社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬虫作为一个敏感技术,千万要把握好,如果人家不让爬那就不要头铁去试了
在域名后面加上/robots.txt查看即可,例如:
https://blog.csdn.net/robots.txt
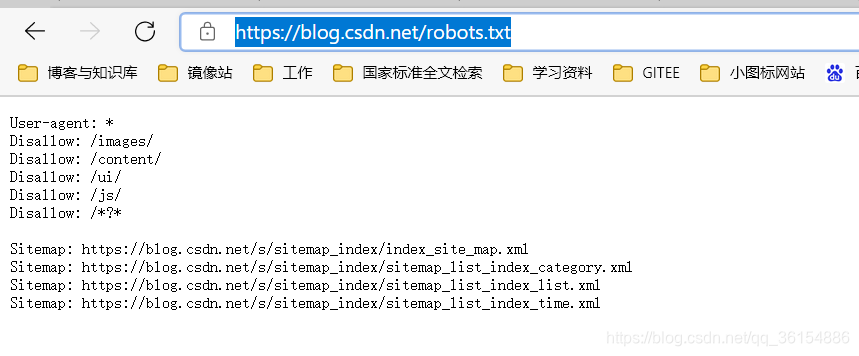
不能爬取的网站目录:
- /images/
- /content/
- /ui /
- /js/
- 包含❓的URL地址
其他地址可以爬取且允许任意方式爬取
所以只是爬取文章的话问题不大
爬取的文章:Linux通过chrony进行时间同步
h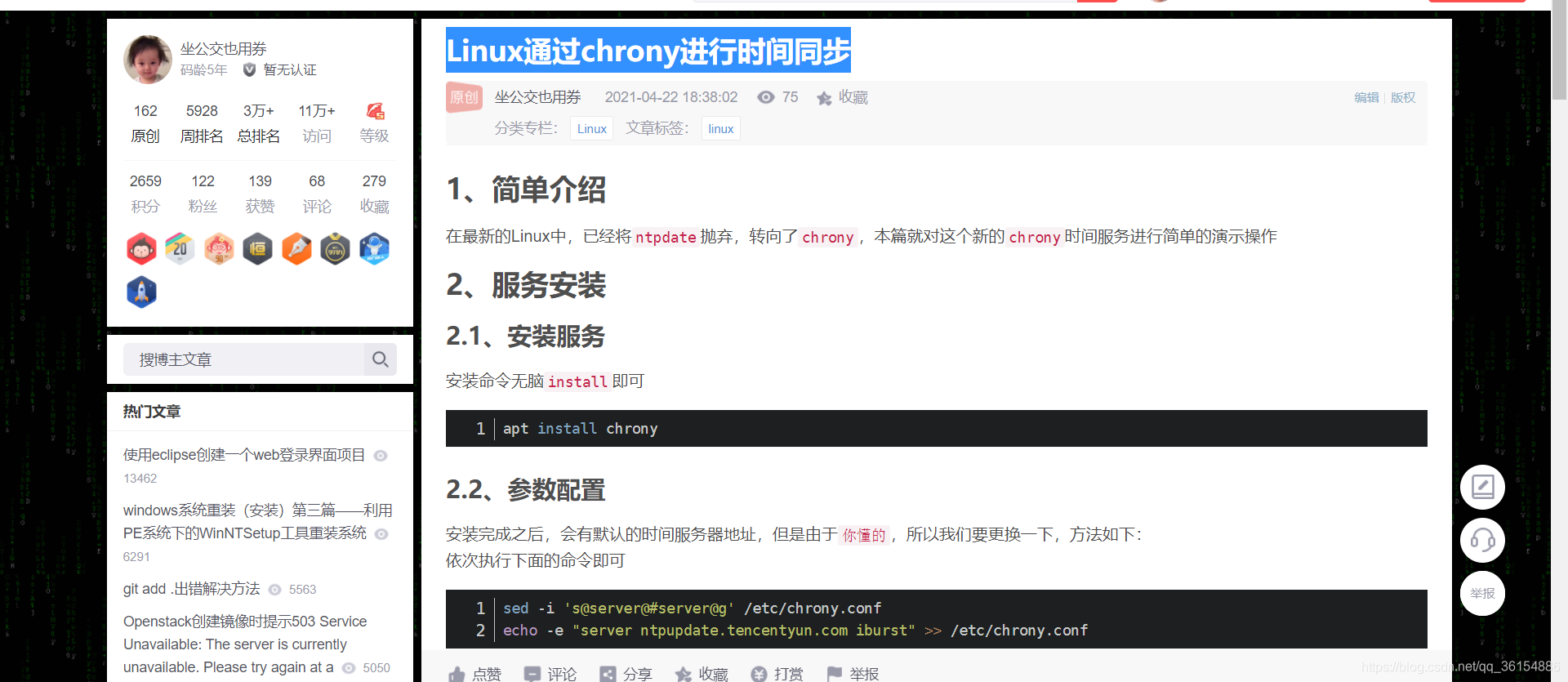

import requests
from os import path
import re
from requests_html import HTML
import json
from bs4 import BeautifulSoup
class csdn:
def __init__(self, user, head):
"""
初始化请求参数
:param user: CSDN用户ID
:param head: 访问请求头
"""
self.useinfo = user
self.url = f"https://blog.csdn.net/{user}?type=blog"
self.head = head
def write_md(self,file,txt):
"""
写入文本内容到文件
:param file: 文件名
:param txt: 文本内容
:return: 写入结果
"""
try:
with open(file, 'w', encoding='utf-8') as f:
f.write(txt)
return f"{file}写入: 成功"
except:
return f"{file}写入: 失败"
def get_status(self):
"""
对URL进行访问测试
:return: 访问结果
"""
get = requests.get(url=self.url, headers=self.head)
self.get = get
if get.status_code == 200:
print(f'访问请求成功')
return True
else:
print(f"访问请求失败")
return False
def get_list(self):
"""
获取该用户所有文章列表
:return: 返回列表信息
"""
# get = requests.get(url=self.url, headers=self.head)
self.get.encoding = 'utf-8'
text = self.get.text
list = BeautifulSoup(text, 'html.parser')
# print(list)
title_list = list.find_all('h4')
url = list.find_all('a')
txt_id = str(title_list[0]).split('=')[0].split(' ')[1]
# print(txt_id)
rule = re.compile(r'qq_36154886')
i = str(url[40])
print(i)
# print(i.split(self.url)[0])
# print(re.findall(rule, i))
# Get_url = str(i)
# print(Get_url)
# print(title_list)
print(txt_id)
# print(txt_id)
# print(re.match(txt_id, text).group())
# print(title_list[1])
sum = len(title_list) # 统计当前文章数量
print(f"当前主页共有: {sum} 篇文章")
print("获取到的文章列表如下:")
for tile in title_list:
tit = str(tile).split('">')[1].split('<')[0]
print(tit)
def doc(self, title='Linux通过chrony进行时间同步', url='https://blog.csdn.net/qq_36154886/article/details/116025999'):
"""
爬取单篇文章内容
:param title: 文章标题
:param url:
:return: str(文章内容)
"""
file = f"{title}.md"
get = requests.get(url=url, headers=self.head)
if get.status_code == 200:
print(f"结果: [ {title} ]请求成功")
else:
print(f"结果: [ {title} ]请求失败")
return False
get.encoding = get.apparent_encoding
# print(get.text)
soup = BeautifulSoup(get.text, 'lxml')
text_list = soup.find('div', "markdown_views prism-tomorrow-night")
