社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群

作者 | xiufuguo(郭秀富)
导读
Golang是目前最流行的语言,是什么样的特性能够让它如此优秀,受到各大厂及大牛追捧呢?以下文章为你解答Goroutines。
Goroutines 是用户空间线程。
从概念上讲,它类似于由 OS 管理的内核线程,但完全由 Go 运行时管理。
比内核线程更轻巧,更便宜。
调度程序将其复用到内核线程上:
初始 goroutine堆栈 = 2KB;默认线程堆栈 = 8KB,状态跟踪开销。
更快的创建,销毁,上下文切换:
goroutine 开关=〜ns,线程开关=〜aμs。
Goroutine 可以看作对 thread 加一层抽象,它更轻量级,可以单独执行。因为有了这层抽象,Gopher 不会直接面对 thread。对于操作系统不管你抽象什么,线程才是我调度的基本单位。
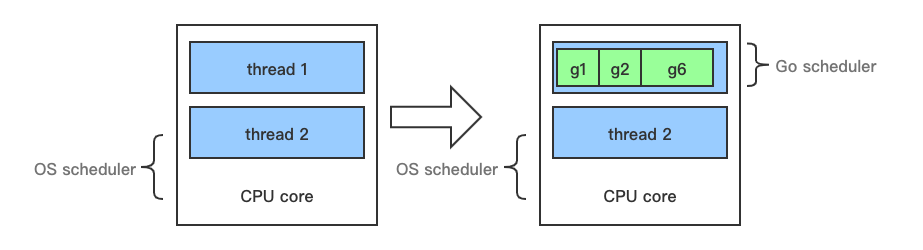
在了解 Go 运行时的 scheduler 之前,需要先了解为什么需要它,因为我们可能会想,OS 内核不是已经有一个线程 scheduler 了嘛?
熟悉 POSIX thread API 的人都知道,POSIX 在很大程度上对现有 Unix 进程模型逻辑进行扩展,因此,线程获得了许多与进程相同的控件。线程具有自己的信号掩码,可以分配给 CPU affinity,可以放入 cgroups 中,并可以查询它们使用的资源。但是很多特征对于 Go 程序来说都是累赘。尤其是 context 上下文切换的耗时。
另一个原因是 Go 的垃圾回收需要所有的 goroutine 停止,内存必须处于一致状态。垃圾回收的时间点是不确定的,如果依靠 OS 自身的 scheduler 来调度,那么会有大量的线程需要停止工作。
单独的开发一个 Go 调度器,可以知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当前正在 CPU 核上运行的那个线程等待即可,而不是等待所有的线程。
为此,Go 采用了类 coroutine 的概念来解决这些问题,Go 将之称为goroutine。
goroutine 占用的资源非常小,goroutine 调度的切换也不用陷入操作系统内核层完成,代价很低。因此,一个 Go 程序中可以创建成千上万个并发的 goroutine。所有的 Go 代码都在 goroutine 中执行,哪怕是 go 的 runtime 也不例外。将这些 goroutines 按照一定算法放到 CPU 上执行的程序就称为 go scheduler。
线程的三种实现方式:用户级线程,内核级线程和混合型线程
用户级线程,多对一(N : 1):多个用户线程的一般从属于单个进程并且多线程的调度是由用户自己的线程库来完成,线程的创建、销毁以及多线程之间的协调等操作都是由用户自己的线程库来负责而无须借助系统调用来实现。一个进程中所有创建的线程都只和同一个 KSE 在运行时动态绑定,也就是说,操作系统只知道用户进程而对其中的线程是无感知的,内核的所有调度都是基于用户进程。许多语言实现的协程库基本上都属于这种方式(比如 python 的 gevent)。由于线程调度是在用户层面完成的,也就是相较于内核调度不需要让 CPU 在用户态和内核态之间切换,这种实现方式相比内核级线程可以做的很轻量级,对系统资源的消耗会小很多,因此可以创建的线程数量与上下文切换所花费的代价也会小得多。但该模型有个缺点:并不能做到真正意义上的并发。
内核级线程,一对一(1 : 1):每一个用户线程绑定一个实际的内核线程,而线程的调度则完全交付给操作系统内核去做,应用程序对线程的创建、终止以及同步都基于内核提供的系统调用来完成,大部分编程语言的线程库(Java 的 java.lang.Thread、C++11 的 std::thread 等等)都是对操作系统的线程(内核级线程)的一层封装,创建出来的每个线程与一个独立的 KSE 静态绑定,因此其调度完全由操作系统内核调度器去做,也就是说,一个进程里创建出来的多个线程每一个都绑定一个 KSE。这种模型的优势和劣势同样明显:优势是实现简单,直接借助操作系统内核的线程以及调度器,所以 CPU 可以快速切换调度线程,于是多个线程可以同时运行,因此相较于用户级线程模型它真正做到了并行处理;但它的劣势是,由于直接借助了操作系统内核来创建、销毁和以及多个线程之间的上下文切换和调度,因此资源成本大幅上涨,且对性能影响很大。
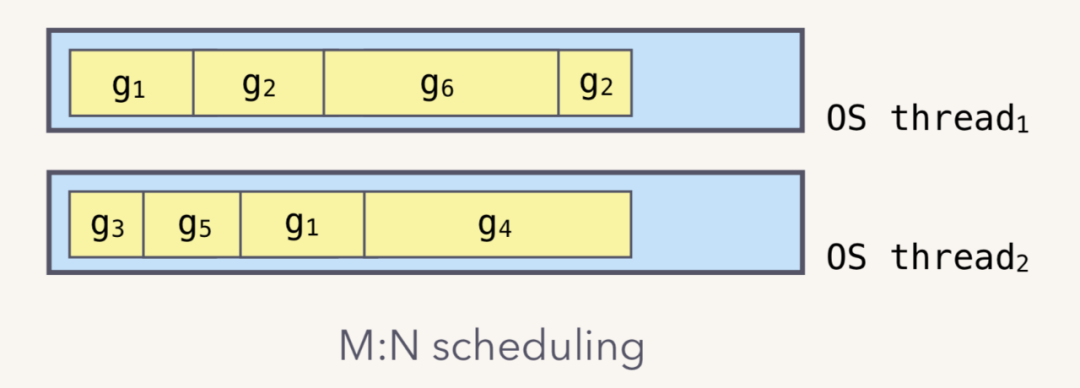
