作者 | Jesus Rodriguez
译者 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
【导读】近几年,深度强化学习(DRL)一直是人工智能取得最大突破的核心。
尽管取得了很多进展,但由于缺乏工具和库,DRL 方法仍难以应用于主流的解决方案。
因此,DRL 主要以研究形式存在,并未在现实世界的机器学习解决方案中得到大量应用。
解决这个问题需要更好的工具和框架。
而在当前的 AI 领域,DeepMind 在推动 DRL 研发方面做了大量工作,包括构建了许多专有工具和框架,以大规模地简化 DRL agent 训练、实验和管理。
最近,DeepMind 又默默开源了三种 DRL 框架:OpenSpiel、SpriteWorld 和 bsuite,用于简化 DRL 应用。
作为一种新兴的深度学习技术,采用 DRL 面临着简单实现算法之外的诸多挑战,如训练数据集、环境、监测优化工具和精心设计的实验,以简化 DRL 技术的采用。
考虑到机制与大多数传统的机器学习方法不同(DRL agent 尝试在给定环境中通过反复试验来完成任务),应用 DRL 更是困难。
在这种情况下,环境和实验的稳健性在 DRL agent 开发的知识中起着最基本的作用。
下面我们开门见山,来看看这三种框架到底有什么特别之处,以及如何使用。
OpenSpiel
GitHub:
https://github.com/deepmind/open_spiel
游戏在 DRL agent的 训练中发挥着重要作用。
与其他数据集一样,游戏本质上基于试验和奖励
机制,可用于训练 DRL agent。但是,正如我们所想,游戏环境的复杂度还远远不够。
OpenSpiel 是一系列环境和算法,用于研究一般强化学习和游戏中的搜索/规划。
OpenSpiel 的目的是通过与一般游戏类似的方式促进跨多种不同游戏类型的一般多智能体强化学习,但是重点是强调学习而不是竞争形式。
当前版本的 OpenSpiel 包含 20 多种游戏的不同类型(完美信息、同步移动、不完美信息、网格世界游戏、博弈游戏和某些普通形式/矩阵游戏)实现。
核心的 OpenSpiel 实现基于 C ++ 和 Python 绑定,这有助于在不同的深度学习框架中采用。
该框架包含一系列游戏,允许 DRL agent 学会合作和竞争行为。
同时,OpenSpiel 还包括搜索、优化和单一 agent 等多种 DRL 算法组合。
安装
摘要
-
安装系统包并下载一些依赖项。
只需要运行一次。
-
安装 Python 依赖项,例如在 Python 3 中使用 virtualenv:
vvirtualenv -p python3 venv
source venv/bin/activate
pip3 install -r requirements.txt
使用 deactivate 退出虚拟环境。
-
构建并运行测试以检查一切是否正常:
-
添加
# For the python modules in open_spiel.
export PYTHONPATH=$PYTHONPATH:/<path_to_open_spiel>
# For the Python bindings of Pyspiel
export PYTHONPATH=$PYTHONPATH:/<path_to_open_spiel>/build/python
到 ./venv/bin/activate 或你的 〜/ .bashrc ,以便从任何地方导入 OpenSpiel。
为了确保 OpenSpiel 在默认配置上运行,我们使用 python3 命令而不是 python(现在 Linux 版本上仍默认为 Python 2)。
开发者指南
代码结构
一般来说,open_spiel 下的目录是 C ++(integration_tests 和 python 除外)。
open_spiel / python 中提供了类似的结构,包含 Python 等效代码。
一些顶级目录是特殊的:
-
open_spiel / integration_tests:
所有游戏的通用(python)测试。
-
open_spiel / tests:
C ++ 常用测试实用程序。
-
open_spiel / scripts:
用于开发(构建、运行测试等)的脚本。
例如,支持 C ++:
-
open_spiel /:
包含游戏抽象 C ++ API。
