社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
当正负样本极度不均衡时存在问题!比如,正样本有99%时,分类器只要将所有样本划分为正样本就可以达到99%的准确率。但显然这个分类器是存在问题的。当正负样本不均衡时,常用的评价指标为ROC曲线和PR曲线。
概率模型:决策树、bayes、HMM、CRF、概率潜在语义分析、潜在狄利克雷分析lda、高斯混合模型(一定可以表示为联合概率分布的形式,)概率模型的代表是概率图模型,即联合概率分布由有向图或者无向图表示的模型,而联合概率可以根据图的结构分解为因子乘积的形式。Bayes,CRF,HMM都是概率图模型。
非概率模型:SVM、感知机、k近邻、k均值、潜在语义分析、NN、Adaboost,LR两者都有。
生成模型:HMM、navie bayes,可以还原出联合概率分布,收敛更快,存在隐变量依然可以用生成方法学习,
判别模型:k近邻、感知机、决策树、LR、最大熵、svm、CRF。往往学习准确率更高,可以进行各种成都上 的抽象,定义特征并使用特征,简化学习问题。
bayes估计:利用bayes定理,计算给定数据条件下的条件概率,即后验概率,取后验概率最大!
极大似然估计:频率学派,取能使概率最大的参数。
损失函数和风险函数:损失函数(代价函数)一次度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
损失函数:0-1,平方损失,绝对损失,对数(似然)损失
损失函数的期望就是理论上模型关于联合分布的平均意义下的损失,即风险函数,或期望损失。学习的目标就是选择期望风险最小的模型。
经验风险:关于数据集的平均风险
期望风险:模型关于联合分布的期望损失。
经验风险最小化:极大似然估计,当模型是条件概率分布,损失函数为对数损失,经验风险最小化等价于极大似然估计。当样本容量小,会产生过拟合
结构风险最小化:防止过拟合提出,等价于正则化,加入了正则化项。如bayes估计中的最大后验概率估计。
过拟合:模型参数过多,学习到了噪音,对训练数据预测很好,对位置数据很差,导致模型拟合能力下降。
欠拟合:模型过于简单,未学习到数据的较多特征,都很差。
决策树:表示给定特征条件下类的条件概率分布,包含特征选择,决策树生成,剪枝
熵:随机变量不确定性的度量。
条件商:已知随机变量X的条件下随机变量Y的不确定性,定义X条件下Y的条件概率分布的熵对X的数学期望。
信息增益(互信息):得知特征X的信息而使得y信息不确定性减少的程度。即:经验熵H(D)与H(D/A)之差。
信息增益比:其信息增益g(D,A)与训练集D关于特征A的值的熵HA(D)之比。
剪枝:通过优化函数考虑了减小模型复杂度,损失函数的极小化等价于正则化的极大似然估计。
ID 3 :选择信息增益最大的特征建立子节点,再递归调用上述方法,直至所有特征小于某阈值或没有,极大似然法。
C 4.5: 选择信息增益比最大的特征建立子节点,再递归调用上述方法,直至所有特征小于某阈值或没有,极大似然法。
CART :Gini 指数最小化准则(经A=a分割后的不确定性)。平方误差损失,启发式,最小二乘回归树。二分类gini = 2p(1-p)
最大熵模型:熵最大的模型是最好的模型,在约束条件下,在没有更多信息情况下,那些不确定部分是等可能的,极大似然估计,LR和最大熵都归结为以似然函数为目标的最优化问题,它是光滑的凸函数,保证能找到全局最优解。
SVM:二分类模型,定义在特征空间上的间隔最大的分类器。学习策略就是间隔最大化,求解二次凸优化问题,等价于正则的合页损失函数的最小化问题,可分为线性可分,线性支持,非线性支持。不可分可用和技巧。
函数间隔:分类预测的正确性及确信度,除以范数变为几何间隔,
SVM学习的基本思路是求解能够正确划分训练集并且使几何间隔最大的分离超平面。在决定分离超平面时,只有SV起作用,,引入对偶问题往往更容易求解,其次可以推广到非线性分类问题。
线性不可分时,即不能满足函数间隔大于等于1,可引入松弛变量,软间隔最大,
引入核函数,将原空间变换映射到新空间,多项式,高斯核,
SMO:序列最小最优化算法。针对2个变量构建一个二次规划问题,不断分解为子问题并对子问题求解,包括求解2个变量二次规划问题及选择变量的启发式方法。选择第1个变量的过程是外层循环,寻找违反KKt条件最严重的点,第2个变量是内层循环,标准是能使这个变量有较大变化。每一次只学习基函数及系数。
Adaboost:提高被前一轮分类器错误分类样本的权值,降低正确分类的权值,加法模型,损失函数为指数函数,不用知道下界,采用前向分布算法。
提升树:平方损失(求导后,拟合残差了),指数损失,一般损失(不好优化计算)->
梯度提升树:最速下降法拟合残差的近似值,计算负梯度,拟合一个回归树。
EM:用于求解含有隐变量的概率模型参数的极大似然估计,或积大后验概率估计。Jenson不等式,求中点再log更大!
HMM:可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成不可观测的状态随机序列,
再由各个状态生成一个观测从而产生观测随机序列的过程,属于生成模型,是关于时序的概率模型。由初始概率分布,状态转移概率分布,观测概率分布决定,状态转移概率矩阵和初始的概率向量确定了隐藏的morkv连,生成不可观测的状态序列,观测矩阵确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
作了两个假设:1齐次马尔可夫假设:隐层的马尔可夫链在任意时刻只依赖与其前一时刻的状态,与其他时刻的状态无关,也与t时刻无关。2观测独立性假设:任意时刻的观测只依赖于该时刻的morkov链的状态,与其他观测及状态无关。
HMM3个基本问题:
1.概率计算问题:给定模型和观测序列,求在模型下观测序列O出现的概率。直接计算1求状态序列概率,2求对固定的状态序列下观测的概率,3求状态序列和观测序列同时出现的联合概率,4对所有可能的状态序列求和。O(TN^T)掷出1,6,8的概率。
前向与后向算法:减小计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免重复计算。高效的关键是局部计算前向概率,利用路径结构将前向概率递推到全局。
2.学习问题:给定观测序列,估计模型参数,使得该模型下观测序列概率最大,即用极大似然概率方法估计参数。EM求隐变量。哪种筛子掷出的概率最大
3.预测问题(解码问题):已知模型和观测序列,求对给定观测序列条件概率P(I/O)最大的状态序列I。即给定观测序列,求最有可能的对应的状态序列。近似算法与维特比算法。反推出每种骰子是什么。
维特比:DP解HMM预测问题,基用动态规划求概率最大路径问题(最优路径),一条路径对应着一个状态序列。
CRF:给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成morkov随机场(概率无向图模型),由输入到输出的判别模型,形式为对数线性模型。学习方法通常是极大似然估计或正则化的极大似然估计。直接求条件概率分布的模型故为判别,使用特征函数更加抽象表达特征f(X,i,yi,yi-1)
成对morkov性:随机变量组条件下,随机变量Yu和Yv是独立的。
局部morkov:
全局morkov:
如果满足3个性质,即为概率无向图模型。
将概率无向图的联合概率分布表示为其最大团上的随机变量的函数的乘机形式的操作即为因子分解。
CRF预测问题:求非规划化概率最大的最有路径问题,不求和只需记录Max值和位置,根据最后节点向前回溯选取最佳路径。中途只保留最短路径。
CRF可看成是序列化的LR,都是判别式,LR不是用分类条件估计w,而是用了sum(wixi)近似估计,若将ak替换成f,则与crf一样!