混合型线程,多对多(M : N):首先,区别于用户级线程模型,混合线程模型中的一个进程可以与多个内核线程 KSE 关联,也就是说一个进程内的多个线程可以分别绑定一个自己的 KSE,这点和内核级线程模型相似;其次,又区别于内核级线程模型,它的进程里的线程并不与 KSE 唯一绑定,而是可以多个用户线程映射到同一个 KSE,当某个 KSE 因为其绑定的线程的阻塞操作被内核调度出 CPU 时,其关联的进程中其余用户线程可以重新与其他 KSE 绑定运行。因为这种模型的高度复杂性,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现,而 Go 语言中的 runtime 调度器就是采用的这种实现方案,实现了 Goroutine 与 KSE 之间的动态关联。
Go runtime 负责 goroutine 生命周期,从创建到销毁。runtime 会在程序启动的时候,创建 M 个线程,之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M : N 模型:
要理解协程的实现,首先需要了解 go 中的三个非常重要的概念, 它们分别是 G, M 和 P,这三项是协程最主要的组成部分。
相关代码目录:
$GOROOT/src/runtime/asm_amd64.s
$GOROOT/src/runtime/proc.go
$GOROOT/src/runtime/runtime2.go
G 代表一个 goroutine 对象,每次 go 调用的时候,都会创建一个 G 对象,它包括栈、指令指针以及对于调用 goroutines 很重要的其它信息,比如阻塞它的任何 channel,其主要数据结构:
type g struct {
stack stack // 真实的栈内存,包括上下界
m *m // 当前的m
sched gobuf // goroutine切换时,用于保存g的上下文
param unsafe.Pointer // 用于传递参数,睡眠时其他goroutine可以设置param,唤醒时该goroutine可以获取
/*
Gidle 被创建但没初始换
Grunnable 可运行
Grunning 正在运行
Gsyscall 正在系统调用
Gwaiting 正在等待
Gdead 运行完成
*/
atomicstatus uint32 // g的状态Gidle,Grunnable,Grunning,Gsyscall,Gwaiting,Gdead
goid int64 // goroutine的ID
schedlink guintptr // 下一个g, g链表
waitsince int64 // g被阻塞的大体时间
preempt bool // 抢占标记
lockedm muintptr // g被锁定只在这个m上运行
gopc uintptr // 创建该goroutine的指令地址
startpc uintptr // goroutine函数的指令地址
}
其中最主要的当然是 sched 了,保存了 goroutine 的上下文。goroutine 切换的时候不同于线程有 OS 来负责这部分数据,而是由一个 gobuf 对象来保存,这样能够更加轻量级,再来看看 gobuf 的结构:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}
其实就是保存了当前的栈指针,计数器,当然还有 g 自身,这里记录自身 g 的指针是为了能快速的访问到 goroutine 中的信息。
M 代表一个线程,每次创建一个 M 的时候,都会有一个底层线程创建;所有的 G 任务,最终还是在 M 上执行,其主要数据结构:
type m struct {
g0 *g // 带有调度栈的goroutine
gsignal *g // 处理信号的goroutine
tls [6]uintptr // thread-local storage
mstartfn func()curg *g // 当前运行的goroutinecaughtsig guintptrp puintptr // 关联p和执行的go代码nextp puintptrid int32mallocing int32 // 状态spinning bool // m是否out of workblocked bool // m是否被阻塞inwb bool // m是否在执行写屏蔽printlock int8incgo bool // m在执行cgo吗fastrand uint32ncgocall uint64 // cgo调用的总数ncgo int32 // 当前cgo调用的数目park notealllink *m // 用于链接allmschedlink muintptr // 下一个m, m链表mcache *mcache // 当前m的内存缓存lockedg *g // 锁定g在当前m上执行,而不会切换到其他mcreatestack [32]uintptr // thread创建的栈
