社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在这一章,你将会走完一个完整的机器学习项目。主要步骤如下:
上一篇写了1和2,这篇来写后面的。(怎么感觉这篇也写不完???哈哈哈算了先写着吧)
通过数据可视化来得到对数据潜在规律的一些思考:
上一篇文章我们已经对数据集有了大致的了解,第三步我们要做的是把测试集扔在一边不要管,然后来探索一下训练集的数据潜在逻辑,我们复制一份训练集数据以免破坏原数据:
housing = strat_train_set.copy()
我们观察到数据集中包含了一个地理信息(经纬度),让我们可视化来看看: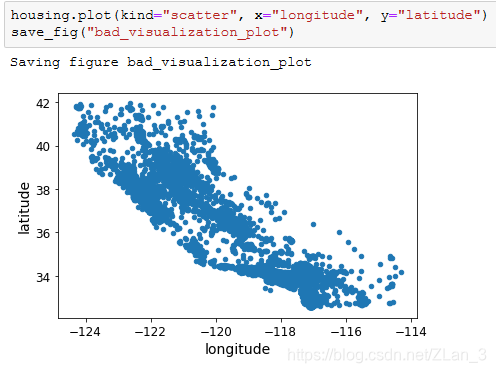
这样其实还是不好分辨他的分布规律,我们可以设置参数 alpha: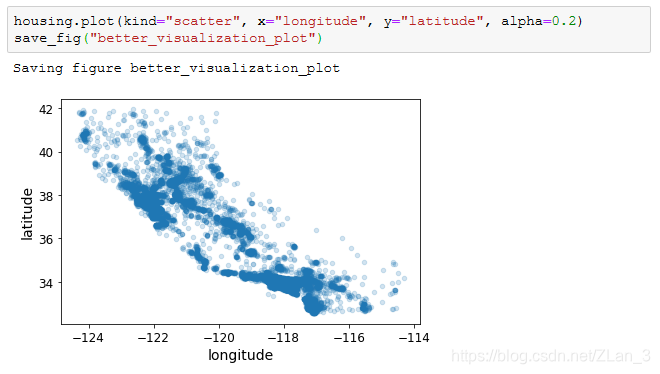
我这里的 alpha 设置的是0.2,原书是0.1,大家可以自己试试别的数值,越接近零,透明度越高;设置了 alpha 以后,分布规律就变得很显然了,颜色深的地方密度更大。
现在我们加入更多的属性来看,设置每个圆点半径表示某地区的人口,圆点颜色表示房价,用一个定义好的colormap(jet)来表示房价的高低:
这一轮探索让我们发现房价跟地理位置以及人口数量的关系。
接下来我们进一步探索属性之间的相关性,可以用 corr() 方法来简单的计算 Pearson 相关系数,然后查看每个属性与房价的相关性: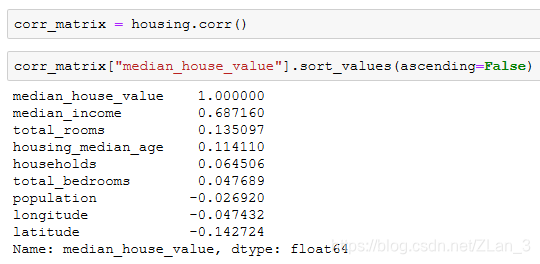
能看到中值收入(median_income)跟房价的相关性很高。
另一种查看相关性的方法是用 Pandas 库的 scatter_matrix 函数,它会画出每个数值型属性之间的散点图,因为属性太多,我们只选择几个相关度较高的属性来进一步探索: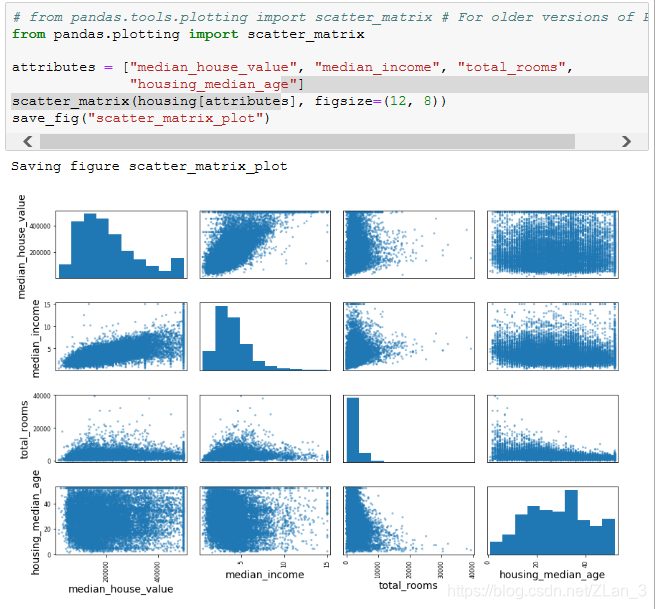
对角线上如果画出散点图应该是一条直线,就没什么意义,所以 Pandas 就画出该属性的直方图来替代。从上面的散点图来看,很显然是中值收入(median_income)跟房价的相关性最高,所以接下来我们专注于这一个属性来进行探索: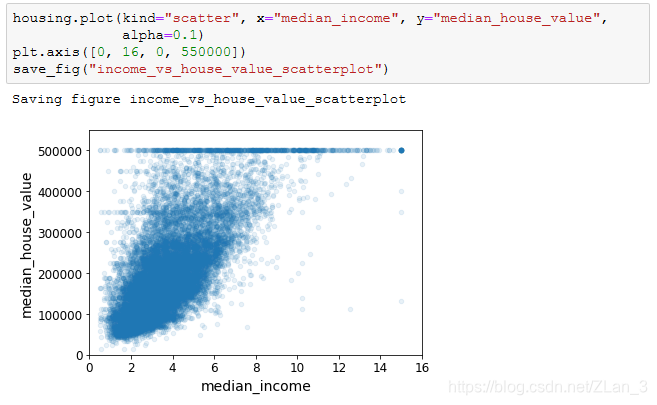
