社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Protocol Buffer是Google出品的数据传输协议,目前已经广泛用于客户端和服务器之间的数据交互
通过将 结构化的数据 进行 串行化(序列化),从而实现 数据存储 / RPC 数据交换的功能
序列化: 将 数据结构或对象 转换成 二进制串 的过程
反序列化:将在序列化过程中所生成的二进制串 转换成 数据结构或者对象 的过程
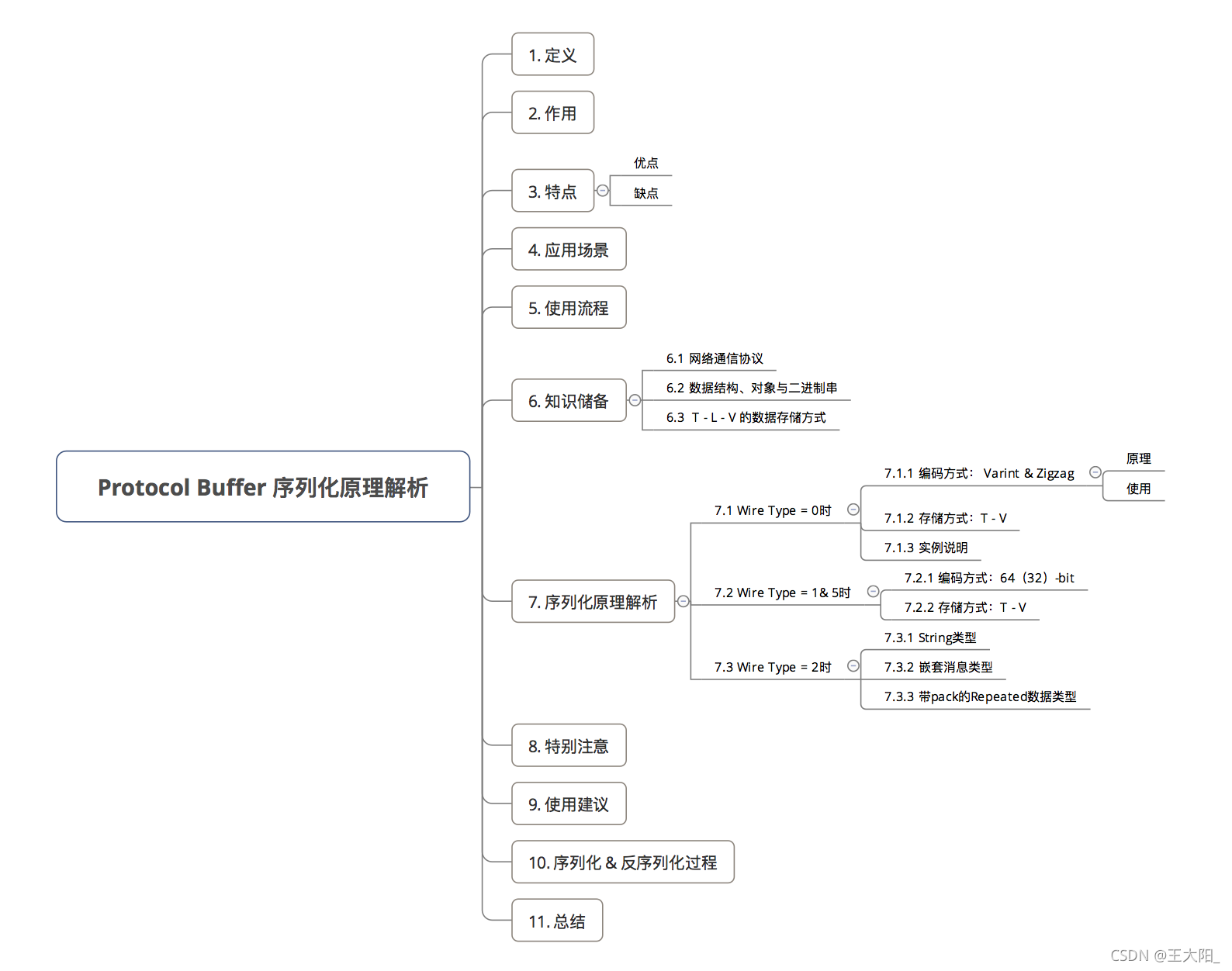
序列化数据时,不序列化key的name,使用key的编号替代,减小数据
例如定义如下数据结构:
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
上述数据在序列化时,query,page_number以及result_per_page的key不会参与,由编号1,2,3替代,这样在反序列的时候可以直接通过编号找到对应的key,这样做确实可以减小传输数据,但是编号一旦确定就不可更改
没有赋值的key,不参与序列化
序列化时只会对赋值的key进行序列化,没有赋值的不参与,在反序列化的时候直接给默认值即可
可变长度编码
可变长度编码,主要缩减整数占用字节实现,例如java中int占用4个字节,但是大多数情况下,我们使用的数字都比较小,使用1个字节就够了,这就是可变长度编码完成的事
TLV
TLV全称为Tag_Length_Value,其中Tag表示后面数据的类型,Length不一定有,根据Tag的值确定,Value就是数据了,TLV表示数据时,减少分隔符的使用,更加紧凑
Protocol Buffer 反序列化直接读取二进制字节数据流,反序列化就是 encode