info = ""
for i in text_list:
info = f"{str(info)} {i}"
info = re.sub(r'.*svg.*', '', info)
info = re.sub(r'.*svg.*', '', info)
info = re.sub(r'<path.*', '', info)
# 转换菜单
info = re.sub(r'<h1><a id=".*"></a>', '# ', info)
info = re.sub(r'<h2><a id=".*"></a>', '## ', info)
info = re.sub(r'<h3><a id=".*"></a>', '### ', info)
info = re.sub(r'</h.*>', '', info)
# 转换正文
info = re.sub(r'<.*p>', '', info)
# 转换代码块(bash)
# 判断代码类型
# print(i)
get = re.search(r'(.*)<pre><code class="prism language(.*)"><', string=str(i))
# 判断是否存在代码块
if get:
# 判断编程类型
# print(f"存在代码: {i}")
code_type = get.group().split('-')[1].replace('">', '').replace('<', '')
# print(f"代码类型: {code_type}")
# d = input('dd')
# print(f"替换: rf'<pre><code class="prism language-{code_type}">'")
info = re.sub(rf'(.*)<pre><code(.*)language-{code_type}">', f'```{code_type}n', info)
# info = re.sub(r' <pre><code class="prism language-bash">', '```bashn', info)
info = re.sub(r' ```', '```', info)
info = re.sub(r'</code></pre>', '```n', info)
# info = re.sub(r'</span>', '', info)
info = re.sub(r'<pre><code class="prism language-bash"><span class="token function">', '', info)
info = re.sub(r'</span>', '', info)
info = re.sub(r'</code></pre>', f'```n', info)
# info = re.sub(r'<pre><code class="prism language-bash"><span class="token function">', '```bashn', info)
info = re.sub(r"""<span class="token string">""", ' ', info)
info = re.sub(r"""<span class="token function">""", '', info)
info = re.sub(r"""<span class="token keyword">""", '', info)
info = re.sub(r"""<span class="token operator">""", '', info)
info = re.sub(r"""<span class="token comment">""", '', info)
info = re.sub(r"""<pre><code class="prism language-bash">""", '```bashn', info)
info = re.sub(r'>', '>', info)
status = up.write_md(file=file, txt=info)
print(status)
# 变量赋值
Headers = {"accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding" : "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "max-age=0",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.39}'
}
user = 'qq_36154886'
# head = 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.39'
# 开始实例化
up = csdn(user=user, head=Headers)
up.doc()
# get = up.get_status() # 获取请求状态
# if get:
# print('开始获取文章列表')
# up.get_list()
# else:
# exit('请检查用户ID是否有误或者网络是否通畅')
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