可以看到收入和房价的相关度很高,散点图中点比较聚集,呈现正向趋势;并且房价有一个很明显的上限在 $500000 左右,除此之外,其实我们也能发现在 $450000 和 $350000 的位置也有一条水平线,后来的这两条水平线很有可能是我们想要消除的数据噪音,这一点有待大家深入探索。
在进行数据预处理前我们的最后一步是尝试去组合出新的特征,在这个例子中,我们可能会想要用总房间数(total_rooms)和房屋数(households)组合出每个房屋的房间数量(rooms_per_household),还有类似的每个房间的卧室数量(bedrooms_per_room),每个房屋的人数(population_per_household)等,下面我们来尝试组合出这些特征并查看分析他们与房价的相关性: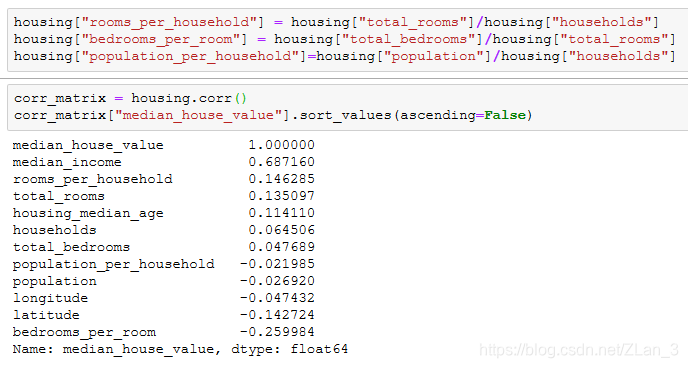
看起来还不错,新特征每个房间的卧室数量(bedrooms_per_room)与房价的相关度比房间总数以及卧室总数都要高,呈现的是负相关;每个房屋的房间数量(rooms_per_household)与房价的相关度也明显比组合前要高。
在训练模型之前先对数据进行预处理:
处理之前我们先把训练集的特征和标签(房价)分离开:
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
之前我们发现属性 total_bedrooms 有一些空值,我们有三个方法来解决这个问题;一是删除有空值的行,二是删除有空值的列(这里就是删除total_bedrooms这一列),三是给空值填充一些合适的值(例如零值、平均值、中值等):
housing.dropna(subset=["total_bedrooms"]) #方法一 删除有空值的行
housing.drop("total_bedrooms",axis=1) #方法二 删除有空值的列
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) #方法三 给空值填充一些合适的值
如果我们选择第三种方法,要记得把中值保存以便后续给测试集填充。
sklearn 提供了一个类 Imputer 让我们更方便的填充空值: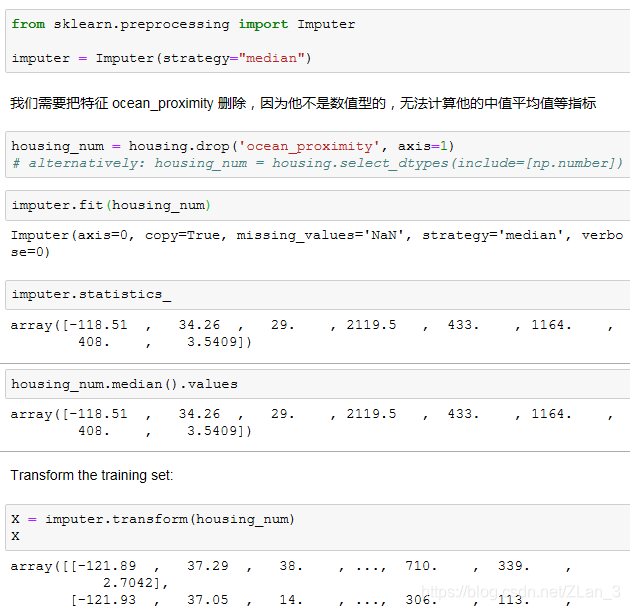
我们可以看到,我们先是创建了一个类 Imputer,然后用它去 fit 我们的数据集,fit 以后的这个 Imputer 就从数据集中学习到了一些参数,这时候就可以用来 transform 了;这是 sklearn 库的统一的接口设计。
