社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前面说过Python爬取的数据可以存储到文件、关系型数据库、非关系型数据库。前面两篇文章没看的,可快速戳这里查看!https://mp.weixin.qq.com/s/A-qry4r3ymuCLXLBTF6Ccw
https://mp.weixin.qq.com/s/9iUm_csJaY5xCyBUZoAzpg
而存储到文件的数据一般都具有时效性,例如股市行情、商品信息和排行榜信息等等。这样的信息是具有动态性的,非特殊要求,可以存放到文件中,下面让我们来看一下存入文件的几种方法,文章有点长,但全是干货,请耐心看完。
Txt文件存储
将数据保存到TXT文件很简单,使用如下语法即可打开一个文件写入数据。
with open('test.txt','w',encoding='utf-8') as file:
file.write()这里来看一个例子:
爬取知乎上“发现”页面的热门话题部分,将问题和答案统一保存为txt格式。
# encoding=utf-8
import requests
#使用requests库将网页源码获取下来
from pyquery import PyQuery as pq
#使用pyquery解析库解析
url = 'http://www.zhihu.com/explore'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Mobile Safari/537.36'
}
html = requests.get(url,headers = headers).text
doc = pq(html)
items = doc('.explore-tab .feed-item').items()
for item in items:
question = item.find('h2').text()
author = item.find('.author-link-line').text()
answer = pq(item.find('.content').html()).text()
with open('test.txt','w',encoding='utf-8') as file:
file.write('n'.join([question,author,answer]))
file.write('n' + '=' * 50 + 'n')
如下图所示,可以看到这篇文章已经写入文本文件了。

JSON文件存储
JSON(javaScript Object Notation,也就是JavaScript对象标记)
JSON是通过数组和对象的组合来表示数据,构造简洁但结构化程度非常高,是一种轻量级的数据交换格式。Python为我们提供了简单易用的 JSON库来实现JSON文件的读写操作,我们可以调用 JSON loads()方法将JSON文本字符串转为JSON对象,可以通过 dumps()方法将 JSON 对象转为文本字符串,具体看下面代码。
import json
str = '''[{
"name":"Bob",
"gender":"male",
"birthay":"1992-10-18"
} , {
"name":"Selina",
"gender":"female",
"birthdat":"1995-10-18"
}]'''
print(type(str))
data = json.loads(str)
print(data)
print(type(data))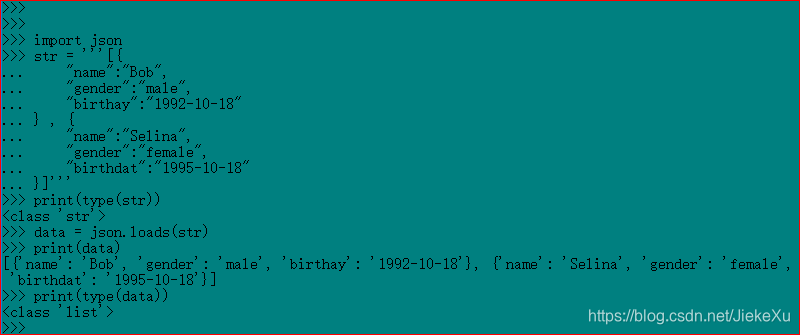
另外我们可以使用dumps()方法将JSON对象转化为字符串,如下图所示。
import json
data = [{
'name':'Bob',
'gende':'male',
'birthday':'1992-10-18'
}]
with open ('data.json','w') as file:
#如果想保存为JSON格式的,可以在加一个参数indent=2即可。
file.write(json.dumps(data))
#加参数后的data.json文件内容如下
'''
[
{
"name": "Bob",
"gende": "male",
"birthday": "1992-10-18"
}
]
'''
还有一种常见的问题,若JSON文件包含中文字符呢?这样打开肯定会出现乱码的,那么我们该怎么办呢?看下面代码。
import json
data = [{
'name':'小马',
'gende':'女',
'birthday':'1994-12-30'
}]
