社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
转自:https://zhuanlan.zhihu.com/p/38440477
https://www.cnblogs.com/wzdLY/p/9853209.html
https://github.com/Lucky-Bone/Discretization
https://blog.csdn.net/SkullSky/article/details/105646062
WOE:
WOE的全称是“Weight of Evidence”,即证据权重,WOE是对原始自变量的一种编码形式。要对一个变量进行WOE编码,需要首先把这个变量进行分箱。分箱后,对于第i组,WOE的计算公式如下:
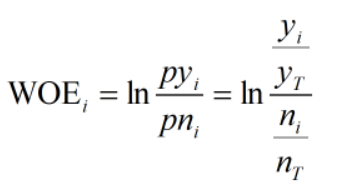
yi是这个分组中响应客户(即取值为1)的数量,yT是全部样本中所有响应客户(即取值为1)的数量
ni是这个分组中未响应客户(即取值为0)的数量,nT是全部样本中所有未响应客户(即取值为0)的数量
IV值:
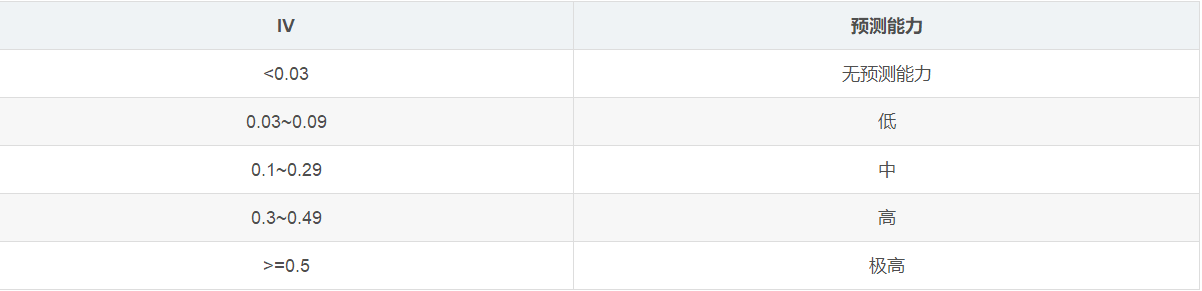
IV的全称是Information Value,用来衡量自变量的预测能力
对于分组i的IV值:
![]()
计算整个变量的IV值,n为变量分组个数:
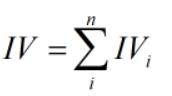
IV值(Information Value)
在机器学习的二分类问题中,IV值(Information Value)主要用来对输入变量进行编码和预测能力评估。特征变量IV值的大小即表示该变量预测能力的强弱,在面对大量变量的情况下,可计算各个变量的IV值,取IV值大于某个固定值的变量参与到模型中去,这样不仅保留了特征携带的信息量。且提高了模型效率,此外有利于给客户解释和汇报。
数据分箱的重要性及优势:
def bin_frequency(x,y,n=10): # x为待分箱的变量,y为target变量.n为分箱数量
total = y.count() # 计算总样本数
bad = y.sum() # 计算坏样本数
good = y.count()-y.sum() # 计算好样本数
d1 = pd.DataFrame({'x':x,'y':y,'bucket':pd.qcut(x,n)}) # 用pd.cut实现等频分箱
d2 = d1.groupby('bucket',as_index=True) # 按照分箱结果进行分组聚合
d3 = pd.DataFrame(d2.x.min(),columns=['min_bin'])
d3['min_bin'] = d2.x.min() # 箱体的左边界
d3['max_bin'] = d2.x.max() # 箱体的右边界
d3['bad'] = d2.y.sum() # 每个箱体中坏样本的数量
d3['total'] = d2.y.count() # 每个箱体的总样本数
d3['bad_rate'] = d3['bad']/d3['total'] # 每个箱体中坏样本所占总样本数的比例
d3['badattr'] = d3['bad']/bad # 每个箱体中坏样本所占坏样本总数的比例
d3['goodattr'] = (d3['total'] - d3['bad'])/good # 每个箱体中好样本所占好样本总数的比例
d3['woe'] = np.log(d3['goodattr']/d3['badattr']) # 计算每个箱体的woe值
iv = ((d3['goodattr']-d3['badattr'])*d3['woe']).sum() # 计算变量的iv值
d4 = (d3.sort_values(by='min_bin')).reset_index(drop=True) # 对箱体从大到小进行排序
print('分箱结果:')
print(d4)
print('IV值为:')
print(iv)
cut = []
cut.append(float('-inf'))
for i in d4.min_bin:
cut.append(i)
cut.append(float('inf'))
woe = list(d4['woe'].round(3))
return d4,iv,cut,woe2. 等距分箱:从最小值到最大值之间,均分为 N 等份。 如果 A,B 为最小最大值, 则每个区间的长度为 W=(B−A)/N , 则区间边界值为A+W,A+2W,….A+(N−1)W 。这里只考虑边界,每个等份的实例数量可能不等。
def bin_distince(x,y,n=10): # x为待分箱的变量,y为target变量.n为分箱数量
total = y.count() # 计算总样本数
bad = y.sum() # 计算坏样本数
good = y.count()-y.sum() # 计算好样本数
d1 = pd.DataFrame({'x':x,'y':y,'bucket':pd.cut(x,n)}) #利用pd.cut实现等距分箱
d2 = d1.groupby('bucket',as_index=True) # 按照分箱结果进行分组聚合
