社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
线程是操作系统能够运算调度的最小单位。计算机中有各种各样的应用程序,这些程序执行任何操作都需要CPU来计算,CPU计算需要操作系统发送指令给CPU,线程就相当于这一系列的指令 ,操作系统去调度CPU最小的单位就是线程。
进程是程序各种资源管理的集合。程序(线程)是不能单独运行的,只有将程序装载到内存中,系统为其分配资源之后才能运行,而程序获得各种资源后的集合就称为进程。例如:假如qq这个进程需要将数据发送到网络,那么就需要利用网卡,但是qq不能直接访问网卡,所以此时就需要一个相当于中间介质的东西来管理多个进程之间的访问,这个中间介质就是操作系统。 那么qq就需要提供一个接口暴露给操作系统,以便被操作系统来管理。 这个接口里面包含对各种资源的调用,内存的管理,网络接口的调用等(这个接口就称之为进程)。
线程被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
例如:假如有一个工厂(这个工厂相当于整个内存空间),这个工厂有十个车间(每个车间相当于一个进程,每个进程占用了部分内存空间,这个进程相当于这个车间内所有资源的集合),每个车间里至少需要一个工人来工作(每个工人都相当于线程,同一个进程内的所有线程共享内存空间和资源),车间给工人提供相应的环境,而这些工人(线程)做实际的工作操作(发送数据和指令给cpu运算)。 车间没有了工人就不能正常运行,而工人不在车间就不能完成某一项操作。
1、每一个进程中必须至少包含一个线程,进程是不执行的,执行的只有线程,操作一个进程实际上就是操作里面的线程;
2、一个进行里面可以包含多个线程,多个线程可以同时执行(通过上下文的快速切换进行实现,同一时刻只有一个线程在执行,通过不断地切换程序使得看起来像是在并行),但同一个进程里面的所有线程共用一个内存资源,所以修改一个线程,可能会有干扰其他线程;
3、进程与进程之间互不干扰,因为不同进程内存空间不同,修改父进程是不会影响子进程,但删除是会影响子进程;
4、创建一个新的线程比较容易,而创建一个新的进程需要从父进程处继承;
5、进程与线程哪个速度快:其实这个问题是错误的,因为进程和线程没有可比性,进程是资源的集合,进程也是需要线程来发送指令给CPU计算的;
6、启动一个进程快还是启动一个线程快:启进线程比进程快,因为启动进程需要到内存需申请空间和计算,启动线程只是相当于发送指令。
一核CPU同一时刻只能处理一个任务,假如现在需要处理十个文档,那么就需要一个一个的来处理,需要处理十次。但是我们用十个任务分别处理这十个文档就,对于CPU虽然不是同时的,但因为CPU处理切换很快,给人感觉上就像是同时在处理。
threading模块的两种调用方式:
1 直接调用:
import threading, time
def run(i):
print("running threading:", i)
time.sleep(2)
print("threading %s running done..." % i)
t1 = threading.Thread(target=run, args=(1,)) # 实例化一个线程
t2 = threading.Thread(target=run, args=(2,)) # 实例化另一个线程
t1.start() # 启动线程
t2.start()
# run(1)
# run(2)
运行结果:
running threading: 1
running threading: 2
threading 2 running done...
threading 1 running done...
# 直接运行run的时候可以看出,等待时间会更长,也就是4s,而启动多线程时时间明显缩短,下面会通过装饰器直接测量多线程的运行时间通过装饰器来测量多线程的运行时间
import threading, time
# 设计一个装饰器,来测量多线程的运行时间
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间为:%.2f" %(f.__name__, end_time - start_time))
return res
return wrapper
def run(i):
print("running threading:", i)
time.sleep(2)
# print("threading %s running done..." % i)
@timeit
def main():
t1 = threading.Thread(target=run, args=(1,)) # 实例化一个线程
t2 = threading.Thread(target=run, args=(2,)) # 实例化另一个线程
t1.start() # 启动线程
t2.start()
t1.join() # 等待线程执行完,才执行下一步
t2.join()
print("running done!")
main()
运行结果:
running threading: 1
running threading: 2
running done!
main函数运行时间为:2.002 继承式调用:
import threading
class MyThreading(threading.Thread):
def __init__(self, n):
super(MyThreading,self).__init__()
self.n = n
def run(self): # 这种方式下必须将子函数写成run
print("run task:",self.n)
t1 = MyThreading("1")
t2 = MyThreading("2")
t1.start()
t2.start()正常情况下主线程和子线程是并发的,如果整个程序的线程没有执行完,那么就不会退出该程序,必须等全部执行完才会退出(在不适用.join的情况下)。如果将子进程被设置为守护线程,当主线程执行完成后,不管子线程有没有执行完,整个程序都会退出。
import threading
import time
def run(n):
print ("task",n)
time.sleep(2)
print ("task done",n)
start_time = time.time()
t_objs = [] # 建立一个空列表,用于存放实例化后的线程t
for i in range(50):
t = threading.Thread(target=run,args=("t-%s"%i,))
t.setDaemon(True) ## 把当前线程设置为守护线程;设置守护之前一定要在t.start()之前,在t.start()之后就不允许设置了。
t.start()
t_objs.append(t)
# for t in t_objs: #这里需要把.join的操作注释掉
# t.join()
print ("finished!")
