社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
备注:个人学习笔记,是学习B站上的狂神说Java的课程摘录的笔记。
视频地址:https://www.bilibili.com/video/BV1S54y1R7SB
B站up主:狂神说Java
笔记参考来源:微信公众号:狂神说
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis是单线程的
Redis单线程快的原因
编译型异常(代码有问题,命令有错),事务中所有的命令都不会被执行
运行时异常,如果事务队列中存在语法性,那么执行命令的时候,其他命令式可以正常执行的,错误命令抛出异常
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 我们为了自己开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
bind 127.0.0.1 # 绑定的ip
protected-mode yes # 保护模式
port 6379 # 端口设置
daemonize yes # 以守护进程的方式运行,默认是no,我们需要自己开启为yes
pidfile /var/run/redis_6379.pid # 如果以后台的方式运行,我们就需要指定一个pid文件
# 日志
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" # 日志的文件位置名
databases 16 # 数据库的数量,默认是16个
always-show-logo yes # 是否总是显示logo
save 900 1 # 如果900s内,至少有1个key进行了修改,我们就进行持久化操作
save 300 10 # 如果300s内,至少有10个key进行了修改,我们就进行持久化操作
save 60 10000 # 如果60s内,至少有10000个key进行了修改,我们就进行持久化操作
stop-writes-on-bgsave-error yes # 持久化如果出错,是否还要继续工作
rdbcompression yes # 是否压缩rdb文件,需要消耗一些cpu资源
rdbchecksum yes # 保存rdb文件的时候,进行错误的检查校验
dir ./ # rdb文件保存的目录
config get requirepass # 获取redis的密码
config set requirepass password # 设置redis的密码
auth password # 使用密码进行登录
maxclients 10000 # 设置能连接上redis的最大客户端数量
maxmemory <bytes> # redis配置最大的内存容量
maxmemory-policy noeviction # 内存达到上限之后的处理策略
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分的情况下,rdb完全够用
appendfilename "appendonly.aof" # 持久化的文件名名字
# appendfsync always # 每次修改都会sync,消耗性能
appendfsync everysec # 每秒执行一次sync,可能会丢失中这1s的数据
# appendfsync no # 不执行sync,这个时候操作系统自动同步数据,速度最快
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。
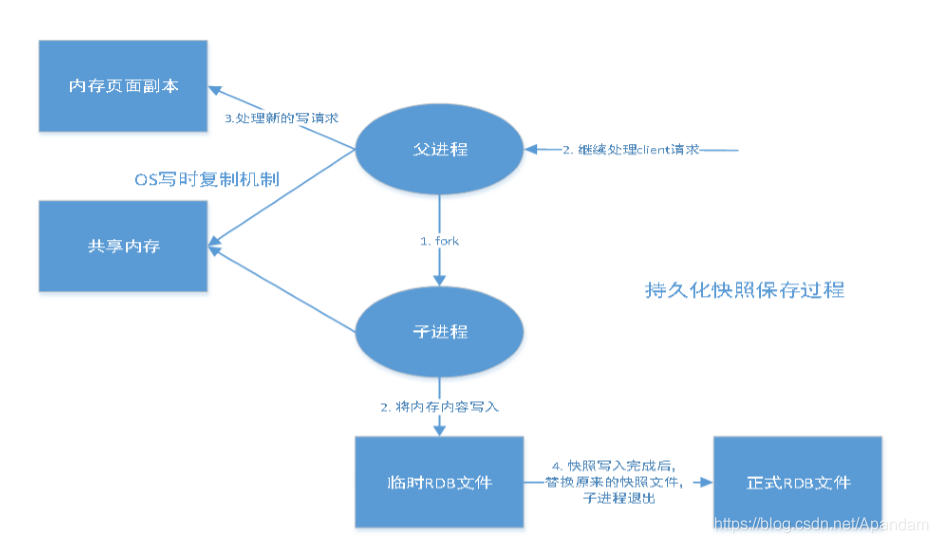
优点:
缺点:
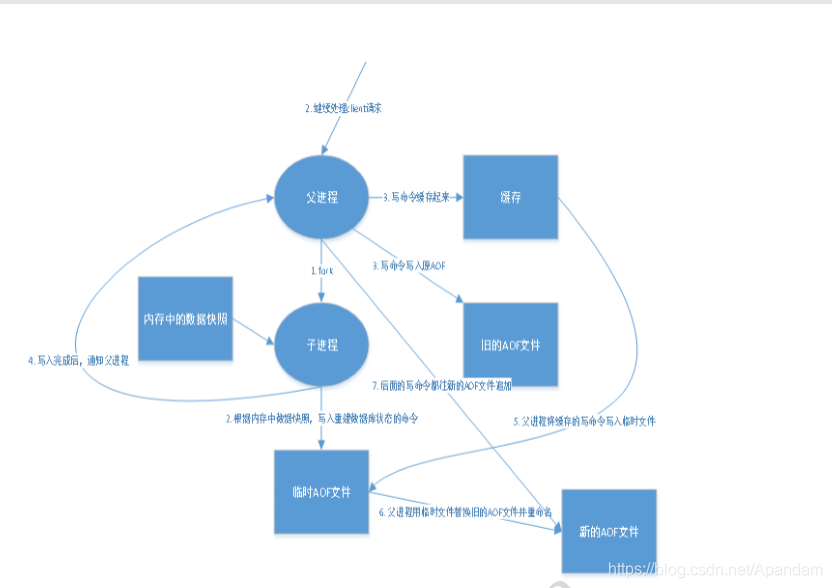
将我们所有的命令都记录下来。
优点:
缺点:
扩展:
性能建议:
主从复制的作用:
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的(宕机),原因如下:
原理:
哨兵的作用:
优点:
缺点:
缓存穿透(查不到)
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒 杀!),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了 缓存穿透。
解决方案:
布隆过滤器
存在的问题:
解决方案:
解决方案:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