如何从CRF到HMM?对于每个转移概率p(ti/ti-1),定义f(x,i,yi,yi-1)=1,yi=ti,yi-1=ti-1,权重为logp(ti=yi/ti-1=yi-1),对于每个f,同样操作就可以得到HMM!
闵可夫斯基距离:p=2欧式,p=1曼哈顿,p=无穷切比雪夫,
马哈拉诺比斯距离:距离越大,相似越小,
皮尔逊相关系数与余弦距离,修正后的余弦距离。皮与修在于中心化方式不同。
奇异值分解SVD:mxn=m阶正交矩阵、由降序排列的对角元素组成的mxn矩形对角矩阵、n阶正交矩阵。矩阵的奇异值分解一定存在,但不唯一,几何解释是可分解为三个简单的变换:一个坐标系的旋转或反射VT、一个坐标轴的缩放sum、另一个坐标系的旋转或反射U。可看作是矩阵压缩的一种方法。即用因子分解近似表示原始矩阵,是在平方损失意义下的最优U近似。正交矩阵同转置相乘为单位矩阵。紧奇异值分解为无损压缩,截断奇异值分解为有损压缩。U的列为左奇异,V的列为右奇异向量。
PCA:利用正交变换把线性相关变量表示的 观测数据转换为少数几个线性无关变量表示的数据,线性无关的变量为主成分,属于降维方法。
LSA潜在语义分析:无监督学习,通过矩阵分解发现文本与单词之间基于话题的语义关系。传统方法以单词向量表示文本语义内容,以单词向量空间度量表示文本之间的相似度。LSA采用了非概率的话题分析模型,将文本集合表示为单词-文本矩阵,对单词-文本矩阵进行SVD分解,从而得到划题空间,以及文本在话题向量空间的表示。
NMF非负矩阵分解:分解的矩阵非负,也用于话题分析。
PLSA:概率潜在语义分析:
LDA潜在狄利克雷分配:作为bayes学习的话题模型,是LSA,PLSA的扩展。lda的预测一个文档是输出的主题-文档的概率向量,就是说这个文档属于各个主题的概率向量。每个主题的含义是由你训练过程中得到的主题-词分布决定。比如预测一个文档的输出是(0.25,0.75),就是说这个文档中的内容25%属于第一个主题,75%属于第二个主题。每一个主题的具体含义就看主题-词分布中概率排的靠前的一些词语,大致是这样,预测过程是认为训练得到的主题-词分布不变,这个输出其实就是新文档对应于各个主题的采样概率。用最大似然计算出来的。输出的数字就是新样本在该主题分布下的概率,比如第一个主题数字为0.5,那么新样本内容在该主题下的概率就是百分之50。
总之,AdaBoost的主要思想就是在不改变训练数据的情况下,通过在迭代训练弱学习器中,不断提升被错分类样本的权重(也就是使被错分的样本在下一轮训练时得到更多的重视),不断减少正确分类样本的权重。最后通过加权线性组合M个弱分类器得到最终的分类器,正确率越高的弱分类器的投票权数越高,正确率低的弱分类器自然投票权数就低。集成学习,(就我目前所学习到的)主要可以分为三大类,Boosting, Bagging, Stacking。Boosting的代表有AdaBoost, gbdt, xgboost。而Bagging的代表则是随机森林 (Random Forest)。Stacking 的话,好像还没有著名的代表,可以视其为一种集成的套路。
首先,Boosting是一个迭代提升的过程,所以它肯定是串行的算法(尽管xgboost可以在节点分裂属性选择上做并行计算)。基于训练集,先训练弱学习器,然后根据前一个弱学习器分错的样本,改变样本的概率分布构成新的训练集,从而可以训练出一个更强的学习器。这样反复迭代提升,就能得到一系列分类器。最后,将这些分类器组合起来,就能构成一个很强的学习器。
给定一个二分类的训练数据集
T={(x1,y1),…,(xN,yN)}
其中,x_i 是n维的, 类标y_i={-1,+1}
AdaBoost算法的步骤:
(1) 初始化训练数据的权值分布:D1=(w11,…,wi1,…,w1N),w1i=1/N,i=1,2,…,N(即初始时,每个样本视为一样的)
(2) 对m=1,2,…,M
(2a) 对具有权值分布Dm的训练数据集学习,得到一个基本分类器Gm(x)
(2b) 计算Gm(x)在训练数据集上的分类错误率:em=P(Gm(xi)!=yi)
(2c) 根据分类错误率计算Gm(x)的加权系数:am
(2d) 根据加权系数更新训练数据集的权值分布Dm+1
(3)以上学到了M个“弱”学习器,将这M个弱学习器加权求和:f(x)=sum(am*Gm(x)),最终的分类器为G(x)=sign(f(x))
总之,AdaBoost的主要思想就是在不改变训练数据的情况下,通过在迭代训练弱学习器中,不断提升被错分类样本的权重(也就是使被错分的样本在下一轮训练时得到更多的重视),不断减少正确分类样本的权重。最后通过加权线性组合M个弱分类器得到最终的分类器,正确率越高的弱分类器的投票权数越高,正确率低的弱分类器自然投票权数就低。
GBDT的基本原理是boosting里面的 boosting tree(提升树),并使用gradient boost。GBDT中的树都是回归树,不是分类树 ,因为gradient boost 需要按照损失函数的梯度近似的拟合残差,这样拟合的是连续数值,因此只有回归树。Gradient Boosting是一种Boosting的方法,其与传统的Boosting的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boosting中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少,与传统Boosting对正确、错误样本进行加权有着很大的区别。这个梯度代表上一轮学习器损失函数对预测值求导。与Boosting Tree的区别:Boosting Tree的适合于损失函数为平方损失或者指数损失。而Gradient Boosting适合各类损失函数(损失函数为:平方损失则相当于Boosting Tree拟合残差、损失函数为:使用指数损失则可以近似于Adaboost,但树是回归树)