d3 = pd.DataFrame(d2.x.min(),columns=['min_bin'])
d3['min_bin'] = d2.x.min() # 箱体的左边界
d3['max_bin'] = d2.x.max() # 箱体的右边界
d3['bad'] = d2.y.sum() # 每个箱体中坏样本的数量
d3['total'] = d2.y.count() # 每个箱体的总样本数
d3['bad_rate'] = d3['bad']/d3['total'] # 每个箱体中坏样本所占总样本数的比例
d3['badattr'] = d3['bad']/bad # 每个箱体中坏样本所占坏样本总数的比例
d3['goodattr'] = (d3['total'] - d3['bad'])/good # 每个箱体中好样本所占好样本总数的比例
d3['woe'] = np.log(d3['goodattr']/d3['badattr']) # 计算每个箱体的woe值
iv = ((d3['goodattr']-d3['badattr'])*d3['woe']).sum() # 计算变量的iv值
d4 = (d3.sort_values(by='min_bin')).reset_index(drop=True) # 对箱体从大到小进行排序
print('分箱结果:')
print(d4)
print('IV值为:')
print(iv)
cut = []
cut.append(float('-inf'))
for i in d4.min_bin:
cut.append(i)
cut.append(float('inf'))
woe = list(d4['woe'].round(3))
return d4,iv,cut,woe3. 自定义分箱:
def bin_self(x,y,cut): # x为待分箱的变量,y为target变量,cut为自定义的分箱(list)
total = y.count() # 计算总样本数
bad = y.sum() # 计算坏样本数
good = y.count()-y.sum() # 计算好样本数
d1 = pd.DataFrame({'x':x,'y':y,'bucket':pd.cut(x,cut)})
d2 = d1.groupby('bucket',as_index=True) # 按照分箱结果进行分组聚合
d3 = pd.DataFrame(d2.x.min(),columns=['min_bin'])
d3['min_bin'] = d2.x.min() # 箱体的左边界
d3['max_bin'] = d2.x.max() # 箱体的右边界
d3['bad'] = d2.y.sum() # 每个箱体中坏样本的数量
d3['total'] = d2.y.count() # 每个箱体的总样本数
d3['bad_rate'] = d3['bad']/d3['total'] # 每个箱体中坏样本所占总样本数的比例
d3['badattr'] = d3['bad']/bad # 每个箱体中坏样本所占坏样本总数的比例
d3['goodattr'] = (d3['total'] - d3['bad'])/good # 每个箱体中好样本所占好样本总数的比例
d3['woe'] = np.log(d3['goodattr']/d3['badattr']) # 计算每个箱体的woe值
iv = ((d3['goodattr']-d3['badattr'])*d3['woe']).sum() # 计算变量的iv值
d4 = (d3.sort_values(by='min_bin')).reset_index(drop=True) # 对箱体从大到小进行排序
print('分箱结果:')
print(d4)
print('IV值为:')
print(iv)
woe = list(d4['woe'].round(3))
return d4,iv,woe
def chi_bins(df,col,target,confidence=3.841,bins=20): # 设定自由度为1,卡方阈值为3.841,最大分箱数20
total = df.target.count() #计算总样本数
bad = df.target.sum() # 计算坏样本总数
good = total - bad # 计算好样本总数
total_bin = df.groupby([col])[target].count() # 计算每个箱体总样本数
total_bin_table = pd.DataFrame({'total':total_bin}) #创建一个数据框保存结果
bad_bin = df.groupby([col])[target].sum() # 计算每个箱体的坏样本数
bad_bin_table = pd.DataFrame({'bad':bad_bin}) #创建一个数据框保存结果
regroup = pd.merge(total_bin_table,bad_bin_table,left_index=True,right_index=True,how='inner') #组合total_bin 和 bad_bin
