社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
大数据量的查询,不仅查询速度非常慢,而且还会导致数据库经常宕机(刚接到这个项目时候,数据库经常宕机o(╯□╰)o)。 那么,如何处理上亿级的数据量呢?如何从数据库经常宕机到上亿数据秒查?仅以此篇文章作为处理的总结。
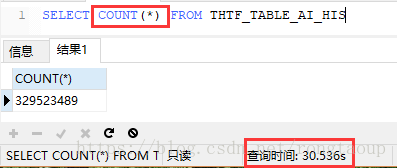
下面是存放历史数据表的数据量,数据量确实很大,3亿多条。但这也仅仅是测试数据而已,因为客户端服务器上的数据可能远不止于此。
为什么说远不止于此呢?实际情况是这样的:
有一个实时数据表,THTF_TABLE_AI,以及历史数据表,THTF_TABLE_AI_HIS
实时数据表固定3万条数据(客户推送过来的数据),每2小时刷新一次,每刷新一次就往历史表中插入一次数据。
可以算一下,历史表中数据量的数据量:
3 x 12 x 30 = 1080万,也就是每个月存储1080条数据,1年就1亿多的数据量。这样大的数据量,导致查询速度慢,估计用户会气炸的...
第一步:分表
如果历史表中存储了很多年的数据,会造成严重的数据冗余。那如果将历史表分表存储,比如每年创建一个表,数据存储到对应的年表中,必定会减少很多数据量。(如果分成年表数据量还是过大,可以细分到月表,天表...)。
我们这里以创建年表为例,写一个创建年表的存储过程,利用PLSQL定时任务定时执行此存储过程(定时每年12月31号创建下一年的年表)。存储过程如下,定时任务查看此篇文章:PLSQL执行Oracle定时任务
CREATE OR REPLACE
PROCEDURE CREATE_YEAR_TABLE IS
/*变量*/
grantSql VARCHAR2(50);
yearStr VARCHAR2(4);
tableCount int(2);
createSql VARCHAR2(1000);
BEGIN
/*权限*/
grantSql := 'grant create any table to thtf_taiyuan';
EXECUTE IMMEDIATE grantSql;
/*创建年表 注意create table 后边的空格*/
SELECT TO_CHAR(SYSDATE, 'yyyy')+1 INTO yearStr FROM dual;
createSql := 'CREATE TABLE ' || 'THTF_TABLE_YEAR_' || yearStr ||
'( SHE_SHI_CODE VARCHAR2(100),
SHE_SHI_TYPE NUMBER DEFAULT 1,
FEN_GONG_SI VARCHAR2(100),
SHUI_HAO NUMBER(20,4) DEFAULT 0,
PRE_SHUI_HAO NUMBER(20,4) DEFAULT 0,
DIAN_HAO NUMBER(20,4) DEFAULT 0,
PRE_DIAN_HAO NUMBER(20,4) DEFAULT 0,
RE_HAO NUMBER(20,4) DEFAULT 0,
PRE_RE_HAO NUMBER(20,4) DEFAULT 0,
SHI_JIAN DATE DEFAULT SYSDATE,
STATE NUMBER DEFAULT 1 )';
SELECT COUNT(1) INTO tableCount FROM user_tables WHERE table_name = CONCAT('THTF_TABLE_YEAR_', yearStr);
IF tableCount = 0 THEN
EXECUTE IMMEDIATE createSql;
COMMIT;
END IF;
END CREATE_YEAR_TABLE;
第二步:分区
年表创建过后,查询就是查询年表中的数据,可是虽然分表了,但是年表中的数据量仍然很大,查询速度虽然有提升,但并不能满足用户的要求。便考虑到分表再分区,即将历史数据以不同的年表来存储,在年表中按月分区。
说道分区,要恶补一下了~
数据库分区:就是减少SQL操作的数据量,从而提升查询效率。表分区后,逻辑上仍然是一张表,只不过将表中的数据在物理上存放到多个表空间上。这样在查询数据时,会查询相应分区的数据,避免了全表扫描。
分区又分为水平分区、垂直分区。
水平分区:就是对行进行分区,举个例子来说,就是一个表中有1000万条数据,每100万条数据划一个分区,这样就将表中数据分到10个分区中去。水平分区要通过某个特定的属性列进行分区,比如我用的列就是Date时间。
垂直分区:通过对标垂直划分来减少表的宽度,从而提升查询效率。比如一个学生表中,有他相关的信息列,还有论文列以CLOB存储。这些以CLOB存储的论文并不会经常被访问到,这时候就要把这些不经常使用的CLOB划分到另一个分区,需要访问时再调用它。
总的来说,分区的主要目的还是避免了全表扫描,从而提升查询速度。
接下来在上面的存储过程的基础上,我们创建按月分区。
CREATE OR REPLACE
PROCEDURE CREATE_YEAR_TABLE IS
grantSql VARCHAR2(50);
yearStr VARCHAR2(4);
tableCount int(2);
createSql VARCHAR2(1000);
BEGIN
/*权限*/
