社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
(滑动向下?)
▼
弗兰克(妇男科):学习遇到问题了吗?
张三:没有
Frankie:视频加载倒计时3.2.1
不要瞎练,请找弗兰克(妇男科)!
微信:gdkj1111
或者长按识别!

了解了程序如何运行,我们就可以让我们写的程序变得更快。
介绍
在前面很长一段时间,我们学习建立一个搜索索引,它可以通过一次一次地查看每个条目来响应查询。
当搜索索引检查关键字与我们要找的词相匹配时,就会把结果打印出来。
但是,如果索引很大很大,查询次数很多很多,这种方法就会太慢。
一个典型的商用的搜索引擎应该在一秒钟内做出响应,甚至还会快得多。
在接下来的几篇文章,我们将学习如何使我们的搜索索引更快。
让事情变得更快的办法
这几篇文章最主要目标是让大家了解程序的运行成本。
到此刻为止,我们还没有担心过这个问题,那是我们写的都是最简单的代码,如果程序的代码足够大的时候,或者让程序运行更多的事情的时候,我们就必须开始考虑运行它们的成本。
这个评估一个执行的成本是一个非常重要的问题,它是计算机科学的一个基本问题。有些人整个职业生涯都在研究这个问题。这就是所谓的算法分析。
在看我写的公号过程中,你可能没有意识到这一点,但实际你完整学习的话,已经写了很多算法。
算法是一个输入某些东西,然后让计算机产生正确结果的程序。
一个程序是一个逻辑清晰的步骤序列,它可以机械地执行。
我们主要对可以被计算机执行的程序感兴趣,但它之所以成为程序,重要的部分在于它的步骤是精确定义的,不需要思考就可以执行。
要成为一个算法,它必须总是完成。也就是说它必须要有输出。
你已经看到,要确定一个算法是否总有输出,这不是一个简单的问题。
一般来说,不可能回答这个问题,在现实世界,你永远无法给出下一秒的准确预测,明天的输出需要明天到来之后,才能观察到。
但对于计算机的程序来说,给定一个输入,必须要有一个输出的结果,哪怕是个错误的结果。
所以,一旦你有了一个算法,然后你用逻辑清晰定义了实现的步骤,那么它就会产生正确的结果。
这也意味着你可以通过统计每段过程,对它的成本进行推理。
什么是成本?
计算机科学家思考成本的方式与大多数人思考成本的方式完全不同。
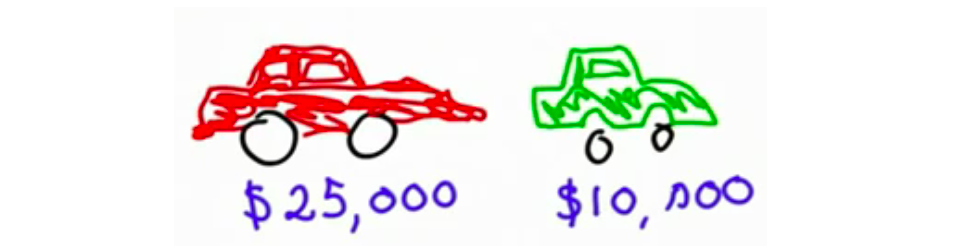
当你考虑到东西的成本时,你就会知道具体的东西,比如红车要25000元,绿车要10000元--红车比绿车贵。
你只要比较这些成本就可以了。这是以非常具体的事物与具体的成本来思考的。
用算法就不一样了。我们通常不会有一个具体的执行思路。成本取决于投入。
假设 算法A 和 算法B 都解决同一个问题。
输入 算法A 输出
输入 算法B 输出
你不能像汽车那样给它们定一个固定的价格。
对于某些输入,可能 算法A 比 算法B 便宜,但对于其他输入,算法B 可能更便宜。
你不希望对每一个输入都要进行计算。
在计算机科学中,成本的主要方式是以输入的大小来谈论的。
通常情况下,输入的大小是决定算法速度的主要因素。
通俗的来说,计算中的成本是以时间如何随着输入的大小增加而增加来衡量。
有时,输入的其他属性也很重要,这在后面会提到。最终,成本总是归结为钱。
当算法执行时,什么是需要花钱的?
完成的时间--如果它完成得更快,你就会花更少的时间在它身上。你可以按执行时间来租用电脑。有各种云计算服务,你按使用时间支付一定大小的处理器的费用。这只是几分钱每小时。时间真的是金钱,虽然我们不需要把成本变成金钱,因为我们可能不知道确切的计算成本,但了解执行时间就能很好地了解成本。
内存--如果执行一个算法需要一定的内存,那么你就可以知道运行程序所需的计算机大小和成本。
总而言之,成本是以时间和记忆而不是以金钱来谈论的;尽管这些的实际实施确实会转化为实际的金钱成本。时间往往是成本的最重要方面,但记忆也是另一个考虑因素。
为什么计算机科学家专注于测量时间随输入大小而变化,而不是绝对时间?