with open ('data.json','w') as file:
file.write(json.dumps(data,indent=2))
看到这样的内容,肯定不是我们想要的结果啊,中文字符都变成了Unicode字符,那么,为了显示中文字符,还需要指定参数ensure_asci为 False,另外还需要规定输出文件的编码。这样就可以完美的将中文显示出来了,如下图所示。
with open('data.json','w',encoding='utf-8') as file:
file.write(json.dumps(data,indent=2,ensure_ascii=False))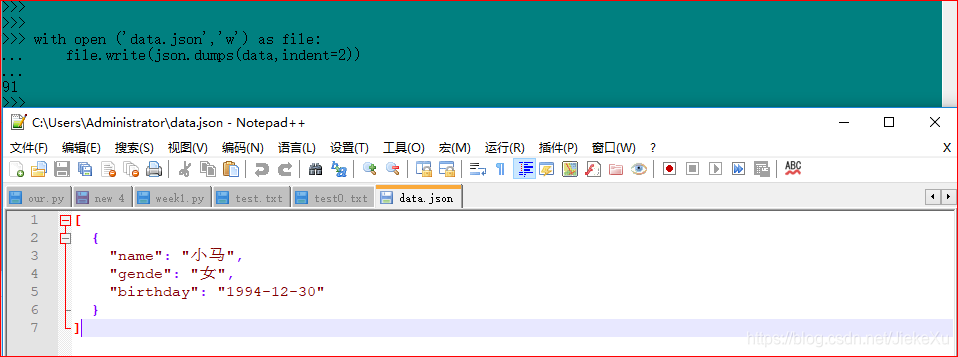
CSV文件存储
CSV(Comma-Separated Values),中文可成为逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。
Python标准库自带CSV模块,不用自行安装,直接导入即可,代码如下:
import csv
#这里如若文件存在则直接打开,不存在可自动创建,若不设置newline = ''每行数据会隔一行空白行
with open('csv_test.csv','w',newline = '') as csvfile:
#将文件加载到CSV对象中
write = csv.writer(csvfile)
#写入一行表头数据
write.writerow(['姓名','年龄','电话'])
#多行数据写入
data = {('zhangsan','15','13809391234'),('lisi','25','13512340000')}
#关闭CSV对象
write.writerows(data)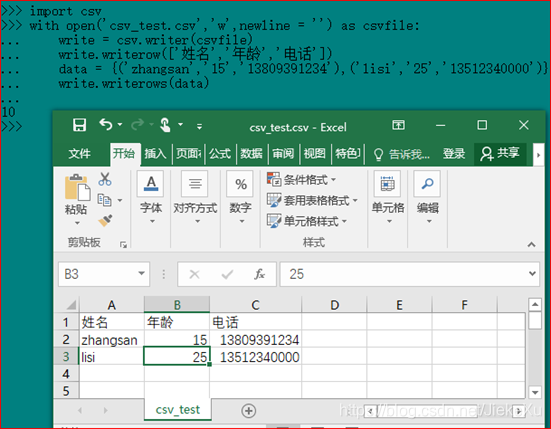
写数据到CSV使用open函数便可打开文件,那么读CSV数据则使用reader和DictReader,两者都是接收一个可迭代的对象,返回一个生成器。reader函数返回是将一行数据以列表形式返回,而DictReader函数返回的是一个字典,字典的值是单元格的值,字典的键则是这个单元格的标题,具体可看如下代码。
import csv
csvfile = open ('csv_test.csv','r')
#以列表形式输出
reader = csv.reader(csvfile)
#以字典形式输出,第一行作为字典的键
#reader1 = csv.DictReader(csvfile)
rows = [row for in reader]
print(rows)
#以下为输出结果
#[['姓名', '年龄', '电话'], ['zhangsan', '15', '13809391234'], ['lisi', '25', '13512340000']]
#以字典的形式输出,第一行作为字典的键
import csv
csvfile = open('csv_test.csv','r')
reader = csv.DictReader(csvfile)
for row in reader:
print(row)
#以下为输出结果
#OrderedDict([('姓名', 'zhangsan'), ('年龄', '15'), ('电话', '13809391234')])
#OrderedDict([('姓名', 'lisi'), ('年龄', '25'), ('电话', '13512340000')])以上代码实现了将整个文件数据全部打印出来了,在实际数据中这也不太现实,我们可能会获取某行的数据,则可以使用循环全部数据再对每行数据进行判断,符合条件的数据筛选出来,具体代码如下。
import csv
csvfile = open('csv_test.csv','r')
#以列表形式输出
reader = csv.reader(csvfile)
for row in reader:
if 'lisi' in row:
print(row)
#以下是输出结果
#['lisi', '25', '13512340000']
如果你接触过pandas的话,使用起来也很方便
>>> import pandas as pd
>>> df = pd.read_csv('csv_test.csv',encoding ='gb2312')
>>> print(df)
姓名 年龄 电话
0 zhangsan 15 13809391234
1 lisi 25 13512340000