print ("running time:",time.time() - start_time)
运行结果:
task t-0
task t-1
task t-2
....
task t-48
task t-49
finished!
running time: 0.00800013542175293
Process finished with exit code 0
可以看出时间很短,因为主线程已经执行完了,守护线程不管有没有运行完,程序都退出了python有通过C语言开发的,也有通过JAVA开发的。C语言开发的就叫做cpython,Java开发的就叫做jpython。其中cpython存在一个问题需要使用到全局锁。
此时假如有4个任务,如果只有一核CPU,那么执行任务时,只能是串行的方式执行,不是并行的方式,执行任务1时,如果任务1没有计算完成,可能会切换到任务2去计算,那么此时任务1会被记住已经执行到了哪一页,哪一行,哪一个具体字符的位置(称作:上下文),等到下次切换到任务1时,就继续之前的位置计算执行。
如果有4核CPU,就可以同时执行4个任务,实现真正的在同一时刻并发,其中Java和c都可以实现真正的并发;而python是假并发,这是因为当初python在设计时还没有多核CPU,所以就没考虑使用多核CPU来实现并发,而导致了python设计缺陷; 当前python只是因为CPU计算切换的较快,所以看到的是假并发的错觉。python不管计算机有多少核CPU,在同一时刻,能计算的线程只有一个。
假如现在有个数据 number = 1,此时我们起4个线程,希望每个线程+1后,根据加减结果另外线程再去+1,我们同时交给4核CPU分别取处理去+1(要求最终结果等于4),线程1将数据交给了CPU1,线程2将数据交给了CPU2......,每核CPU在同一时间获取了number = 1这个数据,然后分别各自去做 +1 这个操作等于2,而我们每核CPU会将2这个结果返还给number = 2,所以最后number还是 =2,并不是我们期望的4核CPU分别+1最终=4。像加减运算这类的数据,我们还是期望使用串行的方式,一个一个的去计算,而不是并发导致最终计算错误。此时我们就可以使用全局锁来解决cpython中出现的这个问题。
虽然4个线程将数据同时交给了4个CPU,但线程到python解释器去申请全局锁后才能执行(python解释器负责全局锁分配),得到gil锁后就正常执行没得到gil锁的就不能执行,同一时间只能有一个线程获取gil锁,这样可以避免所有线程同时去计算。 但gil锁也有个问题是,其中一个线程拿到gil锁后会对线程有执行的时间限制。假如线程1拿到了gil锁,一共需要执行5秒才能完成线程1的代码,但是gil锁只给了线程1秒的执行时间就必须释放gil锁给其他线程轮询执行(此时CPU会记住线程1的位置,也就是上下文),此时线程1还没执行完成,线程2就拿到gil锁去执行可能就会导致最终共享数据计算错误。在python2.x的版本中会出现上述的问题,而在python3.x中就不再出现,可能是自动加了锁。下图为GIL的基本实现过程:
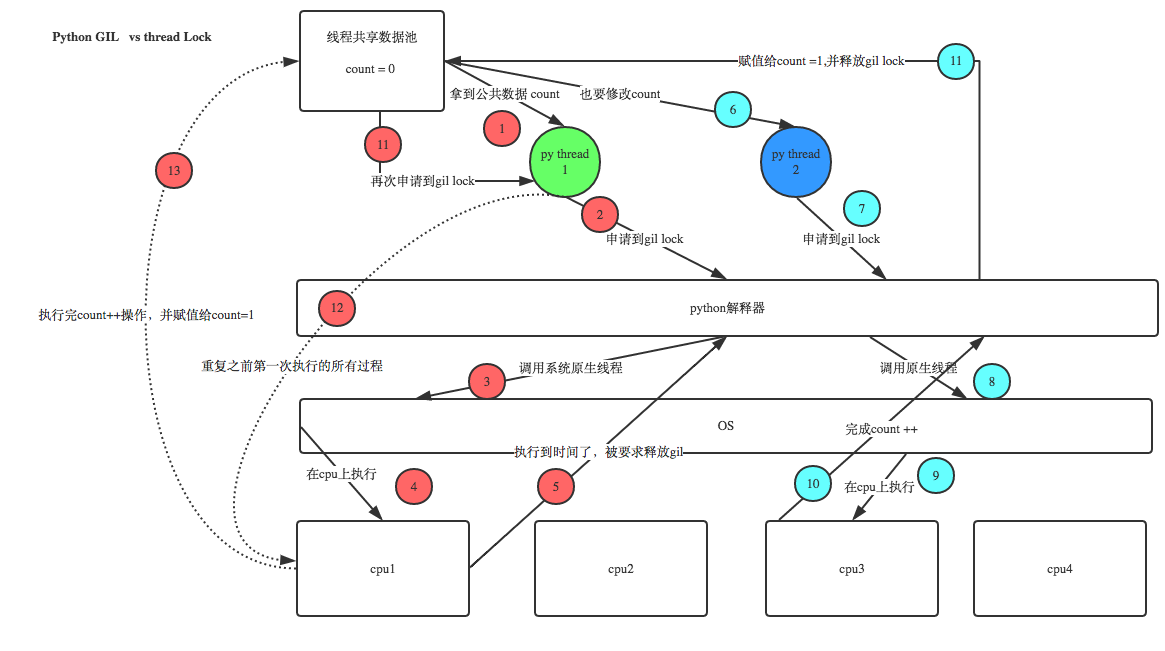
下面我们用0+1来计算模拟问题:
步骤1:线程1拿到共享数据
步骤2:线程1到python解释器去申请gil锁。
步骤3:解释器调用系统原生线程(操作系统的线程)
步骤4:将线程1的任务分配到CPU1。
步骤5:此时线程1还没有执行完成,因为执行时间到了,被要求释放gil锁。
步骤6:线程2拿到共享数据。
步骤7:线程2到解释器去申请gil锁。
步骤8:调用原生线程。
步骤9:线程2被分配到了CPU3.