的反过程,同样是一些二进制操作。
https://zhuanlan.zhihu.com/p/101783606
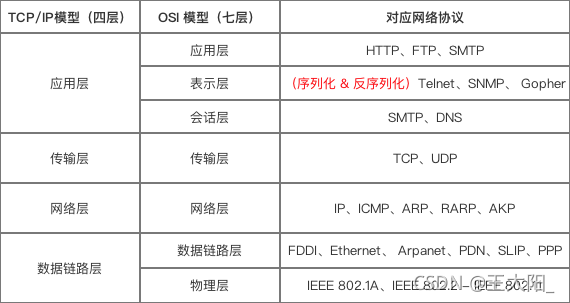
序列化 / 反序列化 属于 TCP/IP模型 应用层 和 OSI`模型 展示层的主要功能:
(序列化)把 应用层的对象 转换成 二进制串
(反序列化)把 二进制串 转换成 应用层的对象
所以, Protocol Buffer属于 TCP/IP模型的应用层 & OSI模型的展示层
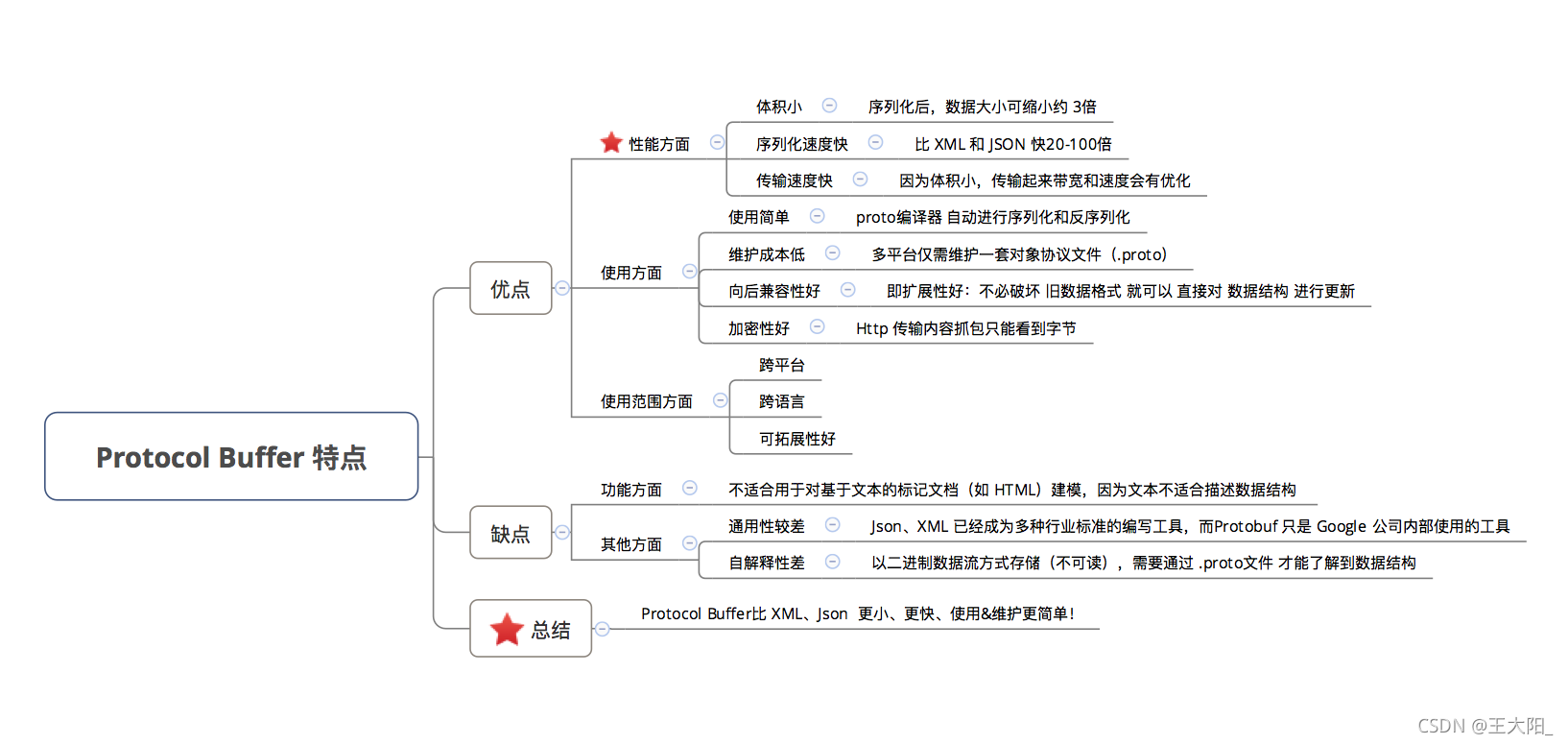
Protocol Buffer 序列化采用 Varint、Zigzag 方法,压缩 int 型整数和带符号的整数。对浮点型数字不做压缩(这里可以进一步的压缩,Protocol Buffer 还有提升空间)。编码 .proto 文件,会对 option 和 repeated 字段进行检查,若 optional 或 repeated 字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不进行序列化(少编码一个字段)。
上面这两点做到了压缩数据,序列化工作量减少。
序列化的过程都是二进制的位移,速度非常快。数据都以 tag - length - value (或者 tag -value)的形式存在二进制数据流中。采用了 TLV 结构存储数据以后,也摆脱了 JSON 中的 {、}、;、这些分隔符,没有这些分隔符也算是再一次减少了一部分数据。
Protocol Buffer的数据组成方式为TLV,数据结构图如下:

其中Length不一定有,依据Tag确定,例如int类型的数据就只有Tag-Value,string类型的数据就必须是Tag-Length-Value