}结构体 M 中有两个 G 是需要关注一下的,一个是 curg,代表结构体 M 当前绑定的结构体 G。另一个是g0,是带有调度栈的 goroutine,这是一个比较特殊的 goroutine。普通的 goroutine 的栈是在堆上分配的可增长的栈,而 g0 的栈是 M 对应的线程的栈。所有调度相关的代码,会先切换到该 goroutine 的栈中再执行。也就是说线程的栈也是用的 g 实现,而不是使用的 OS 的。
P 代表一个处理器,每一个运行的 M 都必须绑定一个 P,就像线程必须在么一个 CPU 核上执行一样,由 P 来调度 G 在 M 上的运行,P 的个数就是 GOMAXPROCS (最大256),启动时固定的,一般不修改;M 的个数和 P 的个数不一定一样多 (会有休眠的 M 或者不需要太多的 M) (最大10000);每一个 P 保存着本地 G 任务队列,也有一个全局 G 任务队列。
其数据结构:
type p struct {
lock mutex
id int32
/*
Pidle:没有关联的M
Prunning:已和某个M关联
Psyscall:当前P中的被运行的那个G正在进行系统调用
Pgcstop: 系统正在GC
Pdead: 当前P不再使用
*/
status uint32 // 状态,可以为pidle/prunning/...
link puintptr
schedtick uint32 // 每调度一次加1
syscalltick uint32 // 每一次系统调用加1
sysmontick sysmontick
m muintptr // 回链到关联的m
mcache *mcache
racectx uintptr
goidcache uint64 // goroutine的ID的缓存
goidcacheend uint64
// 可运行的goroutine的队列
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr // 下一个运行的g
sudogcache []*sudog
sudogbuf [128]*sudog
palloc persistentAlloc // per-P to avoid mutex
pad [sys.CacheLineSize]byte
}
其中 P 的状态有 Pidle / Prunning / Psyscall / Pgcstop / Pdead;在其内部队列 runqhead 里面有可运行的 goroutine,P 优先从内部获取执行的 g,这样能够提高效率。
除此之外,还有一个数据结构需要在这里提及,就是 schedt,可以看做是一个全局的调度者:
type schedt struct {
lock mutex
midle muintptr // 空闲M链表
nmidle int32 // 空闲M数量
nmidlelocked int32 // 被锁住的M的数量
mnext int64 // 已创建M的数量,以及下一个M ID
maxmcount int32 // 允许创建最大的M数量
nmsys int32 // 不计入死锁的M数量
nmfreed int64 // 累计释放M的数量
pidle puintptr // 空闲的P链表
npidle uint32 // 空闲的P数量
runq gQueue // 全局runnable的G队列
runqsize int32 // 全局runnable的G数量
// Global cache of dead G's.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
}
大多数需要的信息都已放在了结构体 M、G 和 P 中,schedt 结构体只是一个壳。
可以看到,其中有 M 的 idle 队列,P 的 idle 队列,以及一个全局的就绪的 G 队列。
schedt 结构体中的 Lock 是非常必须的,如果 M 或 P 等做一些非局部的操作,它们一般需要先锁住调度器。
// main.go
package main
import (
"fmt"
)
func main() {
fmt.Println("hello world")
}
使用 gdb 跟踪查看程序启动流程
通过设置断点,可以定位到每个方法的源码文件路径
$ go build main.go
$ gdb main
GNU gdb (GDB) 8.3.50.20190416-git
Copyright (C) 2019 Free Software Foundation, Inc.
