社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
根据自己写的上一篇文章,我继续更第二部分的内容,详情请点击如下链接
【python】爬虫篇:python连接postgresql(一):https://blog.csdn.net/lsr40/article/details/83311860
在上一篇文章中我们可以拿到一个叫做rows的对象,这个对象就是数据库里一条一条的数据,因此需要遍历每一条数据,然后打开url拿到html的页面信息再做解析。
1、遍历rows
遍历就不用说了吧,for row in rows....
2、通过urllib打开页面(当然也有其他的框架,比如requests)
这个说一点:
# 当我如下的方式运行代码的时候,有时候程序会假死
# 就是突然卡主,然后什么都不做
file = urllib.request.urlopen(url)
# 因此要这么写,给定一个超时时间,如果请求不到就直接跳过了
file = urllib.request.urlopen(url,timeout=5)3、对于获得的页面html做解析
解析是这样的,我测试了下我的电脑上运行,差不多1s,可以跑完两条查到数据库。然后bs4和xpath的速度没有什么特别大的区别,但是xpath确实会快一点。
当我使用bs4的时候遇到RecursionError: maximum recursion depth exceeded in comparison这样的报错,原因可以看https://blog.csdn.net/cliviabao/article/details/79927186(cliviabao的原创文章),报错解释如下:
file = urllib.request.urlopen(row[2],timeout=5)
try:
data = file.read() # 读取全部
soup = BeautifulSoup(data.decode('utf-8'), 'html.parser')
# 就是在find_all报了错,因此我想这样遍历应该是递归遍历,层数太深
result = soup.find_all('p', text=True)
# 解决方法有两种:第一种(治标不治本,叫做把递归层数增加)
import sys
sys.setrecursionlimit(100000) #例如这里设置为十万
# 第二种:避免这种错误的查找,比如你想找一个div,他的class名字叫正文,而且通篇只有这个一个,那么
# 所以可以去找找find_all可传入的参数
result = soup.find_all(name='div', attrs={"class": "zhengwen"}, limit=1)
另一种就是xpath,有几点说明一下:
1、有时候可能会被封ip,虽然爬虫却还在爬着数据,不过这些数据肯定都是有问题的,所以要加一个标识,发现爬到的页面发现ip已经被封了,可以发送警报,并且插到数据库的数据就加上某个被封的标识,用来下次重跑这部分数据。
2、有个小插曲,被封了ip之后我怎么都无法通过xpath的方法来判断被封了(因为被封的消息并不是直接写在html的标签里面的,而是在js中write的),所以我只能用python中str的find方法来判断是否被封(可以添加偏移量,不从头开始遍历字符串)
find方法的使用:http://www.runoob.com/python/att-string-find.html
3、关于xpath的使用方法:
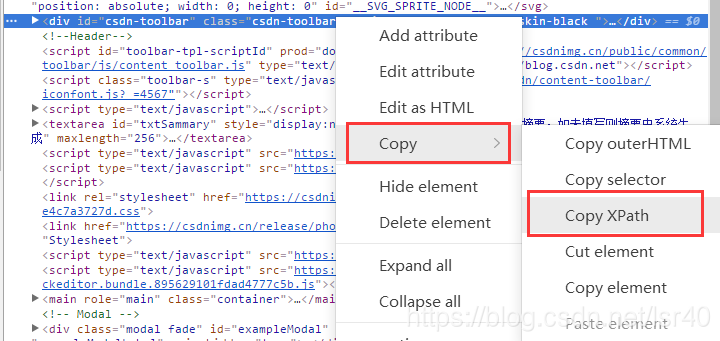
大家可以百度些文章自己学着写写,或者直接打开网页,F12进入到开发者模式,找到你要的那部分网页信息在哪个标签中,接下来复制出来他的xpath,如下两图所示,复制出来会类似这种东西//*[@id="csdn-toolbar"]就可以直接使用了!

代码如下:
try:
file = urllib.request.urlopen(url,timeout=5)
data = file.read() # 读取全部
#这里可以添加上判断是否被封号的标志,如果被封号就发提醒,或者在插入数据库的时候表示下,这数据采集的时候已经被封ip了,所以得重新采集这部分被封ip的数据
isBan=str(data).find('xxx', 3000)
if(isBan!=-1):
string='ip被封'
else:
selector = etree.HTML(data)
data = selector.xpath('//*[@id="js_content"]/p/span/text()')
for i in data:
if (i != None):
string = string + i # .replace(''', '''''')
4、关于速度
当然爬虫的速度是非常需要关注的一个点!首先肯定是越快越好,但是不同网站会做不同的黑名单机制,也就是说你访问的太快有可能会直接被封ip,因此就需要一台可以自动换ip的服务器,当然这就不在讨论这段代码的范畴之内了。
在这里,我只考虑的如何加快爬虫的速度!!
我就想到两种方法:
1、多线程(一段代码里开启多个线程,同时访问不同页面)
2、多进程(运行多个python脚本,来达到同时访问不同页面)
我选用第一种方式(完整代码):
# 这里的productList方法只实现了获取页面具体的内容,还缺少将获取到的数据插入数据库的实现,未完待续!
def productList(rows):
string=''
try:
file = urllib.request.urlopen(url,timeout=5)
data = file.read() # 读取全部
isBan=str(data).find('xxx', 3000)
if(isBan!=-1):
string='ip被封'
else:
selector = etree.HTML(data)
data = selector.xpath('//*[@id="js_content"]/p/span/text()')
for i in data:
if (i != None):
string = string + i # .replace(''', '''''')
except Exception as e:
# e.partial 这个属性据说是报错的时候已经接受的html内容,没有实际测试过
data = '代码异常'
print('Error', e)
if __name__ == '__main__':
conn_1 = psycopg2.connect(database="数据库", user="用户", password="密码",
host="ip",
port="端口")
cur1 = conn_1.cursor()
# 查出url
sql1 = "select xxx from xxx"
cur1.execute(sql1)
rows = cur1.fetchall()
print('拉取到数据')
# 这里就是开启10个线程来跑productList方法,并且我考虑到了需要批量插入数据,因此一次性往线程中传入10条url,然后将10条url一起插入数据库(其实可以更多条一起插入)
with ThreadPoolExecutor(10) as executor:
for i in range(0, len(rows)//10, 1):
executor.submit(productList, rows[i*10:(i+1)*10])
# 结束关闭连接
conn_1.close()
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