regroup.reset_index(inplace=True)
regroup['good'] = regroup['total']-regroup['bad'] #计算每个箱体的好样本数
regroup = regroup.drop(['total'],axis=1) #删除total
np_regroup = np.array(regroup) # 将regroup转为numpy
# 处理连续没有正样本和负样本的区间,进行合并,以免卡方报错
i = 0
while (i <= np_regroup.shape[0] - 2):
if ((np_regroup[i, 1] == 0 and np_regroup[i + 1, 1] == 0) or ( np_regroup[i, 2] == 0 and np_regroup[i + 1, 2] == 0)):
np_regroup[i, 1] = np_regroup[i, 1] + np_regroup[i + 1, 1] # 正样本
np_regroup[i, 2] = np_regroup[i, 2] + np_regroup[i + 1, 2] # 负样本
np_regroup[i, 0] = np_regroup[i + 1, 0]
np_regroup = np.delete(np_regroup, i + 1, 0)
i = i - 1
i = i + 1
# 对相邻两个区间的值进行卡方计算
chi_table = np.array([]) # 创建一个数组保存相邻两个区间的卡方值
for i in np.arange(np_regroup.shape[0]-1):
chi = ((np_regroup[i,1]*np_regroup[i+1,2]-np_regroup[i,2]*np_regroup[i+1,1])**2*
(np_regroup[i,1]+np_regroup[i,2]+np_regroup[i+1,1]+np_regroup[i+1,2]))/
((np_regroup[i,1]+np_regroup[i,2])*(np_regroup[i+1,1]+np_regroup[i+1,2])*
(np_regroup[i,1]+np_regroup[i+1,1])*(np_regroup[i,2]+np_regroup[i+1,2]))
chi_table = np.append(chi_table,chi)
# 将卡方值最小的两个区间进行合并
while(1): #除非设置break,否则会一直循环下去
if(len(chi_table)<=(bins-1) or min(chi_table)>=confidence):
break # 当chi_table的值个数小于等于(箱体数-1) 或 最小的卡方值大于等于卡方阈值时,循环停止
chi_min_index = np.where(chi_table = min(chi_min_index))[0] # 找出卡方最小值的索引
np_regroup[chi_min_index,1] = np_regroup[chi_min_index,1] + np_regroup[chi_min_index+1,1]
np_regroup[chi_min_index,2] = np_regroup[chi_min_index,2] + np_regroup[chi_min_index+1,2]
np_regroup[chi_min_index,0] = np_regroup[chi_min_index+1,0]
np_regroup = np.delete(np_regroup,chi_min_index+1,axis=0)
if (chi_min_index == np_regroup.shape[0]-1): # 当卡方最小值是最后两个区间时,计算当前区间和前一个区间的卡方值并替换
chi_table[chi_min_index-1] = ((np_regroup[chi_min_index-1,1]*np_regroup[chi_min_index,2]-np_regroup[chi_min_index-1,2]
*np_regroup[chi_min_index,1])**2*(np_regroup[chi_min_index-1,1]+np_regroup[chi_min_index-1,2]
+np_regroup[chi_min_index,1]+np_regroup[chi_min_index,2]))/((np_regroup[chi_min_index-1,1]+
np_regroup[chi_min_index-1,2])*(np_regroup[chi_min_index,1]+np_regroup[chi_min_index,2])*
(np_regroup[chi_min_index-1,1]+np_regroup[chi_min_index,1])*(np_regroup[chi_min_index-1,2]+
np_regroup[chi_min_index,2]))
chi_table = np.delete(chi_table,chi_min_index,axis=0) #删除替换前的卡方值