>>>值得注意的是这里可能会出现乱码,需要指定字符编码,csv文件的编码为gb2312或utf-8时,指定编码格式pd.read_csv(name, encoding='gb2312')可解决乱码问题;如果编码格式为utf-8,则另存为txt文件,pd.read_table(name) 不用指定编码格式,也可以解决乱码问题。

使用CSV存储数据相对而言还是简单的,这个也是经常使用的方式,实用性很强,小伙伴要掌握哦,下面顺道说一下EXCEL格式数据的读写。
Excel文件存储
python操作Excel时,对应的有不同的版本支持库,若Excel为2003时,需选择pyExcelerator;若Excel为2007时,需选择openpyxl;而xlrd库支持所有版本的数据读取,xlwt库支持所有版本的数据写入。
所以,考虑到兼容性一般都选择使用 xlrd和xlwt,Windows环境CMD下直接使用pip安装即可。
pip3 install xlrd
pip3 install xlwt将数据写入到Excel是比较复杂的,有格式以及公式、插入图片等的功能,下面直接看写入Excel的语法。
import xlwt
#新建一个Excel文件
wb = xlwt.Workbook()
#在新建的文件中新建一个名为Python的工作簿
ws = wb.add_sheet(‘Python’,cell_overwrite_ok=True)
#定义字体对齐方式对象
alignment = xlwt.Alignment()
#设置水平方向
#HORZ_GENERAL,HORZ_LEFT,HORZ_CENTER,HORZ_RIGHT,HORZ_FILLED
#HORZ_JUSTIFIED,HORZ_CENTER_ACROSS_SEL,HORZ_DISTRIBUTED
alignment.horz = xlwt.Alignment.HORZ_CENTER
#设置垂直方向
#VERT_TOP,VERT_CENTER,VERT_BOTTOM,VERT_JUSTIFIED,VERT_DISTRIBUTED
alignment.vert = xlwt.Alignment.VERT_CENTER
#定义格式对象
style = xlwt.XFStyle()
style.alignment = alignment
#合并单元格write_merge(开始行,结束行,开始列,结束列,内容,格式)
ws.write_merge(0,0,0,5,'Python数据存储',style)
#写入数据we.write(行,列,内容)
for i in range(2,7):
for k in range(5):
ws.write(i,k,i+k)
#Excel公式xlwt.Formula
ws.write(i,5,xlwt.Formula('SUM(A'+srt(i+1)+ ':E'+str(i+1)+')'))
#wb.save('file.xls')
#插入bmp格式图片,insert_bitmap(img,x,y,x1,y1,scale_x=0.8,scale_y=1)
#x表示行数,y表示列数,x1表示相对原来位置向下偏移的像素,y1表示相对原来位置像右偏移的像素,scale_x、scale_y表示缩放比例
ws.insert_bitmap('G:\img.bmp',9,1,2,2,scale_x=0.3,scale_y=0.3)
#保存文件
wb.save('file.xls')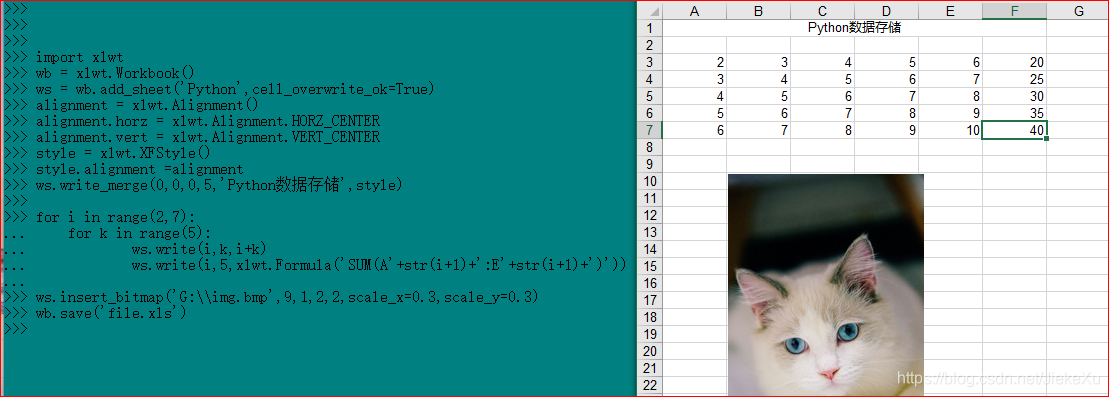
Excel中还有其他的单元格颜色,单元格边框,字体颜色,字体大小,数据类型等等,这里就不展开描述了,下面来看看Excel读取数据。
读取数据需要第三方库 xlrd 来实现,具体代码如下。
import xlrd
wb = xlrd.open_workbook('file.xls')
#获取工作簿的zongshu
ws_count = wb.nsheets
print('Sheets总数:',ws_count)
#通过索引顺序获取Sheets
#ws = wb.sheets() [0]
#ws = wb.sheet_by_index(0)
#通过Sheets名获取Sheets
ws = wb.sheet_by_name('Python')
#获取整行的值,以列表形式返回
row_value = ws.row_values(3)
print('第四行数据为:',row_value)
#获取整列的值,以列表形式返回
row_col = ws.col_values(3)
print('D列的数据为:',row_col)
#获取所有的lie
nrows = ws.nrows
ncols = ws.ncols
print('总行数为:',nrows,'总列数为:',ncols)
#获取某个单元格内容cell(行,列)