步骤10:此时由于线程2执行较快,在执行时间内完成了计算,返回给解释器。
步骤11:count默认=0,此时线程2进行0+1=1,将1这个值赋值给了count,count此时=1。
步骤12:线程1重复第一次执行的所有动作。
步骤13:此时线程1也计算完成,将0+1 ,count=1的结果赋值给count,此时会覆盖count的数据,所以最终count还是=1,。
有全局锁,依然会存在修改共享数据的问题,由于一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果多个线程同时要修改同一份数据,只有全局锁的话,最终的数据可能还是会出现问题。,那么我们可以通过再加一把锁来解决这个问题。再加的锁就不是全局锁了(而是线程锁),和全局锁也没有关系,而是针对数据加一把锁,新加锁后只能其中一个线程来修改这个数据。 也就是说计算的时候依然使用全局锁,但是改变数据时只能等待拿到新锁的线程修改完后,其他线程才能去修改这个数据。假如线程1拿到了修改数据的新锁,此时线程2计算的比线程1要快,但线程2不能改变数据,只能等线程1修改完后,线程2才能去获取锁在修改。最终多线程还是可以实现的,只是计算的过程实现了并行,而修改结果变成了串行。
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print('Get num:',num )
time.sleep(1)
lock.acquire() #修改数据前加锁
num -=1 #对此公共变量进行-1操作
lock.release() #修改后释放
num = 100 #设定一个共享变量
thread_list = []
lock = threading.Lock() #生成全局锁
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('Final num:', num )递归锁(RLock):
可以理解为在锁中再嵌套子锁
import threading, time
def run1():
print("grab the first part data")
lock.acquire()
global num
num += 1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2 += 1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res, res2)
if __name__ == '__main__':
num, num2 = 0, 0
lock = threading.RLock()
for i in range(2):
t = threading.Thread(target=run3)
t.start()
# while threading.active_count() != 1:
# print(threading.active_count())
# else:
# print('----all threads done---')
# print(num, num2)
运行结果;
grab the first part data
--------between run1 and run2-----
grab the second part data
1 1
grab the first part data
--------between run1 and run2-----
grab the second part data
2 2互斥锁是指同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading, time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s" % n)
semaphore.release()
if __name__ == '__main__':
num = 0
semaphore = threading.BoundedSemaphore(10) # 最多允许10个线程同时运行
for i in range(20):
t = threading.Thread(target=run, args=(i,))
t.start()
# 运行代码就可以看到结果是10个10个一出事件用于线程与线程之间的交互,主要有三种用法:
import threading
def do(event):
print("start")
event.wait()
print("execute")
event_obj = threading.Event()
for i in range(3):
t = threading.Thread(target=do, args=(event_obj,))
t.start()
event_obj.clear() # 清空标志符
inp = input('input:')
if inp == 'true':
event_obj.set() # 设置标志符
运行结果:
start
start
start
input:true
execute
execute
execute当要在多线程之间实现数据的安全交互时,队列是一种很好地解决方式。队列其实是一种解耦的过程,从而降低了程序之间的关联性。有三种方式:
class queue.Queue(maxsize=0) #先入先出
class queue.LifoQueue(maxsize=0) #last in fisrt out
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue
# q = queue.Queue() # 先进先出
# # q = queue.LifoQueue() # 后进先出
#
# q.put(1)
# q.put(2)
# q.put(3)
# print(q.get())
# print(q.get())
# print(q.get())
q = queue.PriorityQueue() # 设置优先级
q.put(1,"lkj") # 1表示优先级,数字越小优先级越高
q.put(10,"dak")
q.put(3,"sjdlaj")
print(q.get())
print(q.get())
print(q.get())详细可参考:
https://blog.51cto.com/daimalaobing/2087351
https://www.cnblogs.com/alex3714/articles/5230609.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
