社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
从工作机制上来说,Zk = 文件系统 + 通知机制
想个哨兵一样,它负责存储和管理大家都关心的数据,然后接收观察者的注册,一旦这些数据的状态发生变化,Zk 就通知已经在Zookeeper 已经注册的观察者做出相应的反应。
1. Zk 的数据结构是树,同样数据结构的还有 linux 文件系统和 hdfs 文件系统。
2. 基于 Zookeeper 实现分布式锁
基于 zookeeper 实现分布式锁的方案,由于zookeeper 有以下特点:
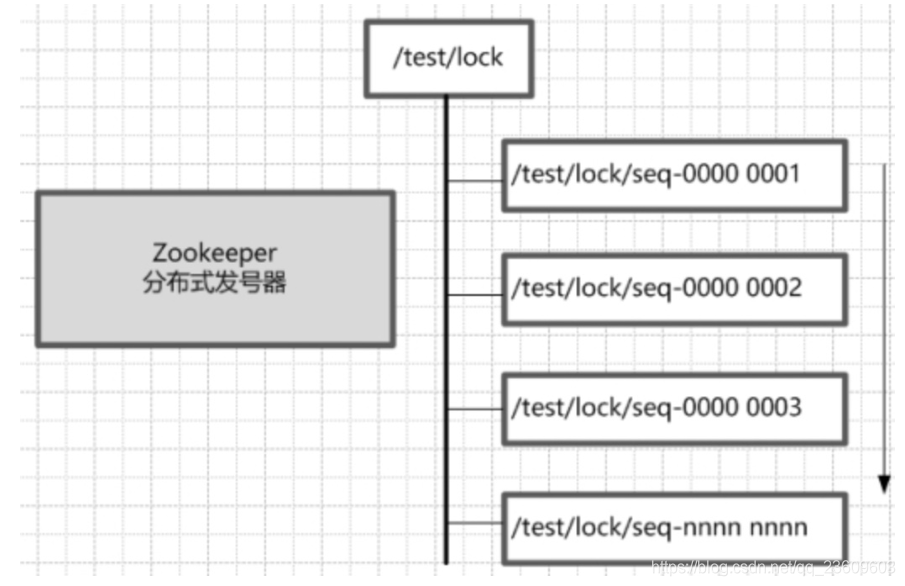
问题来了:讲一下如何用 zookeeper 实现分布式锁?
三个步骤:加锁 -》 获取锁-》 释放锁
3. 展开讲下 ZK 的 leader 选举机制
(1) 主要基于半数机制:集群中半数以上的机器存活,就认为集群可用,所以 Zk 适合装在奇数台机器上,Zk选举最少需要三台机器,最少需要两台运行良好的机器,这样三台哪怕挂掉一台机器,也能选出leader。
(2)哪些情况下需要进行选举?并描述选举过程
<1> 服务器初始化启动时,需要选取 leader
<2> 服务器运行期间无法和leader 保持连接
对于情况一:这里以一个简单的例子说明整个选举流程,假设五台服务器组成 Zk 集群,他们的 id 为 1 ~ 5 ,它们都是最新启动的,没有什么历史数据,假设这些服务器依次启动:
开始:
a. 服务器 1 启动,发起一次选举,投自己一票,此时服务器 1 票数 为1,不够半数 3 以上,选举无法完成,服务器 1 保持 为Looking (它的票可以在接下来的轮次中可以投给别人)
b. 服务器 2 启动,再发起一次选举, 服务器 1 投自己, 服务器 2 投自己,二者交换投票选票信息,此时服务器 1 发现 服务器 2 的 id 比自己大,所以改投给服务器 2 ,此时 服务器1为 0 票,服务器 2 为 2 票,但是不大于半数,所以,leader 没被选出来, 服务器 1 , 2 保持为 Looking 状态
c. 服务器 3 启动,发起一轮投票,此时 服务器 1 ,2 都改投服务器 3 ,服务器 3 为 3票,超过 半数,所以 服务器3 成为leader ,服务器 1,2 的状态更改为 Folowing, 服务器 3 更改为 Leading .
d.服务器 4 启动,发起投票,此时 1 2 3 已经不在时 Looking 状态,不会更改投票信息,交换投票信息后,服务器少数服从多数,改投 3 ,并更改状态为 Following
e. 服务器 5 启动,和 4 一样,少数服从多数。
leader 的选举保证了集群全局数据一致性。
(3)基于它的集群管理?zookeeper的注册(watch)机制和轮询机制的使用场景?
描述一下 Zk 的 注册(watch)机制:基于 Zk 上创建的节点,可以对这些节点绑定监听事件,比如监听节点的数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于Zookeeper 实现分布式锁、集群管理如 集群节点的动态上下线检测、统一命名服务、统一配置管理、转负载均衡。
这里以服务器的动态上下线为例:
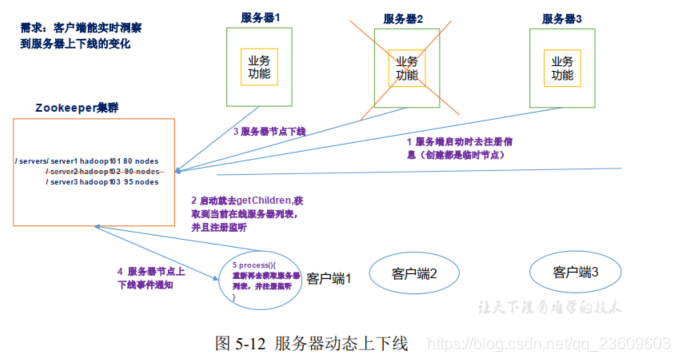

<1> 部署方式有两种:单机模式,集群模式
<2>角色: follower 和 leader
<3>最少需要三台机器,至少两台正常工作
ls、ls2、create、delete、get、set
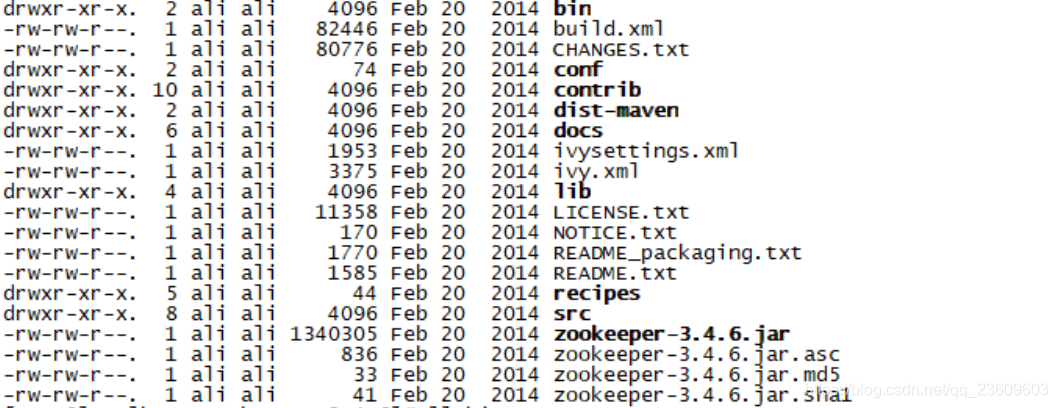
主要有 bin 目录:存放可执行文件、conf:存放配置文件、contrib:存放扩展包、lib:存放 jar 包,src:存放源码
数据存储可分为:1.内存存储 2.磁盘存储
Zk 的数据模型是树结构,在内存数据库中,存储了整棵树的内容,包括 所有的节点路径、节点数据、ACL(权限信息)、Zookeeper 会定时把这个数据存储在从磁盘上。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
