社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
HashMap的原理也是大厂面试中经常会涉及的问题,同时也是工作中常用到的Java容器,本文主要通过对以下问题进行分析讲解,来帮助大家理解HashMap的原理。
这是网上找的一张流程图,可以结合着步骤来看这个流程图,了解添加键值对的过程。
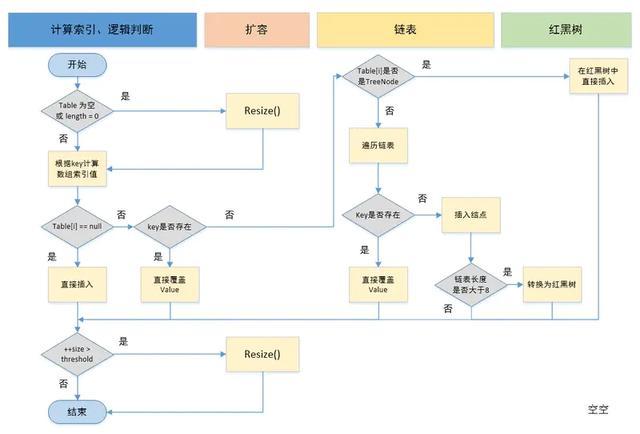
1.初始化table
判断table是否为空或为null,否则执行resize()方法(resize方法一般是扩容时调用,也可以调用来初始化table)。
2.计算hash值
根据键值key计算hash值。(因为hashCode是一个int类型的变量,是4字节,32位,所以这里会将hashCode的低16位与高16位进行一个异或运算,来保留高位的特征,以便于得到的hash值更加均匀分布)

3.插入或更新节点
根据(n - 1) & hash计算得到插入的数组下标i,然后进行判断
那么说明当前数组下标下,没有hash冲突的元素,直接新建节点添加。
判断table[i]的首个元素是否和key一样,如果相同直接更新value。
判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对。
上面的判断条件都不满足,说明table[i]存储的是一个链表,那么遍历链表,判断是否存在已有元素的key与插入键值对的key相等,如果是,那么更新value,如果没有,那么在链表末尾插入一个新节点。插入之后判断链表长度是否大于8,大于8的话把链表转换为红黑树。
插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(一般是数组长度*负载因子0.75),如果超过,进行扩容。
源代码如下:

其实通过学习HashMap添加键值对的方法,我们可以看到整个方法内都没有使用到锁,所以一旦多线并发访问,就有可能造成数据不一致的问题,
例如:
如果有两个添加键值对的线程都执行到if ((tab = table) == null || (n = tab.length) == 0)这行语句,都对table变量进行数组初始化,就会造成已经初始化好的数组table被覆盖,然后前面初始化的线程会将键值对添加到之前初始化的数组中去,造成键值对丢失。

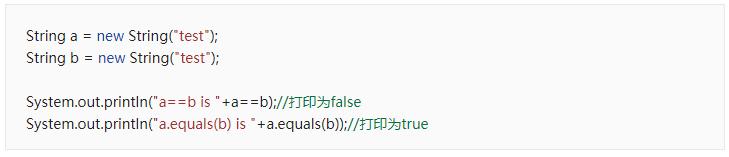
当我们的对象一旦作为HashMap中的key,或者是HashSet中的元素使用时,就必须同时重写hashCode()和equal()方法
首先看看hashCode()和equal()方法的默认实现
可以看到Obejct类中的源码如下,可以看到equals()方法的默认实现是判断两个对象的内存地址是否相同来决定返回结果。

网上很多博客说hashCode的默认实现是返回内存地址,其实不对,以OpenJDK为例,hashCode的默认计算方法有5种,有返回随机数的,有返回内存地址,具体采用哪一种计算方法取决于运行时库和JVM的具体实现。
感兴趣的朋友可以看看这篇博客 blog.csdn.net/xusiwei1236…
然后看看hashCode()方法,equal()方法在HashMap中的应用