下面是完整的GBDT介绍。
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。**GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。**GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。
回归树总体流程类似于分类树,区别在于,回归树的每一个节点都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化平方误差。也就是被预测出错的人数越多,错的越离谱,平方误差就越大,通过最小化平方误差能够找到最可靠的分枝依据。分枝直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
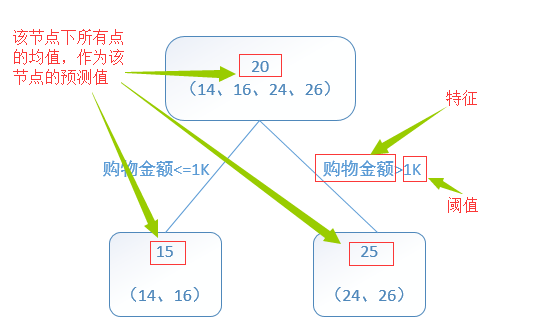
回归树算法如下图(截图来自《统计学习方法》5.5.1 CART生成):

请注意上图中的下标和上标,xixi表示第i个样本,x(j)x(j)表示该样本的第j个feature。所以上图中的遍历划分变量j的意思是遍历feature和相应的s,找出使平方误差和最小的(j,s)。
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式:残差 = 真实值 - 预测值 。提升树即是整个迭代过程生成的回归树的累加。
举个例子,参考自一篇博客(参考文献 4),该博客举出的例子较直观地展现出多棵决策树线性求和过程以及残差的意义。
训练一个提升树模型来预测年龄:
训练集是4个人,A,B,C,D年龄分别是14,16,24,26。样本中有购物金额、上网时长、经常到百度知道提问等特征。提升树的过程如下:
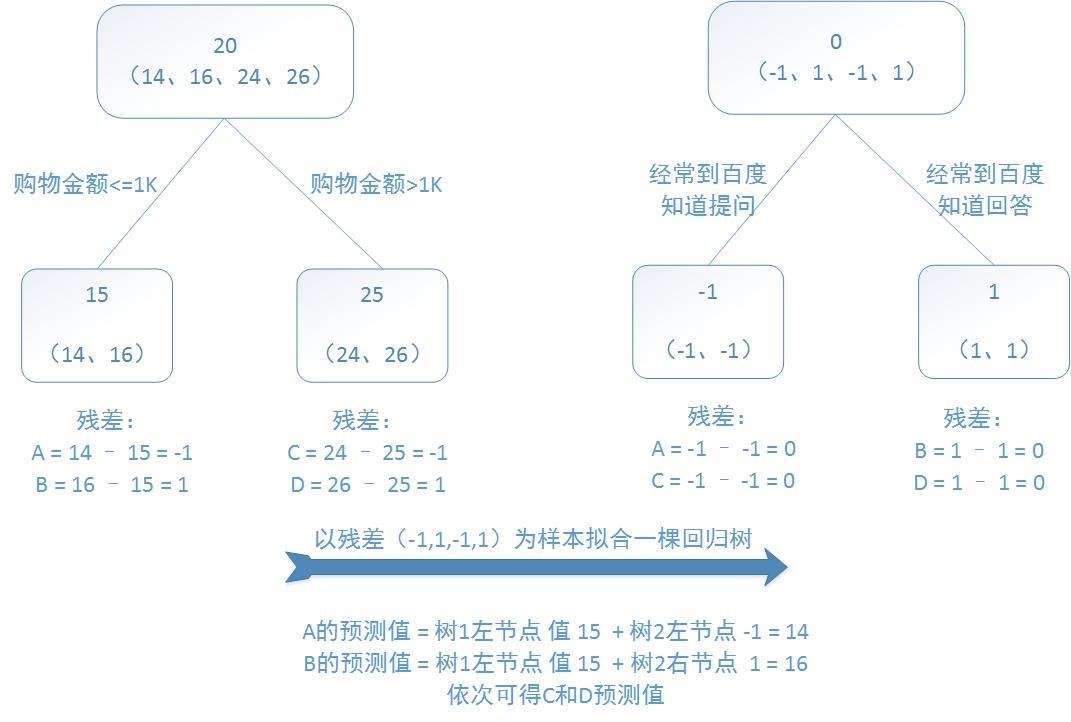
该例子很直观的能看到,预测值等于所有树值得累加,如A的预测值 = 树1左节点 值 15 + 树2左节点 -1 = 14。
因此,给定当前模型 fm-1(x),只需要简单的拟合当前模型的残差。现将回归问题的提升树算法叙述如下:

提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数是平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。

但对于一般的损失函数,往往每一步优化没那么容易,如上图中的绝对值损失函数和Huber损失函数。针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。(注:鄙人私以为,与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例)算法如下(截图来自《The Elements of Statistical Learning》):

xgboost类似于gbdt,但是很多地方经过了Tianqi Chen大牛的优化,因此不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:
1.损失函数是用泰勒展式二项逼近,而不是像gbdt里就是一阶导数
2.对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性
3.节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面所有的内容来自原始paper,包括公式。
(1) xgboost在目标函数中显示的**加上了正则化项,**基学习器为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
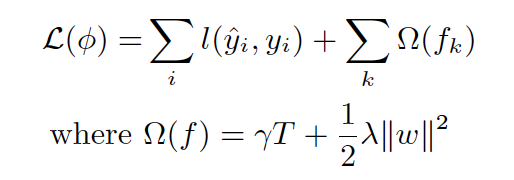
(2) GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。第t次的loss:
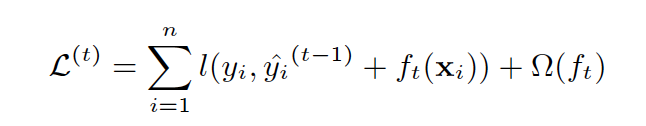
对上式做二阶泰勒展开:
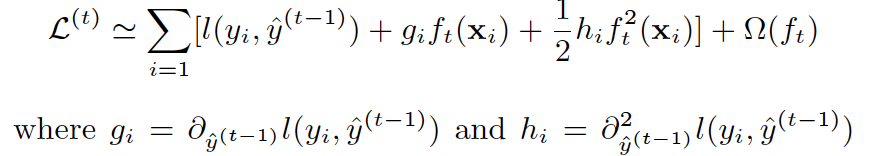
(3) 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化Lsplit
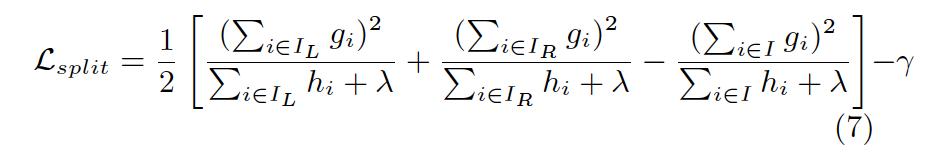
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
xgboost与gdbt除了上述三点的不同,xgboost在实现时还做了许多优化:
【问】xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
用xgboost/gbdt在在调参的时候把树的最大深度调成6就有很高的精度了。但是用DecisionTree/RandomForest的时候需要把树的深度调到15或更高。用RandomForest所需要的树的深度和DecisionTree一样我能理解,因为它是用bagging的方法把DecisionTree组合在一起,相当于做了多次DecisionTree一样。但是xgboost/gbdt仅仅用梯度上升法就能用6个节点的深度达到很高的预测精度,使我惊讶到怀疑它是黑科技了。请问下xgboost/gbdt是怎么做到的?它的节点和一般的DecisionTree不同吗?