(gdb) info files
Symbols from "/Users/kuangren/Desktop/go_project/main".
Local exec file:
`/Users/kuangren/Desktop/go_project/main', file type mach-o-x86-64.
Entry point: 0x105cda0
0x0000000001001000 - 0x000000000109d109 is .text
0x000000000109d120 - 0x00000000010ec2f6 is __TEXT.__rodata
0x00000000010ec300 - 0x00000000010ec426 is __TEXT.__symbol_stub1
...
(gdb) b *0x105cda0
Breakpoint 1 at 0x1051540: file /usr/local/go/src/runtime/rt0_darwin_amd64.s, line 8.
(gdb) b runtime.rt0_go
Breakpoint 2 at 0x104dd30: file /usr/local/go/src/runtime/asm_amd64.s, line 12.
对应找到 asm_amd64.s
// src/runtime/asm_amd64.s
// 省略头文件
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// 省略命令行参数处理的代码
// 全局的g0实例地址放到DI
MOVQ $runtime·g0(SB), DI
LEAQ (-64*1024+104)(SP), BX
// 初始化全局g0实例的stackguard0stackguard1stack这三个字段
MOVQ BX, g_stackguard0(DI)
MOVQ BX, g_stackguard1(DI)
MOVQ BX, (g_stack+stack_lo)(DI)
MOVQ SP, (g_stack+stack_hi)(DI)
// 省略一系列与CPU相关的特性标志位检查的代码
nocpuinfo:
// 到这里与CPU相关的检查已设置完毕
// if there is an _cgo_init, call it.
MOVQ _cgo_init(SB), AX
// 没开启cgo的话就跳转到needtls标签继续执行
TESTQ AX, AX
JZ needtls
// g0 already in DI
MOVQ DI, CX // Win64 uses CX for first parameter
MOVQ $setg_gcc<>(SB), SI
CALL AX
// _cgo_init 执行完,重新更新下stackguard0/stackguard1
MOVQ $runtime·g0(SB), CX
MOVQ (g_stack+stack_lo)(CX), AX
ADDQ $const__StackGuard, AX
MOVQ AX, g_stackguard0(CX)
MOVQ AX, g_stackguard1(CX)
needtls:
// 省略部分用于预编译的代码,因为本文的测试工程环境不会执行这些代码
// 取全局m0实例的tls字段地址放在DI,并进行设置
LEAQ runtime·m0+m_tls(SB), DI
CALL runtime·settls(SB)
// store through it, to make sure it works
// 经过上面的settls后,需要验证get_tls和g()作用是否符合预期。失败的话,就引发abort
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
ok:
// 验证成功后,把全局g0实例放进tls,并且将g0和m0互相引用
get_tls(BX)
LEAQ runtime·g0(SB), CX
MOVQ CX, g(BX)
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
CALL runtime·check(SB)
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
// 执行文件的绝对路径初始化
CALL runtime·args(SB)
// cpu个数和内存页大小初始化
CALL runtime·osinit(SB)
// 命令行参数、环境变量、gc、栈空间、内存管理、所有P实例、HASH算法等初始化
CALL runtime·schedinit(SB)
// create a new goroutine to start program
// runtime.main函数地址放进AX
MOVQ $runtime·mainPC(SB), AX // entry
// 推进栈
PUSHQ AX
PUSHQ $0 // arg size
// 新建一个goroutine,该goroutine绑定runtime.main,放在P的本地队列,等待调度
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
MOVL $0xf1, 0xf1 // crash
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
按顺序总结下 runtime.rt0_go 主要做哪些事:
检查运行平台的 CPU,设置好程序运行需要相关标志。
TLS 的初始化。
runtime.args、runtime.osinit、runtime.schedinit 三个方法做好程序运行需要的各种变量与调度器。
runtime.newproc 创建新的 goroutine 用于绑定用户写的 main 方法。
runtime.mstart 开始 goroutine 的调度。
所有的 goroutine 都是由函数newproc来创建的,但是由于该函数不能调用分段栈,最后真正调用的是newproc1。在newproc1中主要进行如下动作:
func newproc1(fn *funcval, argp *uint8, narg int32, nret int32, callerpc uintptr) *g {
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
_g_.m.locks++ // disable preemption because it can be holding p in a local var
siz := narg + nret
siz = (siz + 7) &^ 7
// 判断函数参数和返回值的大小是否超出栈大小
