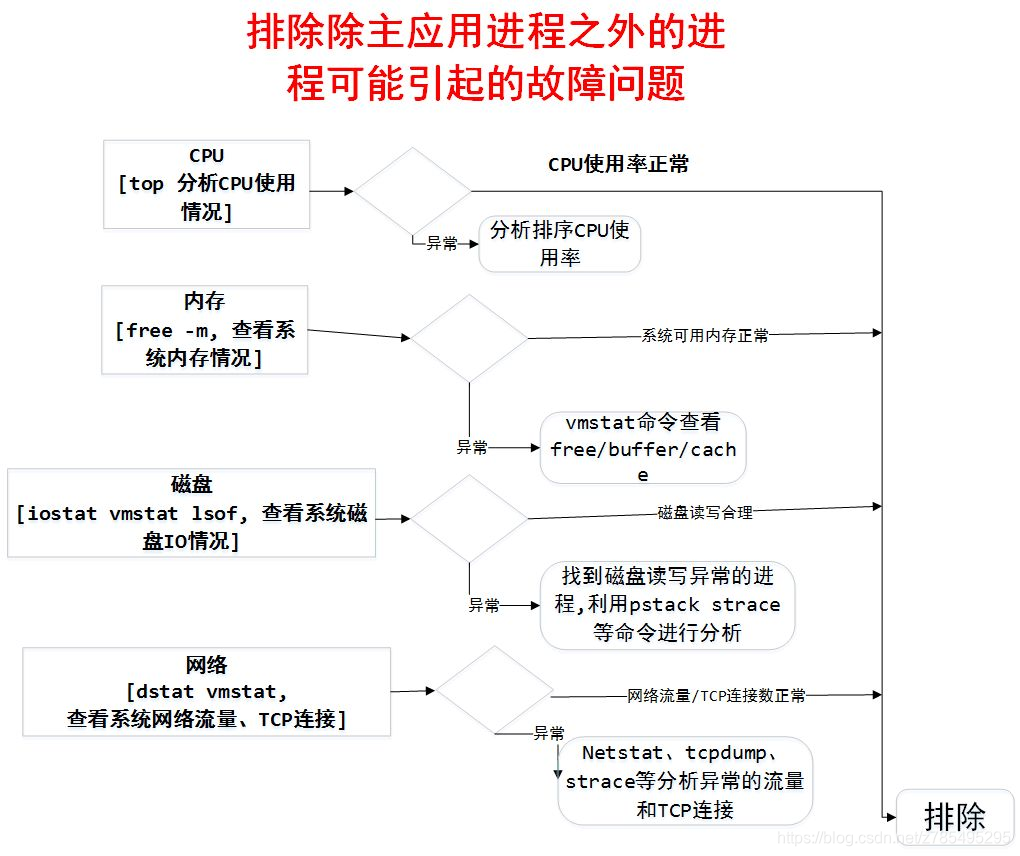
所有 Java 服务的线上问题从系统表象来看归结起来总共有四方面:CPU、内存、磁盘、网络。例如 CPU 使用率峰值突然飚高、内存溢出 (泄露)、磁盘满了、网络流量异常、FullGC 等等问题。
基于这些现象我们可以将线上问题分成两大类: 系统异常、业务服务异常。
常见的系统异常现象包括: CPU 占用率过高、CPU 上下文切换频率次数较高、磁盘满了、磁盘 I/O 过于频繁、网络流量异常 (连接数过多)、系统可用内存长期处于较低值 (导致 oom killer) 等等。
这些问题可以通过 top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、pstack、vmstat、strace(底层系统调用) 等工具获取系统异常现象数据。
此外,如果对系统以及应用进行排查后,均未发现异常现象的更笨原因,那么也有可能是外部基础设施如 IAAS 平台本身引发的问题。
例如运营商网络或者云服务提供商偶尔可能也会发生一些故障问题,你的引用只有某个区域如广东用户访问系统时发生服务不可用现象,那么极有可能是这些原因导致的。
今天我司部署在阿里云华东地域的业务系统中午时分突然不能为广东地区用户提供正常服务,对系统进行各种排查均为发现任何问题。
最后,通过查询阿里云公告得知原因是 “ 广东地区电信线路访问华东地区互联网资源(包含阿里云华东 1 地域)出现网络丢包或者延迟增大的异常情况“。
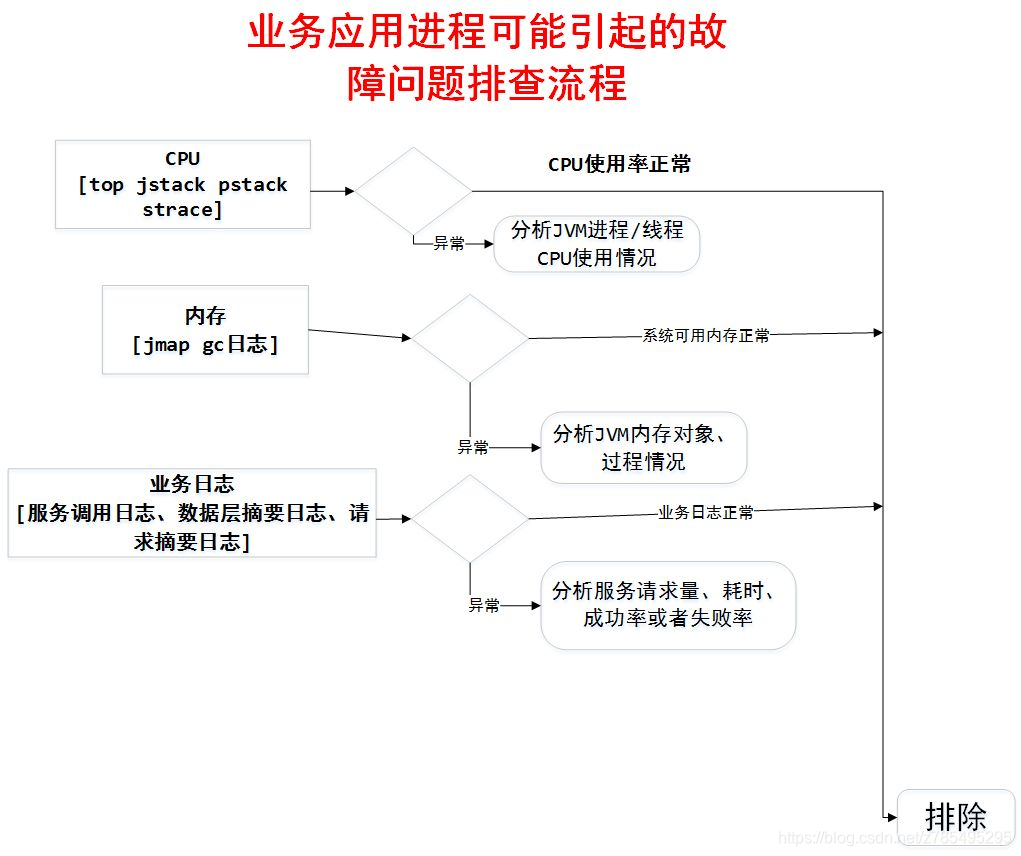
常见的业务服务异常现象包括: PV 量过高、服务调用耗时异常、线程死锁、多线程并发问题、频繁进行 Full GC、异常安全攻击扫描等。
我们一般会采用排除法,从外部排查到内部排查的方式来定位线上服务问题。
查看cpu占用率查看占用高的进程号
第一步:输入TOP命令
第二步: 输入 shift+h ,打开线程模式,查看目前最耗系统资源的线程是哪些
可以再按 1用CPU模式看各个CPU资源的使用情况 按O查看帮助
pgrep 是通过程序的名字来查询进程的工具,一般是用来判断程序是否正在运行。在服务器的配置和管理中,这个工具常被应用,简单明了 用法:
pgrep 参数选项 程序名
eg:
pgrep java#查询出JAVA进程的进程号 常用参数:
-l 列出程序名和进程ID
-o 进程起始的ID
-n 进程终止的ID
方法一
:ls /proc/20967/task/|wc -l: 20967是进程号方法二 :
ps -eLf | grep 20967 |wc -lps:该方法对于排查JAVA各种容器(eg:tomcat)由于创建过多线程,导致cpu耗费大量的资源进行上线文切换非常有帮助。
我们可以写一个脚本,当线程数>阀值,则进行jstack dunp
使用top命令看线程资源使用情况后,可以得到这些线程的pid,然后把这些线程号转换成16进制,
printf "%x" pidjstack -l pid |grep xx(pid:java进程号,xx为16进制线程pid)
:把java线程快照给dump下来.可以用来排查死锁,以及耗费系统资源线程当前的运行情况eg:
jstack -l pid >jstack_dump.log#将当前JVM线程快照dump到jstack_dump.log文件中
