社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Mysql数据表中的数据都是存在磁盘上的并且是随机分布的,也就是说如果每查1次特定的数据,如果不用索引的数据结构查询,效率会非常低。
索引(Index)是帮助MySQL高效获取数据的数据结构
单列索引:一个索引包含一列,一个表可以包含多个单列索引
普通索引:设置经常被查询的表的字段为索引键
唯一索引:可以为NULL,其他与主键索引相似
主键索引:不可以为NULL
联合索引:一个组合索引包含两个或两个以上的列
1. 二叉树
2. 红黑树
3. Hash表
4. B-Tree
5. B+Tree
(比如当加入col2列字段时,每插入一行数据,往二叉树里面放1下,左边小,右边大)
实际上存储的结构是key - value的结构。
比如34为key,34所在这一行的所有信息就是value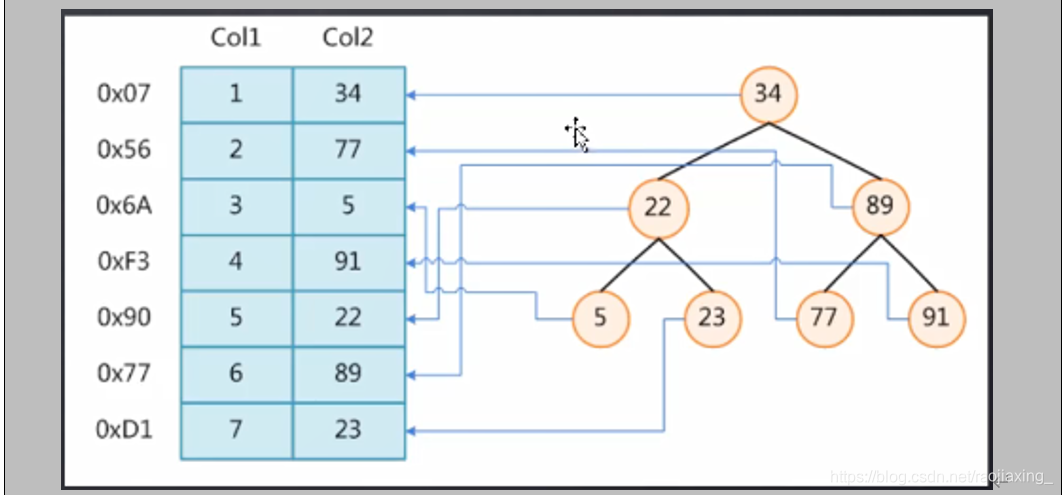
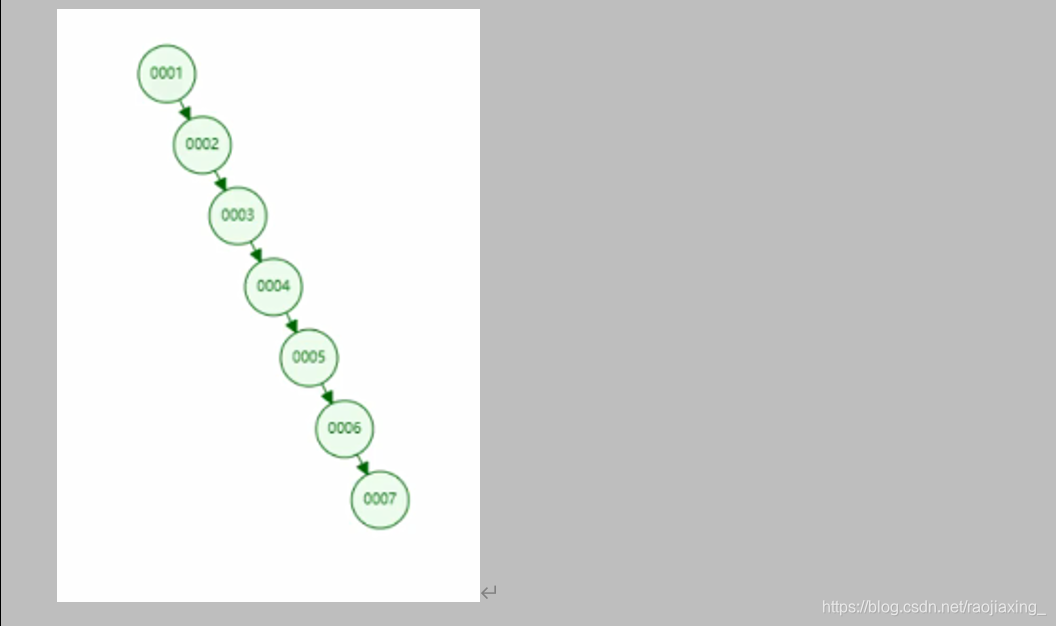
弊端:如果是自增的形式插入二叉树,插入的二叉树,永远只有单边。
变成了链表的形式,如果我要查询靠后的6,还是一个一个查询,效率低
HashMap在jdk1.8版本后有很大的改动,它把它的底层链表改成了红黑树。
红黑树其实很像二叉树,但是红黑树是二叉树的升级版,又叫二叉平衡树。
在插入单边增长的元素时,它会自动做一个平衡。
现在查询6这个元素,只需要查询3次。

弊端:在数据量比较大的情况下也有1些问题。
比如数据量有500w,树的高度肯定会非常的高。
假如树的H高度为30,我要查询的元素刚刚就在第30层。
那么我数据的查询要经过30次磁盘,会非常的慢。用户肯定等不及
在数据库当中,百分之99.99都是用的B+树结构去查询。
百分之0.01是用Hash表去查询,Hash表用了一个闪电算法。
跟MD5的算法一样,通过查找元素,对应的去找其hash地址所对应的所有信息。
弊端:Hash表查数据是最快的,但是为什么还是不用呢?