我们想在运行一个程序之前,预测它的执行时间。
我们想知道随着计算机的速度越来越快,时间将如何变化。
我们想了解算法的基本属性,而不是特定输入或机器的东西。
我们想要抽象的答案,所以它们永远不会错。
纵观整个计算的历史,一年后用同样的钱能买到的计算机会比今天能买到的计算机快。
程序运行的时间
下面我们将学习如何检查一段代码运行所需的时间。
下面的存储过程time_execution就是一种评估代码执行所需时间的一种方法。
你可以尝试用秒表来做,但是为了准确,你必须运行程序很长时间。
使用 time 时间库中内置的 time_execution() 更准确。代码后面有注释。
import time #这是一个Python库def time_execution(code): start = time.monotonic() # 启动时钟,返回的时钟的浮点数值 result = eval(code) # 把任何字符串当作Python命令来计算。 run_time = time.monotonic() - start # 找出开始时间和结束时间的差异。 return result, run_time # 返回代码结果和所需时间Jupyter中的执行过程:
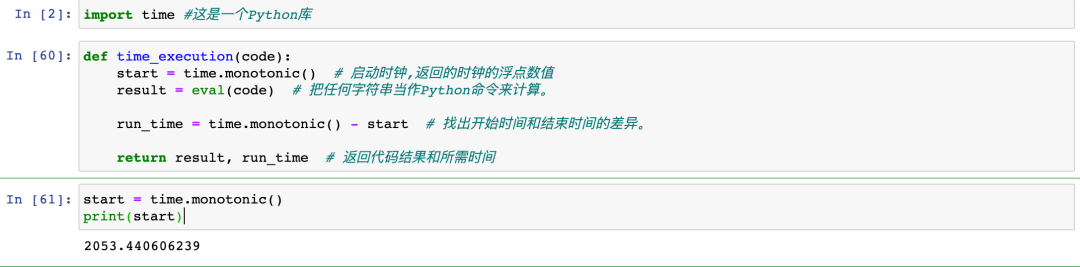
时钟已经启动。它开始时读取的时间有些随意,但这并不重要,因为你只对它开始和停止的时间差感兴趣,而不是绝对的开始和结束时间。
时钟启动后,你要评估的代码会被执行。这是由相当令人兴奋的方法eval('code')完成的。它允许你以字符串的形式运行任何输入的代码!你输入一个字符串,它就会运行。
你输入一个字符串,它就会把它作为 Python 代码运行。例如,eval('1 + 1') 运行代码 1 + 1。
代码执行完毕后,时钟停止,计算开始和停止时间的差值,并存储为run_time。
最后,过程在eval中返回代码的结果及其运行时间。

你可以通过web解释器来运行计时,但它不会是准确的,而且你的代码在那里运行的时间是有限制的。
如果你的电脑上安装了Python,你就可以在上面运行。
如果你还没有安装Python,尽快安装。
只要动手自己做一遍,才是最快速的学习方式。
上面的输出代码都是Frankie在他的Mac anaconda里的Jupyter notebook中运行的。
回顾一下,time_execution 的输入 "1 + 1",被作为输入发送给 eval ,然后它以 Python 代码的形式运行 1 + 1。
运行时间用科学记数法写成:(2, 1.7687999843474245e-05)
你可以通过观察 e 后面的 -5 来了解它的来源,它告诉你把小数点向左移动 5 步,就像这样。
单位是秒,所以这是毫秒的一小部分,也就是0.017毫秒左右。
反复尝试同一条指令,由于同一时间机器里有其他事情在进行,所以结果会有所不同,但都是同一个值左右。
如果你试着尝试更大的数字,时间还是非常非常小的。
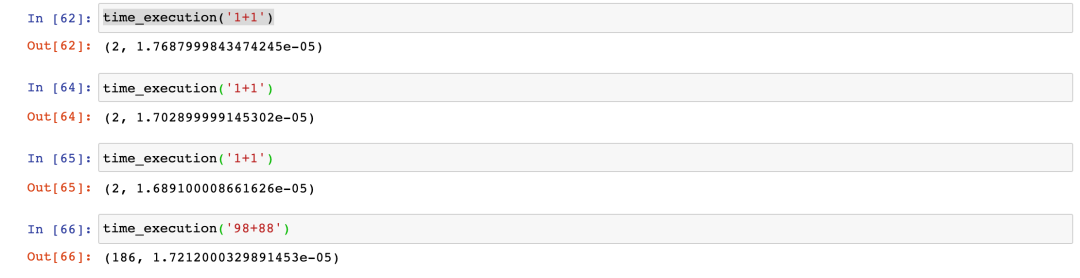
实际的处理时间还会更低,因为,启动和停止时钟等都算入到时间里面了。
对于这种很小的代码的执行来说,这并不能说明什么。
所以接下来的文章,你会看到一些较长的模块它的执行时间。关注编程联盟,继续学习了解更多的内容。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