grep jstack_dump.log16进制号 #这样可以看看当前这些耗费资源的线程的内存情况
命令格式: jstack [-option] jvm_pid 参数: -l 打印关于锁的堆栈信息(long listing. Prints
additional information about locks)
-m 混合打印模式,可打印C++和JAVA的堆栈信息
-h 打印帮助信息
cat 1016.jstack | awk '{print $(1)}' | sort | uniq -c | sort -k 1 -n -r|head -10
$JAVA_HOME/bin/
jstat -gcutil pgrep java1000 10
(后三个参数是PID,扫描间隔时间单位毫秒,扫描次数)
$JAVA_HOME/bin/jstat -gcpgrep java1000 10
可以通过netstat命令来查看某个时间段的网络重传率。 通过netstat -l enX -sp tcp
收集发送的TCP包数和retransmit的包数,间隔一定时间过后 再次收集这两个数值,分别相减后相除,可得出在此采样时间内的TCP重传率
jps:显示当前用户的所有java进程的PID
jps -v 3331:显示虚拟机参数 jps -m
3331:显示传递给main()函数的参数
jps -l 3331:显示主类的全路径
生成堆转储快照(heapdump)
常用指令
jmap -histo:live 25085 | head -20
jmap -heap 3331:查看java 堆(heap)使用情况
jmap -histo 3331:查看堆内存(histogram)中的对象数量及大小
jmap -histo:live 3331:JVM会先触发gc,然后再统计信息
jmap -dump:format=b,file=heapDump 3331:将内存使用的详细情况输出到文件,之后一般使用其他工具进行分析。
一般与jmap搭配使用,用来分析jmap生成的堆转储文件。
由于有很多可视化工具(Eclipse Memory Analyzer 、IBM HeapAnalyzer)可以替代,所以很少用。不过在没有可视化工具的机器上也是可用的。
常用指令
jmap -dump:format=b,file=heapDump 3331 + jhat
heapDump:解析Java堆转储文件,并启动一个 web server
一、使用jps查看线程ID
二、使用jstat -gc 3331 250 20 查看gc情况,一般比较关注PERM区的情况,查看GC的增长情况。
三、使用jstat -gccause:额外输出上次GC原因
四、使用jmap -dump:format=b,file=heapDump 3331生成堆转储文件
五、使用jhat或者可视化工具(Eclipse Memory Analyzer 、IBM HeapAnalyzer)分析堆情况。
六、结合代码解决内存溢出或泄露问题。
一、使用jps查看线程ID
二、使用jstack 3331:查看线程情况
grep java.lang.Thread.State dump17 | awk ‘{print $2$3$4$5}’ | sort | uniq -c
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