【答】
这是一个非常好的问题,题主对各算法的学习非常细致透彻,问的问题也关系到这两个算法的本质。这个问题其实并不是一个很简单的问题,我尝试用我浅薄的机器学习知识对这个问题进行回答。
一句话的解释,来自周志华老师的机器学习教科书( 机器学习-周志华):Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
随机森林(random forest)和GBDT都是属于集成学习(ensemble learning)的范畴。集成学习下有两个重要的策略Bagging和Boosting。
Bagging算法是这样做的:**每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。****简单的多数投票一般就可以。**其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,**每个分类器采用的样本分布都和上一轮的学习结果有关。**其代表算法是AdaBoost, GBDT。
其实就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式D(X)=E(X2)-[E(X)]2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。这个有点儿绕,不过你一定知道过拟合。
如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。
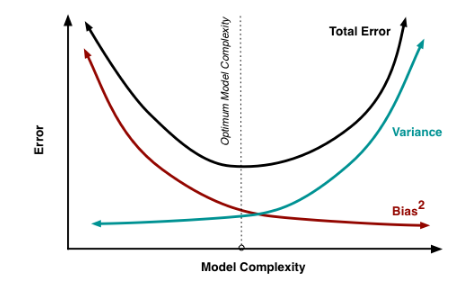
当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大。
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
【问】机器学习算法中GBDT和XGBOOST的区别有哪些?
【答】
传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
列抽样(column subsampling)即特征抽样。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
多种语言封装支持。
【问】为什么基于 tree-ensemble 的机器学习方法,在实际的 kaggle 比赛中效果非常好?
【答】
通常,解释一个机器学习模型的表现是一件很复杂事情,而这篇文章尽可能用最直观的方式来解释这一问题。我主要从三个方面来回答楼主这个问题。
(1)站在理论模型的角度统计机器学习里经典的 vc-dimension 理论告诉我们:一个机器学习模型想要取得好的效果,这个模型需要满足以下两个条件:
好,现在开始让我们想象一个机器学习任务。对于这个任务,一定会有一个 “上帝函数” 可以完美的拟合所有数据(包括训练数据,以及未知的测试数据)。很可惜,这个函数我们肯定是不知道的 (不然就不需要机器学习了)。我们只可能选择一个 “假想函数” 来 逼近 这个 “上帝函数”,我们通常把这个 “假想函数” 叫做 hypothesis.
在这些 hypothesis 里,我们可以选择 svm, 也可以选择 logistic regression. 可以选择单棵决策树,也可以选择 tree-ensemble (gbdt, random forest). 现在的问题就是,为什么 tree-ensemble 在实际中的效果很好呢?
区别就在于 “模型的可控性”。
先说结论,tree-ensemble 这样的模型的可控性是好的,而像 LR 这样的模型的可控性是不够好的(或者说,可控性是没有 tree-ensemble 好的)。为什么会这样?别急,听我慢慢道来。
我们之前说,当我们选择一个 hypothsis 后,就需要在训练数据上进行训练,从而逼近我们的 “上帝函数”。我们都知道,对于 LR 这样的模型。如果 underfit,我们可以通过加 feature,或者通过高次的特征转换来使得我们的模型在训练数据上取得足够高的正确率。而对于 tree-enseble 来说,我们解决这一问题的方法是通过训练更多的 “弱弱” 的 tree. 所以,这两类模型都可以把 training error 做的足够低,也就是说模型的表达能力都是足够的。但是这样就完事了吗?没有,我们还需要让我们的模型的 vc-dimension 低一些。而这里,重点来了。在 tree-ensemble 模型中,通过加 tree 的方式,对于模型的 vc-dimension 的改变是比较小的。而在 LR 中,初始的维数设定,或者说特征的高次转换对于 vc-dimension 的影响都是更大的。换句话说,tree-ensemble 总是用一些 “弱弱” 的树联合起来去逼近 “上帝函数”,一次一小步,总能拟合的比较好。而对于 LR 这样的模型,我们很难去猜到这个“上帝函数”到底长什么样子(到底是2次函数还是3次函数?上帝函数如果是介于2次和3次之间怎么办呢?)。所以,一不小心我们设定的多项式维数高了,模型就 “刹不住车了”。俗话说的好,步子大了,总会扯着蛋。这也就是我们之前说的,tree-ensemble 模型的可控性更好,也即更不容易 overfit.