因为如果面对的是范围查找,hash就毫无用武之地
B-Tree以纵向来存储数据,可以将上百万,上千万级别的数据以纵向节点的方式去存储。
将树的高度控制在很低的位置,比如控制在5,6层左右。
一个节点的数据是16KB。Mysql数据类型比如bigInt是8K,所以一个节点大约能存1170条数据。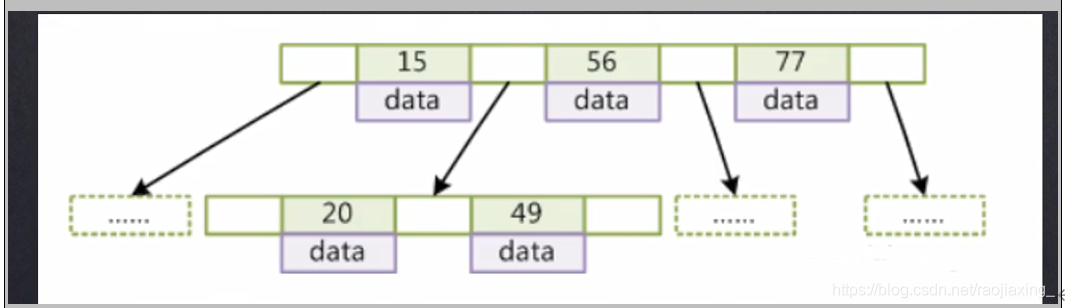
弊端:为什么底层也不用B树查找,而是用B+树去查找?
因为B+树在面对范围查找时的效率比B树高。
具体的原因就是因为B+树的叶节点有指针相连,故只顺着往下查到叶节点,比对一次即可。
而B树没有指针相连,查范围的时候需要反复对比去查询
Mysql的底层索引原理:B+Tree。属于B树的变种。
B+树其实就是一个多叉平衡树。
B+树跟B树的 区别就是叶子节点用指针连接,提高区间访问性能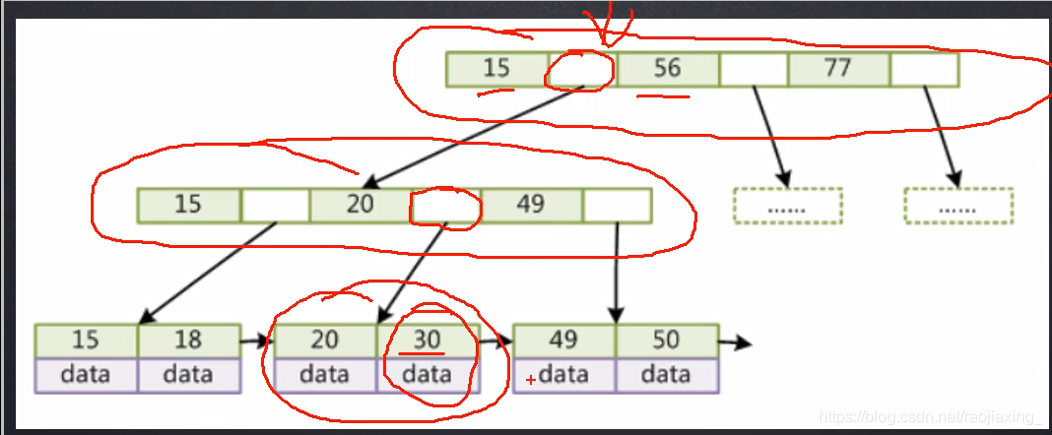
首先我们要清楚mysql的数据k库中的数据究竟放在了哪。
数据储存的位置在mysql5.5文件下的data文件夹下。
数据库引擎定义了数据库存储数据的数据结构特点,主要通过指定的数据库引擎对象来限制数据库操作数据不同方式的效率、锁和事务的支持、数据全文检索的支持、数据集的缓存操作等等特性。
Mysql当中常用的储存引擎有两个:

.frm 文件存储的是数据结构
.MyD 文件存储的是My data
.MyI 文件存储的是My Index
Myisam索引文件和数据文件是分离的。
先查索引文件,然后再查数据文件,底层也是B+树原理
比如说我要查30这个元素,找15-56区间,再找20-49区间,然后找到30,然后通过30去指定的MyD当中查找30对应的地址文件。
底层原理图:
Myisam存储引擎是非聚集索引-就是叶节点不包含了完整的数据记录。
它完整的数据记录在MYD数据文件当中。

.idb文件就是.MYI和.MYD的合并
直接一查到底,不用回表。底层也是B+树原理。