-
open_spiel / games:
包含 games ++实现。
-
open_spiel / algorithms:
在 OpenSpiel 中实现的 C ++ 算法。
-
open_spiel / examples:
C ++ 示例。
-
open_spiel / tests:
C ++ 常用测试实用程序。
支持 Python:
添加游戏
-
这里仅介绍添加新游戏最简单、最快捷的方式。
首先要了解通用 API(参见 spiel.h)。
从 games/中选择要复制的游戏。
推荐游戏:
Tic-Tac-Toe 和 Breakthrough,因为它们包含完美信息,没有偶然事件,Backgammon 或 Pig 用于完美的信息游戏与偶然事件,Goofspiel 和Oshi-Zumo 用于同步移动游戏,Leduc 扑克和 Liar 骰子用于不完美信息游戏。
以下步骤以 Tic-Tac-Toe 为例讲解。
-
将标头和源:
tic_tac_toe.h,tic_tac_toe.cc和tic_tac_toe_test.cc 复制到 new_game.h,new_game.cc 和 new_game_test.cc。
-
配置 CMake:
-
更新样板C ++代码:
-
-
在 new_game.h 中,重命名文件顶部和底部的标题保护。
-
在新文件中,将最内层的命名空间从 tic_tac_toe 重命名为 new_game。
-
在新文件中,将 TicTacToeGame 和 TicTacToeState 重命名为 NewGameGame 和 NewGameState。
-
在 new_game.cc 的顶部,将短名称更改为 new_game 并包含新游戏的标题。
-
更新 Python 集成测试:
-
现在,你有了一个不同名称的 Tic-Tac-Toe 复制游戏。
测试运行,并可以通过重建和运行示例 examples / example --game = new_game 来验证它。
-
现在,更改 NewGameGame 和 NewGameState 中函数的实现以表示新游戏的逻辑。
你复制的游戏中的大多数 API 函数都应该与原来的游戏有区分度。
如果没有,那么重合的每个API 函数都将在 spiel.h 中的超类中被完整记录。
-
完成后,重建并重新运行测试以确保一切都顺利(包括新游戏测试!
)。
-
更新 Python 集成测试:
SpriteWorld
GitHub:
https://github.com/deepmind/spriteworld
几个月前,DeepMind 发表了一篇研究论文,介绍了一种好奇的基于对象的 seaRch Agent(COBRA),它使用强化学习来识别给定环境中的对象。
COBRA agent 使用一系列二维游戏进行训练,其中数字可以自由移动。
用于训练 COBRA 的环境,正是 DeepMind 最近开源的 SpriteWorld。
Spriteworld 是一个基于 python 的强化学习环境,由一个可以自由移动的形状简单的二维竞技场组成。
更具体地说,SpriteWorld 是一个二维方形竞技场,周围可随机放置数量可变的彩色精灵,但不会发生碰撞。
SpriteWorld 环境基于一系列关键特征:
-
多目标的竞技场反映了现实世界的组合性,杂乱的物体场景可以共享特征,还可以独立移动。
此外,它还可以测试与任务无关的特征/对象的稳健性和组合泛化。
-
连续点击推动动作空间的结构反映了世界空间和运动的结构。
它还允许 agent 在任何方向上移动任何可见对象。
-
不以任何特殊方式提供对象的概念(例如,没有动作空间的特定于对象的组件),agent 也完全可以发现。
SpriteWorld 针对三个主要任务训练每个 DRL agent:
-
目标寻找。
agent 必须将一组目标对象(可通过某些功能识别,例如“绿色”)带到屏幕上的隐藏位置,忽略干扰对象(例如非绿色的对象)
-
排序。
agent 必须根据对象的颜色将每个对象带到目标位置。
-
聚类。
agent 必须根据颜色将对象排列在群集中。
安装
可以使用 pip 安装 Spriteworld:
或者通过 Github:
或者通过签出存储库的本地副本并运行:
git clone https://github.com/deepmind/spriteworld.git
pip install spriteworld /
最后一个选项是下载测试,演示 UI 和示例运行循环。