(2)站在数据的角度
除了理论模型之外, 实际的数据也对我们的算法最终能取得好的效果息息相关。kaggle 比赛选择的都是真实世界中的问题。所以数据多多少少都是有噪音的。而基于树的算法通常抗噪能力更强。比如在树模型中,我们很容易对缺失值进行处理。除此之外,基于树的模型对于 categorical feature 也更加友好。
除了数据噪音之外,feature 的多样性也是 tree-ensemble 模型能够取得更好效果的原因之一。通常在一个kaggle任务中,我们可能有年龄特征,收入特征,性别特征等等从不同 channel 获得的特征。而特征的多样性也正是为什么工业界很少去使用 svm 的一个重要原因之一,因为 svm 本质上是属于一个几何模型,这个模型需要去定义 instance 之间的 kernel 或者 similarity (对于linear svm 来说,这个similarity 就是内积)。这其实和我们在之前说过的问题是相似的,我们无法预先设定一个很好的similarity。这样的数学模型使得 svm 更适合去处理 “同性质”的特征,例如图像特征提取中的 lbp 。而从不同 channel 中来的 feature 则更适合 tree-based model, 这些模型对数据的 distributation 通常并不敏感。
(3)站在系统实现的角度
除了有合适的模型和数据,一个良好的机器学习系统实现往往也是算法最终能否取得好的效果的关键。一个好的机器学习系统实现应该具备以下特征:
到目前为止,xgboost 是我发现的唯一一个能够很好的满足上述所有要求的 machine learning package. 在此感谢青年才俊 陈天奇。
在效率方面,xgboost 高效的 c++ 实现能够通常能够比其它机器学习库更快的完成训练任务。
在灵活性方面,xgboost 可以深度定制每一个子分类器,并且可以灵活的选择 loss function(logistic,linear,softmax 等等)。除此之外,xgboost还提供了一系列在机器学习比赛中十分有用的功能,例如 early-stop, cv 等等在易用性方面,xgboost 提供了各种语言的封装,使得不同语言的用户都可以使用这个优秀的系统。
最后,在可扩展性方面,xgboost 提供了分布式训练(底层采用 rabit 接口),并且其分布式版本可以跑在各种平台之上,例如 mpi, yarn, spark 等等。
有了这么多优秀的特性,自然这个系统会吸引更多的人去使用它来参加 kaggle 比赛。
综上所述,理论模型,实际的数据,良好的系统实现,都是使得 tree-ensemble 在实际的 kaggle 比赛中“屡战屡胜”的原因。
Bagging的代表算法是随机森林,简单说下随机森林的步骤:
(1) 对训练样本进行bootstrap自助法采样,即有放回的采样,获得M个采样集合;
(2) 在这M个采样集合上训练处M个弱决策树。注意到,在决策树生成中还用到了列采样的技巧,原本决策树中节点分裂时,是选择当前节点中所有属性的最优属性进行划分的,但是列采样的技巧是在所有属性中的子集中选最优属性进行划分。这样做可以进一步降低过拟合的可能性;
(3) 对这M个训练出来的弱决策树进行集成。
Stacking还没有代表性的算法,我姑且把它理解成一个集成的思想吧。具体做法是:
(1) 先将训练集D拆成k个大小相似但互不相交的子集D1,D2,…,Dk;
(2) 令Dj’= D - Dj,在Dj’上训练一个弱学习器Lj。将Dj作为测试集,获得Lj在Dj上的输出Dj’’;
(3) 步骤2可以得到k个弱学习器以及k个相应的输出Dj’’,这个k个输出加上原本的类标构成新的训练集Dn;
(4) 在Dn训练次学习器L,L即为最后的学习器。
以上Stacking只做了一层,据kaggle上的大神反馈,Stacking可以做好多层,会有神奇的效果。
下面给出kaggle中一个Stacking的实例,就是入门级的titanic那道题单层stacking的源码(只给出了stacking 的过程,前面特征工程处理的代码被省略掉了)。Stacking后的xgboost(得分:0.77990)比我之前只用xgboost时(得分:0.77512)提高了一点,排名上升了396…… 源码戳这
Log on 2017-6-22: Stacking了两次之后,得分从单次stacking的0.77990上升到了0.79904
Log on 2017-6-22: Stacking了三次之后,得分从两次stacking的0.77990降低到了0.78469。所以,Stacking并不是越多层越好,反而会变坏。
其实,好的自我介绍和一个吸引人的演讲是一样的,需要关注的永远是听众更想听什么,然后把你想说的东西用听众喜欢的方式表达出来。那么对于面试的自我介绍而言,我们需要关注的就应当是面试官想要招一个什么样的员工,然后对应的去组织自己的语言。所以,一般一个好的自我介绍的核心内容往往就是三段式:
1.首先,面试官招聘的很有可能以后就是他的同事,所以他一定希望面试者是一个有趣的人。毕竟谁愿意整天面对着一个面瘫脸工作呢,因此自我介绍里面一定要有能体现自己性格开朗,沟通能力等软实力方面的内容。但是严防出现大段这类话的形况,防止喧宾夺主,毕竟人家招的还是技术岗,技术最重要。
2.和其他行业不同,IT届的技术岗非常重视你的技术实力,因此自我介绍中用简V
3.计算机技术日新月异,迭代的速度完全不是其他任何行业可以比拟的。因此工作的时候需要不断地学习新知识,否则根本无法适应不断提升地业务需要。所以面试官希望的面试者还是一个对于技术、新鲜事物有强烈好奇心的骚年。
但需要这三段,并不是说只要包含这三个内容就足够了。表达的方法也很重要,不能像第二种类型一样,只是干瘪的介绍。每一个论述都需要有论点的支撑,最好的方法就是每个你想介绍的方面都选取你的经历中最典型的,能表现这一方面的用几句话概括起来,然后加上所以我觉得沟通能力还不错之类的总结。这样才能让自我介绍更加丰满,让面试官感觉好像听故事一样。
同时,自我介绍的时候语气也非常重要!!首先全程一定要用中气十足的语气,让人觉得你很有自信,千万千万不要蔫儿蔫儿的。对于不同的内容,要注意情绪的转换,比如说自己幽默、性格开朗的时候,你就需要用一种积极向上的,话里都带着笑得语气表达出来**,千万不要像白开水水一样让人感觉你在背书**。否则,你的内容准备得再好也没有半毛钱用处。