transform 之后我们得到的值是 Numpy 的 array 类型,我们可以转化成 Pandas 的 Dataframe 类型:
housing_tr = pd.DataFrame(X, colums=housing_num.colums)
接下来我们来看一下怎么处理文本型或者确定类别型属性。
我们需要先把这些属性转化成数值,sklearn 提供了 LabelEncoder 类: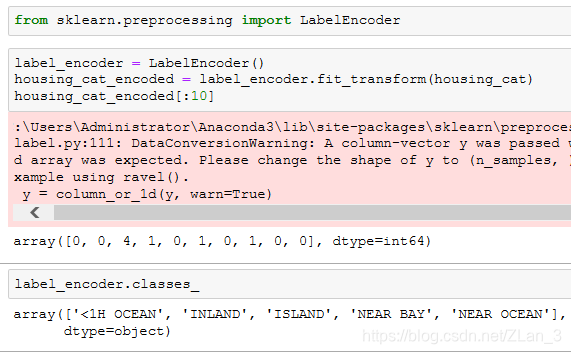
这个例子中,’<1H OCEAN’ 被编码为0,'INLAND’为1,'ISLAND’为2,'NEAR BAY’为3,‘NEAR OCEAN’为4。
但是用这个方法有个问题,机器学习算法通常认为数值相近表示这两个属性相似,但事实上用以上方法编码并不能表示这一点;sklearn 提供了另一个类 OneHotEncoder 来做二分类解决这个问题,它使用的是独热编码(one-hot encoding),它编码出来的是一个矩阵: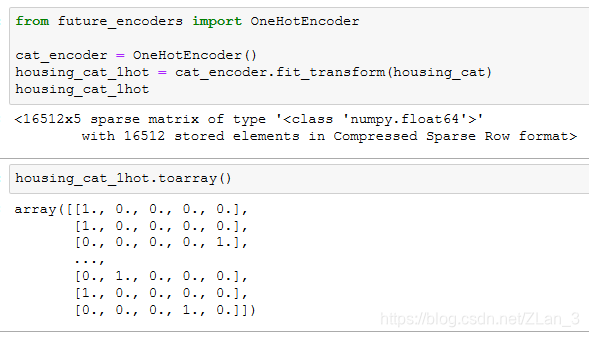
我们得到的是一个稀疏矩阵,每行只有一个1,表示在这个位置的值是存在的,其他都是零表示其他都不存在。例如第一行就表示’<1H OCEAN’为1,‘INLAND’、’‘ISLAND’、‘NEAR BAY’、'NEAR OCEAN’都为0。
sklearn 还提供了一个类可以一步解决上面的两步: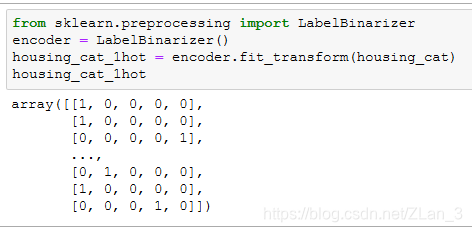
虽然 sklearn 提供了很多转换函数(transformers),但有时我们还是需要自定义我们自己的 transformer,比如之前我们尝试的构造新的属性或者自定义的数据清洗。为了跟 sklearn 其他类或函数无缝结合(可以互相调用),我们自定义的类应该包含三个方法:fit(),transform(),fit_transform()(如果你使用 TransformerMixin 作为基类就可以不用手动定义第三个方法 fit_transform),同时也建议使用 BaseEstimator 作为基类,那你就会获得两个方法(get_params() 和 set_params()),这两个方法能帮助你调节超参数。现在,让我们来自定义一个类组合出新的特征:
这个类即实现了我们之前尝试的三个新组合的特征:每个房屋的房间数量(rooms_per_household),每个房间的卧室数量(bedrooms_per_room),每个房屋的人数(population_per_household)。在这里我们的超参数是是否要添加新特征每个房间的卧室数量(bedrooms_per_room),你还可以设置其他超参数,大家可以自由探索。
接下来是数据预处理里最重要的一步转换:特征缩放(feature scaling)。由于不同特征有不同的尺度,机器学习算法面对这些不同尺度的特征总是不能表现的很好;比如,在本书的房价预测例子中,总房间数尺度为6-39320,而中值收入的尺度为0-15;我们需要使得这些特征尺度一致,才能让我们的算法更好的做预测。
Min-Max 归一化是比较简单的一种,数值被线性的缩放到0-1;sklearn 提供了一个类 MinMaxScaler 实现这个转换,你可以调节超参数 feature_range 实现别的范围(如果你不想要0-1)。
标准化(standardization)可以使得特征值的平均值为零,并且方差为单位方差。标准化不会把值限制在0-1,这有时候可能是个问题(神经网络常常需要0-1的输入值);但标准化是更稳固的,他不容易受到异常值的影响,所以标准化应用相对广泛些。
最后,我们可以利用 sklearn 提供的 Pipeline 类把之前做的所有的数据预处理过程封装为一个转换流程(原书写的是 transformation pipeline,我也不知道该怎么翻译合适,大家明白就好)。下面给了一个例子,把之前我们提的三个过程封装起来了(用中值填充特征空值,组合出新的特征,标准化特征):
在这个 pipeline 里,你开始 fit 的时候,他就会按照顺序首先训练第一个 tranformer 并把参数传给下一个,依次进行。
这样你可以一次性处理完所有的数值型特征,但是如果你要同时处理类别型特征呢?sklearn 提供了一个 FeatureUnion 类,它允许你把多个 transformer 或 pipeline 组合起来,调用 transform 的时候所有的 transformer 会同时运行,等结果出来以后再将所有的结果连接起来。下面的例子是把我们之前的数值型的 pipeline 和类别型的编码转换器组合起来: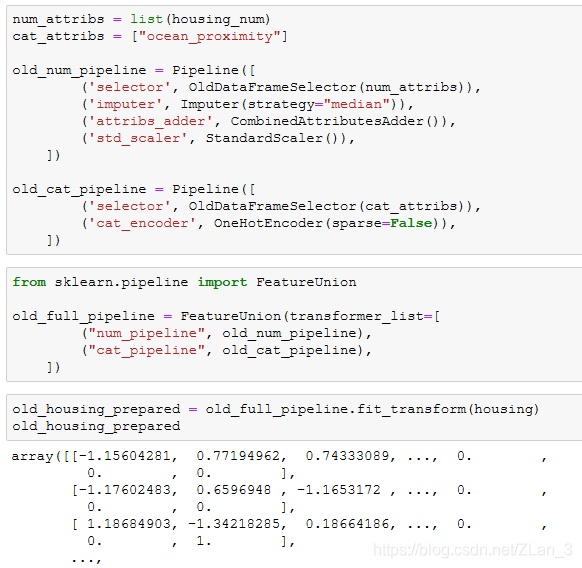
这篇写完了3和4啦,下篇应该是真的可以写完这一章了。。。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
