社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
技术的运用可以解决大量重复处理的工作,提高效率。
比如,有大量的论文电子文档(.docx格式),需要提取文档中的题目、作者、单位等信息制成表格(.xlsx格式),一般每篇论文的题目在第1行,副标题在第2行(如果有的话),作者及单位信息在接下来的第3行、第4行。如下图所示。

如果文件非常多,手动复制、粘贴的话,会比较繁琐费时。我们可以通过找出规律,用python实现自动提取。
代码如下(readWord.py文件):

#####readWord.py#####
import docx,os,openpyxl
dirpath = './'
list = []
desfile = 'desfile.xlsx'
#创建excel文件
hxlsx = openpyxl.Workbook()
sheet = hxlsx.active
sheet.append(['序号','题目','作者','单位','文件名'])
#读取指定目录'docx'文件
files = os.listdir(dirpath)
i = 0
for file in files:
number = 0
if file[-5:] == '.docx':
i += 1
hfile = docx.Document(file)
if hfile.paragraphs[0].text == '':#题目上面有1个空行
number = 1;
title = hfile.paragraphs[number].text.strip()
if hfile.paragraphs[number+1].text[:2] == '——':#题目下面有副标题
title += hfile.paragraphs[number+1].text.strip()
number += 1
if hfile.paragraphs[number+1].text == '':#作者上面有1个空行
number += 1
author = hfile.paragraphs[number+1].text.strip()
custom = hfile.paragraphs[number+2].text.strip()
custom = custom.strip('(')
custom = custom.strip('(')
custom = custom.strip(')')
custom = custom.strip(')')
#追加插入序号、题目、作者、单位信息、文件名相应内容
sheet.append([i,title,author,custom,file])
print('finish')
hxlsx.save(desfile)
#####end#####
docx、openpyxl模块分别实现对word、excel文件的操作,如果没有安装的话,需要先进行安装。
windows系统在cmd命令行下,分别输入:
pip install python-docx
pip install openpyxl
效果如下图:
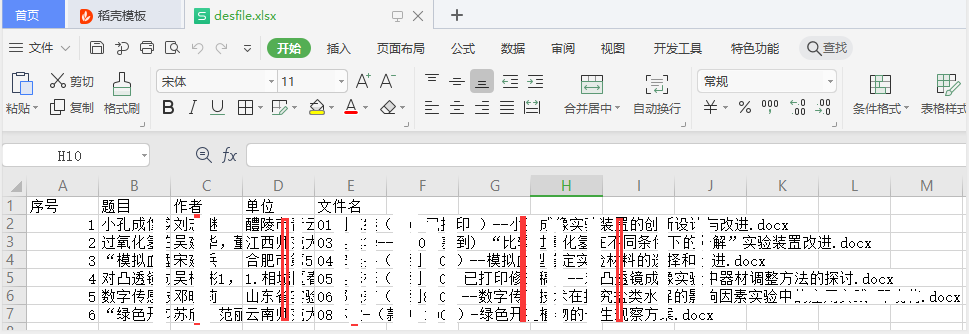
接下来,测试前述功能代码的效果。readWord.py遍历当前目录下所有".docx"论文文件,提取文件中前面几行中的论文题目、作者、单位信息,并导出到" desfile.xlsx"文件。实现效果如下图所示:

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