为了将一组键值对均匀得存储在一个数组中,HashMap对key的hashCode进行计算得到一个hash值,用hash对数组长度取模,得到数组下标,将键值对存储在数组下标对应的链表下(假设链表长度小于8,没有达到转换为红黑树的阀值)。
下面是添加键值对的putVal()方法,当数组下标对应的是一个链表时执行的代码
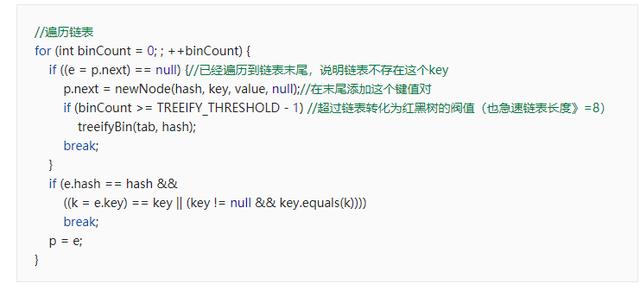
可以清楚地看到判断添加的key与链表中已存在的key是否相等的方法主要是e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))), 也就是: 1.先判断hash值是否相等,不相等直接结束判断,因为hash值不相等,key肯定不相等。 2.判断两个key对象的内存地址是否相等(相等指向内存中同一个对象)。 3.key不为null,调用key的equal()方法判断是否相等,因为有可能两个key在内存中存储的地址不一样,但是是相等的。 就像是
背景
假设我们有一个KeyObject类,假设我们认为两个KeyObject的属性a相等,那么KeyObject就是相等的相等的,我们将KeyObject作为HashMap的key,以KeyObject是否相等作为去重标准,不能重复添加KeyObject相等,value不等的值到HashMap中去
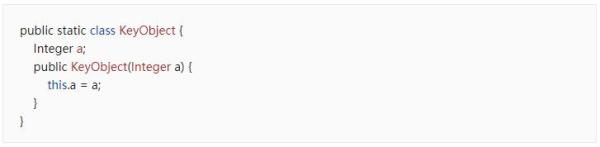
假设都hashCode()方法和equals()方法都不重写(结果:HashMap无法保证去重)
执行以下代码:

如果KeyObject的hashCode()方法和equals()方法都不重写,那么即便KeyObject的属性a都是1,key1和key2的hashCode都是不相同的,key1和key2调用equals()方法也不相等,这样hashMap中就可以同时存在key1和key2了。
打印结果:

假如只重写hashCode()方法(结果:无法正确地与链表元素进行相等判断,从而无法保证去重)
执行以下代码:
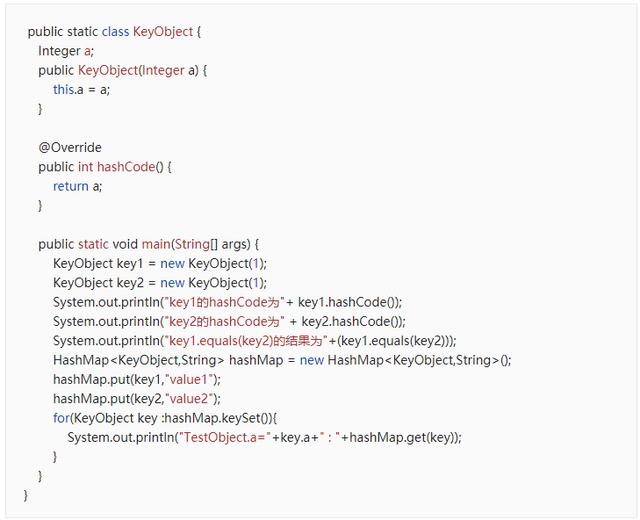
此时equal()方法的实现是默认实现,也就是当两个对象的内存地址相等时,equal()方法才返回true,虽然key1和key2的a属性是相同的,但是他们在内存中是不同的对象,所以key1==key2结果会是false,KeyObject的equals()方法默认实现是判断两个对象的内存地址,所以 key1.equals(key2)也会是false,所以这两个键值对可以重复地添加到hashMap中去。
输出结果:

假如只重写equals()方法(结果:映射到HashMap中不同数组下标,无法保证去重)

假设只equals()方法,hashCode方法会是默认实现,具体的计算方法取决于JVM,(测试时发现是内存地址不同但是相等的对象,它们的hashCode不相同),所以计算得到的数组下标不相同,会存储到hashMap中不同数组下标下的链表中,也会导致HashMap中存在重复元素。
输出结果如下:
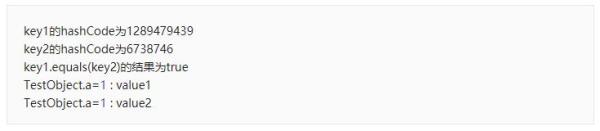
所以当我们的对象一旦作为HashMap中的key,或者是HashSet中的元素使用时,就必须同时重写hashCode()和equal()方法,因为hashCode会影响key存储的数组下标及与链表元素的初步判断,equal()是作为判断key与链表中的key是否相等的最后标准。
所以只重写hashCode()方法,会导致无法正确地与链表元素进行相等判断,从而无法保证去重)
只重写equals()方法导致键值对映射到HashMap中不同数组下标,无法保证去重
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