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr()
// 拿到一个free的goroutine,没有就从全局调度器拿
newg := gfget(_p_)
if newg == nil {
// 新建g实例,栈大小2K
newg = malg(_StackMin)
// g实例状态改成dead
casgstatus(newg, _Gidle, _Gdead)
// 将此g实例加入全局的g队列里
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// 使用了LR寄存器存放函数调用完毕后的返回地址
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 {
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(narg), 0, bv.bytedata)
}
}
// 将newg.sched结构的内存置0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// g实例的调度现场保存SP寄存器
newg.sched.sp = sp
// g实例自身也保存SP寄存器
newg.stktopsp = sp
// g实例的调度现场保存goexit函数的PC寄存器,这样goroutine执行完后都能做好回收
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
// g实例的调度现场关联上对应的g
newg.sched.g = guintptr(unsafe.Pointer(newg))
// g实例的调度现场保存真正待执行函数的PC寄存器
gostartcallfn(&newg.sched, fn)
// g实例保存go语句的PC寄存器位置
newg.gopc = callerpc
// g实例保存待执行函数的PC寄存器位置
newg.startpc = fn.fn
if _g_.m.curg != nil {
// 如果是在goroutine中再new 一个goroutine,就会有labels?
newg.labels = _g_.m.curg.labels
}
// 存在一些go自己创建的goroutine,如果是就在全局调度器里把数量记录下来
if isSystemGoroutine(newg) {
atomic.Xadd(&sched.ngsys, +1)
}
// 设置该goroutine不能被gc扫
newg.gcscanvalid = false
// 设置goroutine状态为可运行
casgstatus(newg, _Gdead, _Grunnable)
// 检查当前p实例里的goroutine id缓存列表是否已经用完,是的话就从全局调度器那儿再获取_GoidCacheBatch个
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
// 设置goroutine id
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
// 把新建的G推进当前P的本地队列,并提优设置为下一个可运行的G
runqput(_p_, newg, true)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
// main方法启动后才进入此if块。唤醒一个空闲的P,如果没有M则创建一个
wakep()
}
_g_.m.locks--
if _g_.m.locks == 0 && _g_.preempt { // restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
}
return newg
}
做了哪些事情:
从 TLS 拿到当前运行的 G 实例,并且使绑定到当前线程的 M 实例不可抢占。
从 M 实例上取到 P 实例,如果 P 实例本地上有 free goroutine 就拿过去,没有就到全局调度器那拿一些过来。如果这两个都没有,就按照最低栈大小2K new 一个 G 实例(即goroutine)。
然后设置好 G 实例上的各种寄存器的信息,SP、PC等。
将 G 实例的状态变更为 Grunnable,放到 P 实例的本地可运行队列里等待调度执行,若队列满了,就把一半的 G 移到全局调度器下。
释放 M 实例的不可抢占状态。返回新的 G 实例。
这个绑定只要 M 没有突破上限 GOMAXPROCS,就拿一个 M 绑定一个 G。
如果 M 的 waiting 队列中有就从队列中拿,否则就要新建一个 M,调用newm。
func newm(fn func(), _p_ *p) {
mp := allocm(_p_, fn)
mp.nextp.set(_p_)
mp.sigmask = initSigmask
execLock.rlock()
newosproc(mp, unsafe.Pointer(mp.g0.stack.hi))
execLock.runlock()
}
该函数其实就是创建一个 M,跟 newproc 有些相似,M 在底层就是一个线程的创建,也就是 newosproc func -> bsdthread_create func -> runtime.clone:
clone(cloneFlags,stk,unsafe.Pointer(mp),unsafe.Pointer(mp.g0),unsafe.Pointer(funcPC(mstart)))
M 创建好之后,线程的入口是 mstart,最后调用的即是 mstart1:
func mstart1() {
_g_ := getg()
gosave(&_g_.m.g0.sched)
_g_.m.g0.sched.pc = ^uintptr(0)
asminit()
minit()
if _g_.m == &m0 {
initsig(false)
}
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
schedule() // 最重要
}
里面最重要的就是 schedule 了,在 schedule 中的动作大体就是找到一个等待运行的 g,然后然后搬到 m 上,设置其状态为 Grunning,直接切换到 g 的上下文环境,恢复 g 的执行。
func schedule() {
_g_ := getg()
if _g_.m.lockedg != nil {
stoplockedm()
execute(_g_.m.lockedg, false) // Never returns.