else:
# 计算合并后当前区间和前一个区间的卡方值并替换
chi_table[chi_min_index-1] = ((np_regroup[chi_min_index-1,1]*np_regroup[chi_min_index,2]-np_regroup[chi_min_index-1,2]
*np_regroup[chi_min_index,1])**2*(np_regroup[chi_min_index-1,1]+np_regroup[chi_min_index-1,2]
+np_regroup[chi_min_index,1]+np_regroup[chi_min_index,2]))/((np_regroup[chi_min_index-1,1]+
np_regroup[chi_min_index-1,2])*(np_regroup[chi_min_index,1]+np_regroup[chi_min_index,2])*
(np_regroup[chi_min_index-1,1]+np_regroup[chi_min_index,1])*(np_regroup[chi_min_index-1,2]+
np_regroup[chi_min_index,2]))
# 计算合并后当前区间和后一个区间的卡方值并替换
chi_table[chi_min_index] = ((np_regroup[chi_min_index,1]*np_regroup[chi_min_index+1,2]-np_regroup[chi_min_index,2]
*np_regroup[chi_min_index+1,1])**2*(np_regroup[chi_min_index,1]+np_regroup[chi_min_index,2]
+np_regroup[chi_min_index+1,1]+np_regroup[chi_min_index+1,2]))/((np_regroup[chi_min_index,1]+
np_regroup[chi_min_index,2])*(np_regroup[chi_min_index+1,1]+np_regroup[chi_min_index+1,2])*
(np_regroup[chi_min_index,1]+np_regroup[chi_min_index+1,1])*(np_regroup[chi_min_index,2]+
np_regroup[chi_min_index+1,2]))
chi_table = np.delete(chi_table,chi_min_index+1,axis=0) #删除替换前的卡方值
# 将结果保存为一个数据框
result_data = pd.DataFrame()
result_data['col'] = [col]*np_regroup.shape[0] #结果第一列为变量名
list_temp=[] # 创建一个空白的分组列
for i in np.arange(np_regroup.shape[0]):
if i==0: # 当为第一个箱体时
x= '0' + ',' + str(np_regroup[i,0])
elif i == np_regroup.shape[0]-1: # 当为最后一个箱体时
x = str(np_regroup[i-1,0]) + '+'
else:
x = str(np_regroup[i-1,0]) + ',' + str(np_regroup[i,0])
list_temp.append(x)
result_data['bin'] = list_temp
result_data['bad'] = np_regroup[:,1]
result_data['good'] = np_regroup[:,2]
result_data['bad_rate'] = result_data['bad']/total #计算每个箱体坏样本所占总样本比例
result_data['badattr'] = result_data['bad']/bad #计算每个箱体坏样本所占坏样本总数的比例
result_data['goodattr'] = result_data['good']/good #计算每个箱体好样本所占好样本总数的比例
result_data['woe'] = np.log(result_data['goodattr']/result_data['badattr']) #计算每个箱体的woe值
iv = ((result_data['goodattr']-result_data['badattr'])*result_data['woe']).sum() #计算每个变量的iv值
print('分箱结果:')
print(result_data)
print('IV值为:')
print(iv)
return result_data,iv本人就职于某金融科技公司从事风控建模工作,欢迎交流。
对于风控和机器学习感兴趣的童鞋可以关注下我的公众号:风控汪的数据分析之路。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