开始
前提
Spriteworld 依赖于numpy,six,absl,PIL,matplotlib,sklearn 和 dm_env。
演示
安装完成后,您可以通过 run_demo.py 熟悉 Spriteworld:
创建自己的任务
在 spriteworld / tasks.py 中有三个任务:
FindGoalPosition、Clustering 和 MetaAggregated。
可以以多种方式进行配置和组合,以创建各种任务,包括 COBRA 论文中使用的所有任务。
值得注意的是,可以参阅 spriteworld / configs / cobra / sorting.py,了解目标查找任务的组合。
你还可以创建新任务,重新使用这些构建块,或创建全新类型的任务(只需确保从 spriteworld / tasks.AbstractTask 中继承)。
运行agent
有关如何在 Spriteworld 任务上运行随机 agent 的示例,请参阅 example_run_loop.py。
如果你更喜欢 OpenAI Gym 环境界面,请参阅 spriteworld / gym_wrapper.py。
bsuite
GitHub:
https://github.com/deepmind/bsuite
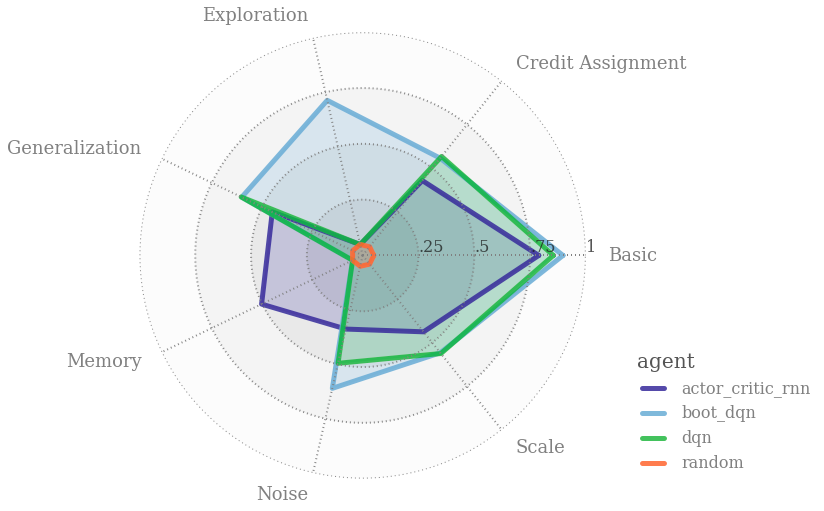
强化学习行为套件(bsuite,The Behaviour Suite for Reinforcement Learning )的目标是成为强化学习领域的 MNIST。
具体来说,bsuite 是一系列用来突出 agent 可扩展性关键点的实验。
这些实验易于测试和迭代,对基本问题,例如“探索”或“记忆”进行试验。
具体来说,bsuite 有两个主要目标:
bsuite 当前的实现可以在不同环境中自动执行实验,并收集可以简化 DRL agent 训练的相应指标。
如果你是一个 bsuite 新手,可以开始使用 colab 教程。
这款 Jupyter 笔记本电脑配有免费的云服务器,因此无需任何安装即可立即开始编码。
在此之后,你可以按照以下说明在本地计算机上运行 bsuite。
安装
我们已测试了 bsuiteon Python 3.6,且无维护 Python 2.7 版本的计划。
安装 bsuite,请运行该命令
或克隆该库并运行
想要能够编辑代码的同时安装软件包(请参阅下面的基线),请运行
要同时安装baselines//示例的依赖项(不包括Gym和Dopamine示例),请安装:
加载环境
环境由 bsuite_id 字符串指定,例如“deep_sea / 7”。
此字符串指定要使用的实验和(索引)环境设置。
import bsuite
env = bsuite.load_from_id('catch/0')
可以通过以下方式以编程方式访问运行所有实验所需的 bsuite_ids 序列:
from bsuite import sweep
sweep.SWEEP
该模块还包括每个实验名称对应的大写常量单 bsuite_ids,例如:
sweep.DEEP_SEA
sweep.DISCOUNTING_CHAIN
bsuite报告
你可以使用 bsuite 生成一个自动的 1 页附录,该附录总结了强化学习算法的核心功能。
本附录与大多数主要的机器学习会议格式兼容。
例如输出运行,
由于篇幅有限,无法一一详细介绍每个框架的具体使用方法,感兴趣的朋友们可以在上文 GitHub 链接中查询详情情况和使用指南,以检验OpenSpiel、SpriteWorld 和 bsuite 的真正实现效果,并欢迎在留言中与我们交流上手体验。
最后,相信随着越来越多的深度强化学习工具和框架的涌现,把这项新兴技术应用于现实世界的进程将大大加快,进一步推动 AI 研究和落地的进展。
原文链接:
https://towardsdatascience.com/deepmind-quietly-open-sourced-three-new-impressive-reinforcement-learning-frameworks-f99443910b16
(*本文为AI科技大本营整理文章,转载请微信联系 1092722531)
【结果提交倒计时】PV,UV流量预测算法大赛,结果提交截止时间为
9月20日
,还没有提交的小伙伴抓紧时间了~~9月25日公布初赛成绩。
最新排行榜请扫码查看。