Tag块包含两块内容:数据编号、数据类型,Tag的生成规则如下:
(field_number << 3) | wire_type
其中Tag块的后3位表示数据类型,其他位表示数据编号
如00001|010,
file_num = 0001 = 1
type = 010 = 2
type=2,则后面有Length
Java中整数类型的长度都是确定的,如int类型的长度为4个字节,可表示的整数范围为-231——231-1,但是实际开发中用到的数字均比较小,会造成字节浪费,可变长度编码就能很好的解决这个问题,可变长度编码规则如下:
字节最高位表示数据是否结束,如果最高位为1,则表示后面的字节也是该数据的一部分, 如果最高位为0,则表示数据计算终止
举个例子:
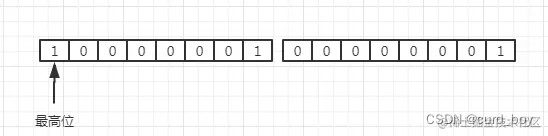
其中第一个字节由于最高位为1,则后面的字节也是前面的数据的一部分,第二个字节最高位为0,则表示数据计算终止,由于Protocol Buffer是低位在前,整体的转换过程如下:

10000001 00000011 ——> 00000110000001
表示的10进制数为:2^0 + 2^7 + 2^8 = 385
通过上面的例子可以知道一个字节表示的数的范围0-128,上面介绍的Tag生成算法中由于后3位表示数据类型,所以Tag中1-15编号只占用1个字节,所以确保编号中1-15为常用的,减少数据大小
可变长度编码唯一的缺点就是当数很大的时候int32需要占用5个字节,但是从统计学角度来说,一般不会有这么大的数
https://juejin.cn/post/6844903997292150791
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