}
}
schedule函数获取 g -> 必要时休眠 -> 唤醒后继续获取 -> execute函数执行 g -> 执行后返回到 goexit -> 重新执行schedule函数
g 所经历的几个主要的过程就是:Gwaiting -> Grunnable -> Grunning。
经历了创建,到挂在就绪队列,到从就绪队列拿出并运行整个过程。
引入了 struct m 这层抽象。m 就是这里的 worker,但不是线程。
处理系统调用中的 m 不会占用 mcpu 数量,只有干事的 m 才会对应到线程,当 mcpu 数量少于 GOMAXPROCS 时可以一直开新的线程干活。
而 goroutine 的执行则是在 m 和 g 都满足之后通过 schedule 切换上下文进入的。
当有很多 goroutine 需要执行的时候,是怎么调度的 ?
上面说的 P 还没有出场呢,在runtime.main中会创建一个额外 m 运行sysmon函数,抢占就是在 sysmon 中实现的。
sysmon 会进入一个无限循环,第一轮回休眠 20 us,之后每次休眠时间倍增,最终每一轮都会休眠 10 ms。
sysmon 有下面几个处理:
netpool(获取 fd 事件)
retake(抢占)
forcegc(按时间强制执行 gc)
scavenge heap(释放自由列表中多余的项减少内存占用)
func sysmon() {
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
......
}
}
里面的函数retake负责抢占:
func retake(now int64) uint32 {
n := 0
for i := int32(0); i _p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
if s == _Psyscall {
// 如果p的syscall时间超过一个sysmon tick则抢占该p
t := int64(_p_.syscalltick)
if int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_)
}
incidlelocked(1)
} else if s == _Prunning {
// 如果G运行时间过长,则抢占该G
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
if pd.schedwhen+forcePreemptNS > now {
continue
}
preemptone(_p_)
}
}
return uint32(n)
}
枚举所有的 P,如果 P 在系统调用中(Psyscall),且经过了一次 sysmon 循环(20us ~ 10ms),则抢占这个 P,调用 handoffp 解除 M 和 P 之间的关联,如果 P 在运行中(_Prunning),且经过了一次 sysmon 循环并且 G 运行时间超过 forcePreemptNS(10ms),则抢占这个 P,并设置 g.preempt = true,g.stackguard0 = stackPreempt。
为什么设置了 stackguard 就可以实现抢占?
因为这个值用于检查当前栈空间是否足够,go 函数的开头会比对这个值判断是否需要扩张栈。
newstack函数判断 g.stackguard0 等于 stackPreempt,就知道这是抢占触发的,这时会再检查一遍是否要抢占。
抢占机制保证了不会有一个 G 长时间的运行导致其他 G 无法运行的情况发生。
相比大多数并行设计模型,Go 比较优势的设计就是 P 上下文这个概念的出现,如果只有 G 和 M 的对应关系,那么当 G 阻塞在 IO 上的时候,M 是没有实际在工作的,这样造成了资源的浪费,没有了 P,那么所有 G 的列表都放在全局,这样导致临界区太大,对多核调度造成极大影响。
而 goroutine 使用上面的特点,感觉既可以用来做密集的多核计算,又可以做高并发的 IO 应用,做 IO 应用的时候,写起来感觉和对程序员最友好的同步阻塞一样,而实际上由于 runtime 的调度,底层是以同步非阻塞的方式在运行(即 IO 多路复用)。
所以说保护现场的抢占式调度和 G 被阻塞后传递给其他 m 调用的核心思想,使得 goroutine 的产生。
How Goroutines Work
Thread Scheduler
The Go scheduler
GopherCon 2018: Kavya Joshi - The Scheduler Saga
Illustrated Tales of Go Runtime Scheduler.
Go 语言设计与实现
腾讯技术工程
深度解密 Go 语言之 scheduler
线程的三种实现方式-内核级线程, 用户级线程和混合型线程
Goroutine 并发调度模型深度解析之手撸一个高性能 goroutine 池
深入 Golang 调度器之 GMP 模型
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