grantSql := 'grant create any table to thtf_taiyuan';
EXECUTE IMMEDIATE grantSql;
/*创建年表 注意create table 后边的空格*/
SELECT TO_CHAR(SYSDATE, 'yyyy')+1 INTO yearStr FROM dual;
createSql := 'CREATE TABLE ' || 'THTF_TABLE_YEAR_' || yearStr ||
'( SHE_SHI_CODE VARCHAR2(100),
SHE_SHI_TYPE NUMBER DEFAULT 1,
FEN_GONG_SI VARCHAR2(100),
SHUI_HAO NUMBER(20,4) DEFAULT 0,
PRE_SHUI_HAO NUMBER(20,4) DEFAULT 0,
DIAN_HAO NUMBER(20,4) DEFAULT 0,
PRE_DIAN_HAO NUMBER(20,4) DEFAULT 0,
RE_HAO NUMBER(20,4) DEFAULT 0,
PRE_RE_HAO NUMBER(20,4) DEFAULT 0,
SHI_JIAN DATE DEFAULT SYSDATE,
STATE NUMBER DEFAULT 1 )
/*按月分区*/
PARTITION BY RANGE(SHI_JIAN)
INTERVAL(NUMTOYMINTERVAL(1,''' || 'MONTH' || '''))
( PARTITION PART1 VALUES LESS THAN(TO_DATE('''|| CONCAT(yearStr, '-11-01') ||''','''|| 'YYYY-MM-DD' ||''')) )';
SELECT COUNT(1) INTO tableCount FROM user_tables WHERE table_name = CONCAT('THTF_TABLE_YEAR_', yearStr);
IF tableCount = 0 THEN
EXECUTE IMMEDIATE createSql;
--添加注释
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.SHE_SHI_CODE IS ''设施编号''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.SHE_SHI_TYPE IS ''设施类型''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.FEN_GONG_SI IS ''分公司''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.SHUI_HAO IS ''水耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.PRE_SHUI_HAO IS ''上一小时水耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.DIAN_HAO IS ''电耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.PRE_DIAN_HAO IS ''上一小时电耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.RE_HAO IS ''热耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.PRE_RE_HAO IS ''上一小时热耗''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.SHI_JIAN IS ''时间''';
EXECUTE IMMEDIATE 'COMMENT ON COLUMN ' || 'THTF_TABLE_YEAR_' || yearStr || '.STATE IS ''状态值''';
COMMIT;
END IF;
END CREATE_YEAR_TABLE;
如果分区要细化到天,将分区语句改为如下:
PARTITION BY RANGE(SHI_JIAN)
INTERVAL(NUMTOYMINTERVAL(1,''' || 'DAY' || '''))
( PARTITION PART1 VALUES LESS THAN(TO_DATE('''|| CONCAT(yearStr, '-01-01') ||''','''|| 'YYYY-MM-DD' ||''')) )';创建完分区后,如何查询表中有哪些分区呢?
--查分区数
SELECT table_name,partition_name from user_tab_partitions where table_name = 'THTF_TABLE_YEAR_2017'如何查询分区中的数据呢?
--查分区数据
SELECT * FROM THTF_TABLE_YEAR_2017 PARTITION(PART1)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!