简历应该是怎么样的
简历虽然只是求职的第一步,但如果连第一步都跨不过去,那么更别谈什么面试的技巧。面试不同的岗位都影响简历的撰写,像我这样面试技术岗的,简历还是需要简洁一点,可以走性冷淡风,不要太多的废话。面试技术岗简历上所有的文字都是应该体现你在这个岗位之间的优势,其他所有东西都不能提高你面试的成功率,哪怕你获得的是全国劳动模范。
如果是找实习岗位的话,简历应该以项目经历为主,选择三个最能体现自己能力的项目即可。每一个项目都应该写明项目的过程,自己参与的工作,以及从中的收获。对于不利于自己求职但又不得不写上去的信息,应该尽可能地使他不那么显眼,比如跨专业工作,原来的专业名字不要那么显眼。
另外简历项目可以写多,但是每个项目中的具体到技术的模块不要写多,只写几个自己最熟悉的,比如自己到那几个算法,就不要把所有的算法都写上去,人家首先问的就是你简历上的东西。
面试应该如何准备呢
首先我先声明,面试绝对是要准备的,不管是面试实习还是面试校招社招岗位,面试都是需要至少好几天的准备。如果你想裸面,除非你真的很牛逼,不然肯定会尝到痛苦的,以为找个实习就可以裸面,能学到东西越多的岗位,进这个岗位实习的难度就越大。
面试前至少你要保证,简历上的每一个你都知道他的全部内容,同时要针对简历上的每一个点刷大量的面试题,有时候面试就是这样。感觉面试官聊到自己擅长的地方了,但是一问问题都不会,感觉全会,一问全不会,这就要求一定要去刷面试题。比如在简历上写了SVM,那就要知道svm的原理,svm的各个参数,svm用来解决什么问题,svm有什么优缺点,用svm做过什么东西等等。简历上的东西真的不是写写上去就好了,简历写的多随意,面试就有多难堪。个人认为简历上的每一个点的相对应的知识都应该打印好几张纸,在面试之前好好看好好背诵。
关于项目经历,刚才说到项目经历,每一个写在简历上的项目经历都应该了然于心。有几个要求:
1.必须流畅地讲述出整个项目的过程,项目过程中的每一个环节都应该仔细地去回顾
2.在项目进行的过程中,遇到了哪些困难,又是怎么解决的,每一个项目都应该提前想好
写文章以自勉,在背后越努力,才能在人前表现地越轻松,我觉得面试也是这样的,暂时就先写到这里了,下次更多的面试经历再补充。
优质的岗位:适合自己的才是优质的岗位
招聘企业信息:企业的官方微信、官网,或者在领英上问一下
岗位如何鉴定含金量:还是适合自己的还是最重要,给钱多的不一定含金量高,但含金量高的钱一定不会少,小公司是否有试错的机会,大公司是否有完善的培养机制,要么干的更久,要么干的稀缺性,要么能提升你的能力。
岗位怎么样:可以上看准网,应届生,职业圈、职友集。
工作经验太少,简历不会写:工作经历是直观证明能力的证据,但能力的证明并不止实习经历。找证明自己能力的经历,做过什么项目,学术经历,项目经历。
比如行业分析师,平时多写行业报告,可以在网上放上去,然后简历上附上链接
怎么匹配自己的岗位:兴趣,性格、能力(胜任不胜任)、价值观
了解行业世界:行业、职能、企业、地域
做决策:决策平衡单、决策模式(元认知&自我觉察)
了解企业:前生,历史发展、主营业务、竞争对手、组织框架、用波特五例分析以下
专业不对口怎么办:专业对口率本来就很低,只要不说xx优先,那就是有硬性要求。
数据分析:jd差的特别远,数据库、会R语言、会python,岗位对技术的能力要求是不一样的
如果是凭兴趣找工作,入职当天就是离职倒计时
双非院校怎么提升竞争力,我比的是和自己差不多的人,只要比身边的人强一点。旁边的人都在海投,那我就不海投,求职目标比别人明确,对公司的了解和对行业的了解都比别人深刻,笔试多比别人准备,能力不够动机来凑。表现的很喜欢这家公司,这个行业。
社招没有好岗位,如果想正儿八经的工作,老老实实参加校招。
聪明的学生是不参加校招的,早就在秋招前找好工作了。
面试:需要看到大家的思维的质量,过往经历是什么,面试的岗位和过往经历的关系,主动去说大学期间做了什么,比如卖盆的故事,我做过的事情是有分析的,我知道怎么把事情做好。
思维质量,事情如何去分析,如何去选。
我的优势是什么,我的劣势是什么
未来的规划一定要清楚,我要实现什么,我要通过如何去实现自己的目标,我的目标是非常清晰的,我是有行动计划的,一定是切实可行的,太遥远的不必要说。
那对于一个项目该如何进行面试前的准备呢?同样,对于这个问题,仍旧需要先站在面试官的角度,思考面试官想要从和你交流项目的过程中知道什么。还是那句话,面试官需要招聘的是基础知识扎实、有能力解决问题的、富有创造性的、同时又有一定沟通能力的人。因此,接下来的准备过程中,都需要处处以能展现这几点为目的。面试官问项目的时候也往往遵循着一个套路:简单整体介绍项目,你的创新点是什么?项目中用到的某个网络或者某个技术你了解吗?这个项目你遇到了哪些困难、你是如何解决的?这个项目的评价标准是什么?最终达到什么样的性能?咋一看似乎这些问题不是很有规律可言,但其实就像拔萝卜的过程一样:
从宏观上认识萝卜。也就是你首先要用简短的语言,几句话将你的萝卜整体展现给面试官。一般这几句话我们往往会依照STAR法则去组织语言,即在什么背景(Situation)下,为了解决什么问题(Target),采取了什么方法(Action),最后达到了什么效果(Result).
把主体***。一般面试官会让你介绍你项目中所用到的网络,此时作为面试者就可以按照:为什么用这个网络,网络结构和特点是什么,训练和测试的差别等进行回答。例如我其中的一个项目用到了一个检测网络SSD,那我就会从速度要求引出one_stage和two_stage的区别,因此使用较快的SSD。然后介绍其网络结构和其全卷积、先验框、多尺度的特点,最后解释测试时NMS的处理等等。
把细小末梢一点点抽出来。只准备到能够将主体***的水平仍然不够,你需要做到的是对于其有可能会牵引出来的一切问题都尽可能准备的足够充分。例如,第二点所提到的目标检测,训练过程中如何区分正样本?既然提到了two stage,那么two stage 网络中的ROI-pooling 又是怎么回事?为了让准备的过程中更有逻辑性且考虑更加全面,可以画一棵树,树的主干是此项目所用的主要方法,分出的枝干是所有细节的技术,叶子又是细节技术所牵引出来的其他技术知识。一般也就是准备到两级问题就没基本可以了。如果面试官问到三级、四级。。。那这个面试官真是毫无人性啊,怼他!