底层原理图: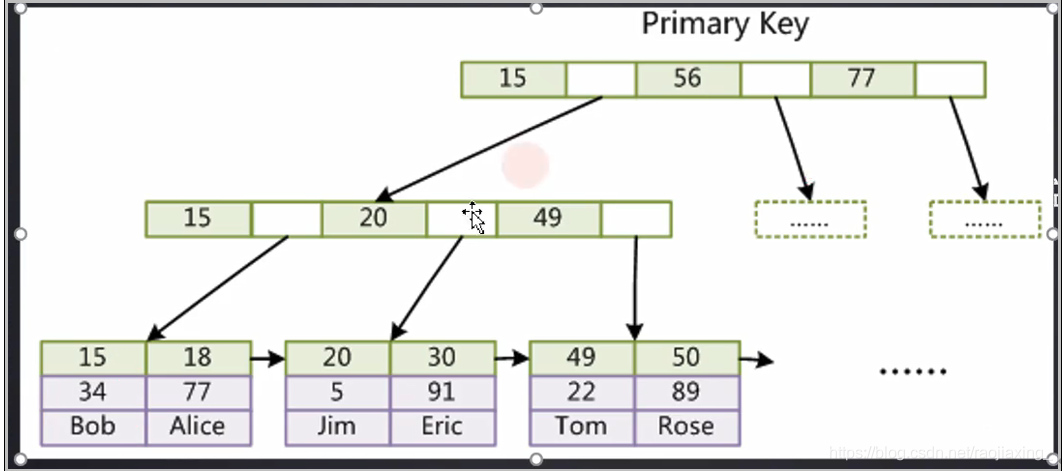
Innodb存储引擎的索引是聚集索引-就是叶节点包含了完整的数据记录
为什么InnoDB表必须有主键,并且推荐使用整形的自增主键?
1.因为主键不能为null,而且唯一,可以利用主键进行精准查找。
如果没有元素唯一的,InnoDB会自动生成一个字段,类似于rowid字段,就是整形的1,2,3,4,5,6……,只不过我们看不到
2.比如 用整型1跟2比,或者用uuid生成的abc….1跟abc…2比。
明显整型快,UUID生成的英文字母还需要转成AS码表一个一个进行比对。
INNODB引擎
InnoDB使用B+树完成数据库索引的实现,但是在数据存储时数据结构中存储的是实际数据,被称为聚集索引的东东,不支持全文检索,启动也是比较慢的。
InnoDB引擎支持ACID事务的支持,提供了行级锁和外键约束,设计目标是处理大容量数据库系统,处理过程中会在内存中建立数据库缓冲区用于缓存数据和索引数据。但是如果进行select count(*) from <table_name>时,会进行全表扫描,不会缓存扫描结果;同时在高并发的情况下,由于InnoDB引擎支持的锁的粒度较细,不会在写操作时全表锁定,有利于高并发下性能的提升。
MYIASM引擎
MyIASM使用B+树完成数据库索引的实现,但是在数据存储时数据结构中存储的是实际数据的地址,被称为非聚集索引,支持全文检索
MyIASM不支持事务操作,不支持行级锁和外键的约束;在进行select count(*) from
使用区分
如果我们的数据库存储大量数据,需要支持事务操作和外键约束,同时在出现故障需要快速恢复时,使用InnoDB引擎;
如果我们的数据库中需要大量而频繁的的insert语句操作时,可以选择MyIASM数据库引擎
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