cell_F3 = ws.cell(2,5).value
print('F3单元格内容为:',cell_F3)
#使用行列索引获取某个单元格的内容
row_F3 = ws.row(2)[5].value
col_F3 = ws.col(5)[2].value
print('F3单元格的内容为:',row_F3, 'n' 'F3单元格的内容为:',col_F3)
看到这里,顺便在说一下怎么把数据存储到Word中,Word文档中存储的一般为文章、新闻报道和小说这类文字内容较长的数据。
Word数据存储
Python读取Word也是需要第三方扩展库来支持,使用pip install python-docx安装即可。
下面通过例子说明怎么使用Python读取数据吧,废话不多说,直接看代码。
from docx import Document
from docx.shared import Inches
#创建对象
document = Document()
#添加标题,其中'0'代表标题类型,一共有4种类型,具体可在Word的开始菜单,样式下查看
document.add_heading('Python爬虫基础学习',0)
#添加正文内容并设置部分内容格式
p = document.add_paragraph('Python爬虫-')
#设置内容加粗
p.runs[0].bold = True
#添加内容并加粗
p.add_run('数据存储-').bold = True
#添加内容
p.add_run('Word-')
#添加内容并设置为斜体
p.add_run('存储实例。').italic = True
#添加正文,设置“样式”——> "明显引用"
document.add_paragraph(“样式-明显引用”,style = 'IntenseQuote')
#添加正文,设置“项目符号”
document.add_paragraph(
'项目符号1',style = 'ListBullet'
)
document.add_paragraph(
'项目符号2',style = 'ListNumber'
)
#添加图片
document.add_picture('G:\img.bmp',width = Inches(1.25))
#添加表格
table = document.add_table(rows = 1, cols = 3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for item in range(2):
row_cells = table.add_row().cells
row_cells[0].text = 'a'
row_cells[1].text = 'b'
row_cells[2].text = 'c'
#保存文件
document.add_page_break()
document.save('test.docx')通过以上代码便将数据写入到Word,最终结果如下图所示.
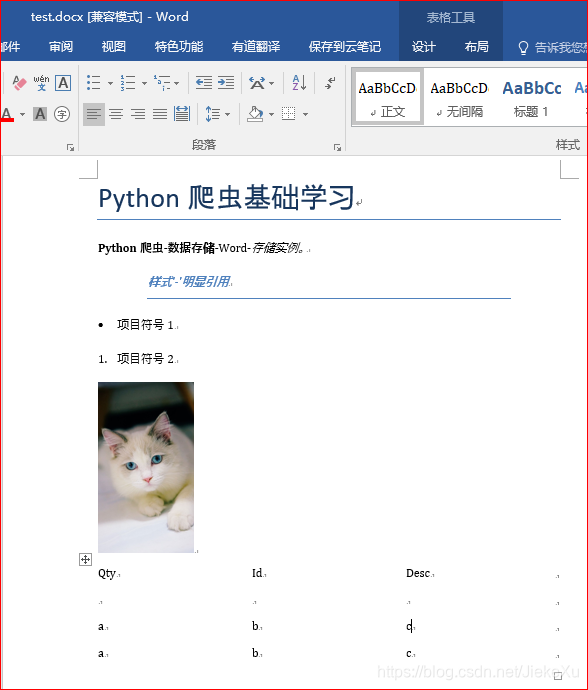
最后在看一眼怎么读取Words文件数据,这个就相对比较简单了,不用设置格式,直接读取即可,代码如下所示。
#读取数据
import docx
def readDocx(docName):
fullText = []
doc = docx.Document(docName)
#读取全部内容
paras = doc.paragraphs
#将每行数据存储到列表
for p in paras:
fullText.append(p.text)
#将列表数据转换成字符串
return 'n'.join(fullText)
print(readDocx('test.docx'))
通过上图看出,Word中的图片以及表格使用此方法是没法读取的,还是不尽如人意啊!
那么本周分享就到这里了,内容有点多,慢慢消化哦,下次分享怎么将数据存储到MySQL和Oracle数据库,小伙伴们准备好小板凳继续加油哦!!!
参考资料:黄永祥.清华大学出版社《玩转Python网络爬虫》第九章.文档数据存储
▼往期精彩回顾▼
Windows环境下基于Anaconda的Python3安装
使用Python爬取《悲伤逆流成河》猫眼信息
(端午节福利)各大影视VIP解析视频观看方法
推荐一个好用的PDF阅读器—悦书阅读器
Windows激活破解以及office安装破解
使用Python将图片变成铅笔素描
欢迎关注此公众号,写作不易,您的关注与点赞将是我不断写作的动力,点击最上方蓝字关注我吧!如果觉得此文对您有帮助,欢迎点赞、分享、转发!

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