对于拔萝卜的评价。评价问题就非常好准备了,主要为两类评价:
对方法的性能的评价,一般会问你用的评价指标是什么,达到什么水平。例如我的一个项目用到了灵敏度、特异性、AUC,基本所有面试官都问了我这些指标的含义,如何计算,以及的方法达到了什么程度。
在拔萝卜过程中的创新点有哪些,和现有的方法好在哪些方面。在这个过程中遇到了哪些困难,你是如何解决的。(此问题尤为重要!)
基本按着这四点进行准备,项目经历这一块就没什么问题了。当然,还需要重复的一点语气!语气!语气!重要的问题说三遍!同样的话,被不同人,用不同的语气说出来,说服力也完全不一样,哪怕你觉得你的项目就是个渣渣,其实没有任何创新型可言,效果也贼烂,但你在与面试官的交流过程中也一定要底气十足。你需要不停的催眠自己,我做的东西就是最棒的!这一点非常重要!
基础知识
算法面试过程中,还有的非常看重的一点就是对于基础知识的掌握。这些基础知识有可能是在项目经历的交流过程中在第二级问题的时候问,也可能在项目之外单独问,但这些问题其实说来说去也就那么点,无非是如何处理过拟合问题,BN是怎么回事?怎么去理解SVM和逻辑斯蒂回归的区别等等。这些只要花时间认真准备,对每一个问题准备的尽可能充分就妥妥的了。
那么。。。问题来了,想把这些问题都准备地很充分这得多久,时间来得及吗?答,还是挺费时的,对于一个问题如果仅仅简单的概述式的介绍给面试官,那基本是凉了的,那到底怎么样才算是准备的足够高充分了呢?简单举个栗子,面试官问你知道Batch Normalization吗?你需要这么回答:
BN的背景是什么(即为什么会提出这种方法)
BN的基本原理是什么,以理解的方式介绍大概步骤
训练和测试时的方差和均值选取的差别
BN的多卡同步又是怎么回事?
甚至,你可以进一步了解下,BN所针对的激活函数一般是sigmoid,可以将参数拉离饱和区,那么如果换成Relu的话,BN是否还有效呢?再进一步的话还可以了解下主流的规范化方法有哪些?(这种程度的问题就知道个名字就好了,不知道也没问题)。
如果你能对一个问题理解到这种程度,基本面试官只要不是压根看你不爽,基本都会觉得你很棒棒了。But! 这么准备下来,一个问题都得准备好久,岂不是根本来不及了?因此!要懂得借用集体的智慧,比如我就组织了我们实验室的五个小伙伴建立一个讨论小组,每天轮流三个人每个人准备一个问题,把问题准备到上面的那个地步,将自己组织好的问题答案共享到腾讯文档,然后每天晚上八点半大家一起讨论。这样还有一个好处就是一个人去理解一个问题的时候往往很容易陷入牛角尖,理解的也很容易片面,但大家一起讨论之后,基本就能很快豁然开朗了。这么准备起来,每天其实只要花很少的时间就可以在相对较短的时间内把这个环节准备的非常充分了。以下是我们讨论小组准备的材料部分预览,我们5个花了大约一个月的时间,共讨论了约70+的问题,约四万五千字的文档使我在面试过程中,基本没有遇到过没讨论过的问题。这些问题可以自己觉得重要的,或者去牛客网上找面经中的问题,同时也非常推荐《百面机器学习》这本书,我们的很多问题也是直接在这本书上找的。
**Situation(情景)**对于酒店来说,顾客的在线评论非常重要,但目前酒店面对的一个主要问题就是网络上各渠道的点评过多,导致每天要来花费大量的时间来人工搜集并处理这些评论。而对于一些自差评或投诉,如果酒店无法及时看到并处理,那么这些评论将会在网络上形成非常不利的影响。说实话,酒店每天机械式的处理网络点评效果并不好,除了增加人工成本、无法实时关注信息外,还会导致错误概率的加大。
目前酒店都比较重视顾客点评管理和舆情监控这一块,因为现在的顾客都习惯在订酒店之前先查看点道评情况,就像网络购物一样查看商品的好评和差评。所以有很多酒店都很重视回复管理顾客点评,对网络舆情进行监控,一旦出现差评,及时回复处理,如果差评处理的越慢越晚,其内传播的面也越广,维护处理的成本就越高,对酒店的在线口碑伤害也就越大。
Task(任务):
Action(行动):训练:用了比较多的技巧:包括截断补齐,正则,数据增强10%,earl_stop,归一化,与之微调,40%的dorpout,动态学习率,
小技巧:mask英文一起遮挡,数字只需判断是num,或者扣掉,
Result(结果):auc93%
另外一件事:mean_max_pooling,一句话的数学表达,平均响应和最大响应,ebemding*2,映射成一个之进行sigmoid激活。
在1998年微软亚洲研究院成立之初,NLP就被确定为最重要的研究领域之一。历经二十载春华秋实,在历届院长支持下,微软亚洲研究院在促进NLP的普及与发展以及人才培养方面取得了非凡的成就。共计发表了100余篇ACL大会文章,出版了《机器翻译》和《智能问答》两部著作,培养了500名实习生、20名博士和20名博士后。我们开发的NLP技术琳琅满目,包括输入法、分词、句法/语义分析、文摘、情感分析、问答、跨语言检索、机器翻译、知识图谱、聊天机器人、用户画像和推荐等,已经广泛应用于Windows、Office、Bing、微软认知服务、小冰、小娜等微软产品中。我们与创新技术组合作研发的微软对联和必应词典,已经为成千上万的用户提供服务。
过去二十年, NLP利用统计机器学习方法,基于大规模的带标注的数据进行端对端的学习,取得了长足的进步。尤其是过去三年来,深度学习给NLP带来了新的进步。其中在单句翻译、抽取式阅读理解、语法检查等任务上,更是达到了可比拟人类的水平。
基于如下的判断,我们认为未来十年是NLP发展的黄金档:
因此,NLP研究将会向如下几个方面倾斜:
自然语言处理,有时候也称作自然语言理解,旨在利用计算机分析自然语言语句和文本,抽取重要信息,进行检索、问答、自动翻译和文本生成。人工智能的目的是使得电脑能听、会说、理解语言、会思考、解决问题,甚至会创造。它包括运算智能、感知智能、认知智能和创造智能几个层次的技术。计算机在运算智能即记忆和计算的能力方面已远超人类。而感知智能则是电脑感知环境的能力,包括听觉、视觉和触觉等等,相当于人类的耳朵、眼睛和手。目前感知智能技术已取得飞跃性的进步;而认知智能包括自然语言理解、知识和推理,目前还待深入研究;创造智能目前尚无多少研究。比尔·盖茨曾说过, “自然语言理解是人工智能皇冠上的明珠”。NLP的进步将会推动人工智能整体进展。
NLP在深度学习的推动下,在很多领域都取得了很大进步。下面,我们就来一起简单看看NLP的重要技术进展。
神经机器翻译就是模拟人脑的翻译过程。
翻译任务就是把源语言句子转换成语义相同的目标语言句子。人脑在进行翻译的时候,首先是尝试理解这句话,然后在脑海里形成对这句话的语义表示,最后再把这个语义表示转化到另一种语言。神经机器翻译就是模拟人脑的翻译过程,它包含了两个模块:一个是编码器,负责将源语言句子压缩为语义空间中的一个向量表示,期望该向量包含源语言句子的主要语义信息;另一个是解码器,它基于编码器提供的语义向量,生成在语义上等价的目标语言句子。
神经机器翻译模型的优势在于三方面:一是端到端的训练,不再像统计机器翻译方法那样由多个子模型叠加而成,从而造成错误的传播;二是采用分布式的信息表示,能够自动学习多维度的翻译知识,避免人工特征的片面性;三是能够充分利用全局上下文信息来完成翻译,不再是局限于局部的短语信息。基于循环神经网络模型的机器翻译模型已经成为一种重要的基线系统,在此方法的基础上,从网络模型结构到模型训练方法等方面,都涌现出很多改进。
神经机器翻译系统的翻译质量在不断取得进步,人们一直在探索如何使得机器翻译达到人类的翻译水平。2018年,微软亚洲研究院与微软翻译产品团队合作开发的中英机器翻译系统,在WMT2017新闻领域测试数据集上的翻译质量达到了与人类专业翻译质量相媲美的水平(Hassan et al., 2018)。该系统融合了微软亚洲研究院提出的四种先进技术,其中包括可以高效利用大规模单语数据的联合训练和对偶学习技术,以及解决曝光偏差问题的一致性正则化技术和推敲网络技术。
智能人机交互包括利用自然语言实现人与机器的自然交流。其中一个重要的概念是“对话即平台”。
“对话即平台(CaaP,Conversation as a Platform)是微软首席执行官萨提亚·纳德拉2016年提出的概念,他认为图形界面的下一代就是对话,并会给整个人工智能、计算机设备带来一场新的革命。
萨提亚之所以提出这个概念是因为:首先,源于大家都已经习惯用社交手段,如微信、Facebook与他人聊天的过程。我们希望将这种交流过程呈现在当今的人机交互中。其次,大家现在面对的设备有的屏幕很小(比如手机),有的甚至没有屏幕(比如有些物联网设备),语音交互更加自然和直观。对话式人机交互可调用Bot来完成一些具体的功能,比如订咖啡,买车票等等。许多公司开放了CAAP平台,让全世界的开发者都能开发出自己喜欢的 Bot以便形成一个生态。
面向任务的对话系统比如微软的小娜通过手机和智能设备让人与电脑进行交流,由人发布命令,小娜理解并完成任务。同时,小娜理解你的习惯,可主动给你一些贴心提示。而聊天机器人,比如微软的小冰负责聊天。无论是小娜这种注重任务执行的技术,还是小冰这种聊天系统,其实背后单元处理引擎无外乎三层技术:第一层,通用聊天机器人;第二层,搜索和问答(Infobot);第三层,面向特定任务对话系统(Bot)。
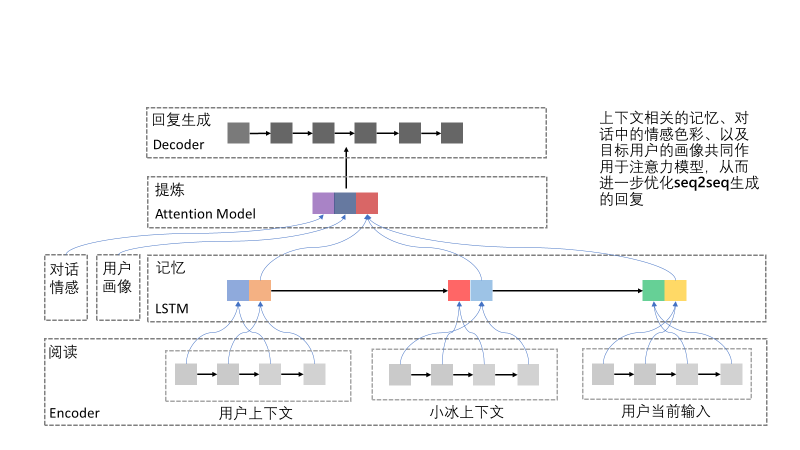
聊天系统的架构
自然语言理解的一个重要研究课题是阅读理解。
阅读理解就是让电脑看一遍文章,针对这些文章问一些问题,看电脑能不能回答出来。机器阅读理解技术有着广阔的应用前景。例如,在搜索引擎中,机器阅读理解技术可以用来为用户的搜索(尤其是问题型的查询)提供更为智能的答案。我们通过对整个互联网的文档进行阅读理解,从而直接为用户提供精确的答案。同时,这在移动场景的个人助理,如微软小娜(Cortana)里也有直接的应用:智能客服中可使用机器阅读文本文档(如用户手册、商品描述等)来自动或辅助客服来回答用户的问题;在办公领域可使用机器阅读理解技术处理个人的邮件或者文档,然后用自然语言查询获取相关的信息;在教育领域用来可以用来辅助出题;在法律领域可用来理解法律条款,辅助律师或者法官判案;在金融领域里从非结构化的文本(比如新闻中)抽取金融相关的信息等。机器阅读理解技术可形成一个通用能力,第三方可以基于它构建更多的应用。
斯坦福大学在2016年7月发布了一个大规模的用于评测阅读理解技术的数据集(SQuAD),包含10万个由人工标注的问题和答案。SQuAD数据集中,文章片段(passage)来自维基百科的文章,每个文章片段(passage)由众包方式,标注人员提5 个问题,并且要求问题的答案是passage中的一个子片段。标注的数据被分成训练集和测试集。训练集公开发布用来训练阅读理解系统,而测试集不公开。参赛者需要把开发的算法和模型提
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
