社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
这个问题很重要,在各大博客、网站、甚至JSON官网会这样说:
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。 这些特性使JSON成为理想的数据交换语言。
其实你只需要知道它就是一种数据格式,简单易于传输和交换(交换说白了就是容易解析)。
但是我还是推荐看一下CJSON官网的详细介绍:
cJSON英文版
cJSON中文版
我个人觉得大家还是应该坚持看一下英文版的,因为大多说的一手资料都是英文版的,例如大多数github上的开源项目包括其说明文件readme.md都是用英文撰写的,所以如果英文不通的话会非常不适应。
首先 cJSON 解析器项目在宏观上主要分为两个部分:解析JSON数据包 (cJSON *parse_value(char *my_string))和构造JSON数据包(void create_objects())。
非常重要的辅助部分:内存管理部分( 这是非常重要的也是需要特别注意和小心的部分!)
源码的的组成较为简单:cJSON.h 和 cJSON.c 两源码文件,加一个 test.c 测试文件(同时也是主程序所在文件)
文件列表(两源文件加一个头文件)
* test.c
* cJSON.c
* cJSON.h
首先我先介绍一下cJSON结构体这对后面的理解至关重要!
typedef struct cJSON {
struct cJSON *next,*prev; /* next/prev allow you to walk array/object chains. Alternatively, use GetArraySize/GetArrayItem/GetObjectItem */
struct cJSON *child; /* An array or object item will have a child pointer pointing to a chain of the items in the array/object. */
int type; /* The type of the item, as above. */
char *valuestring; /* The item's string, if type==cJSON_String */
int valueint; /* The item's number, if type==cJSON_Number */
double valuedouble; /* The item's number, if type==cJSON_Number */
char *string; /* The item's name string, if this item is the child of, or is in the list of subitems of an object. */
} cJSON;从上面可以看出cJSON结构体中含有三个指针:指向子节点的指针cJSON* child
指向前后的指针cJSON* next cJSON* prev
int type代表的是数据类型,有7种,在头文件中被定义,代码如下:
#define cJSON_False (1 << 0)// 1
#define cJSON_True (1 << 1)// 2
#define cJSON_NULL (1 << 2)// 4
#define cJSON_Number (1 << 3)// 8
#define cJSON_String (1 << 4)// 16
#define cJSON_Array (1 << 5)// 32
#define cJSON_Object (1 << 6)// 64你会发现和后面所说的7种一一对应!
接下来看char *valuestring当数据类型是字符串时,其指向该字符串;int valueint当数据是整型是,其为该数值,当数据是浮点类型时,其为该值的整数部分;double valuedouble当数据是浮点是,其为该浮点值;char* string代表的是该节点的名称(例如键值对: "zhangqiquan": "female")这个例子来说 string指向"zhangqiquan", valuestring指向"female"!
从这个简单的例子可以看的很清楚明了!
我们从主函数开始分析:
int main (int argc, const char * argv[])
{
/* a bunch of json: */
char text1[]="{\n\"name\": \"Jack (\\\"Bee\\\") Nimble\", \n\"format\": {\"type\": \"rect\", \n\"width\": 1920, \n\"height\": 1080, \n\"interlace\": false,\"frame rate\": 24\n}\n}";
char text2[]="[\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\"]";
char text3[]="[\n [0, -1, 0],\n [1, 0, 0],\n [0, 0, 1]\n ]\n";
char text4[]="{\n \"Image\": {\n \"Width\": 800,\n \"Height\": 600,\n \"Title\": \"View from 15th Floor\",\n \"Thumbnail\": {\n \"Url\": \"http:/*www.example.com/image/481989943\",\n \"Height\": 125,\n \"Width\": \"100\"\n },\n \"IDs\": [116, 943, 234, 38793]\n }\n }";
char text5[]="[\n {\n \"precision\": \"zip\",\n \"Latitude\": 37.7668,\n \"Longitude\": -122.3959,\n \"Address\": \"\",\n \"City\": \"SAN FRANCISCO\",\n \"State\": \"CA\",\n \"Zip\": \"94107\",\n \"Country\": \"US\"\n },\n {\n \"precision\": \"zip\",\n \"Latitude\": 37.371991,\n \"Longitude\": -122.026020,\n \"Address\": \"\",\n \"City\": \"SUNNYVALE\",\n \"State\": \"CA\",\n \"Zip\": \"94085\",\n \"Country\": \"US\"\n }\n ]";
char text6[] = "<!DOCTYPE html>"
"<html>\n"
"<head>\n"
" <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n"
" <style type=\"text/css\">\n"
" html, body, iframe { margin: 0; padding: 0; height: 100%; }\n"
" iframe { display: block; width: 100%; border: none; }\n"
" </style>\n"
"<title>Application Error</title>\n"
"</head>\n"
"<body>\n"
" <iframe src="//s3.amazonaws.com/heroku_pages/error.html">\n"
" <p>Application Error</p>\n"
" </iframe>\n"
"</body>\n"
"</html>\n";
/* Process each json textblock by parsing, then rebuilding: */
doit(text1);
doit(text2);
doit(text3);
doit(text4);
doit(text5);
doit(text6);
/* Parse standard testfiles: */
/* dofile("../tests/test1"); */
/* dofile("../tests/test2"); */
/* dofile("../tests/test3"); */
/* dofile("../tests/test4"); */
/* dofile("../tests/test5"); */
/* dofile("../tests/test6"); */
/* Now some sample code for building objects concisely: */
create_objects();
return 0;
}你会看到其实源程序的结构很简单明了逻辑清晰
开始进入主函数
初始化六个字符串
char *text1[];
char *text2[];
char *text3[];
char *text4[];
char *text5[];
char *text6[];接下来你会看到主程序(main 函数)在调用doit(char *text)分别对六个字符串(char* text1到char* text6)进行处理,代码如下
doit(text1);
doit(text2);
doit(text3);
doit(text4);
doit(text5);
doit(text6);其实这一部分就是解析部分,只不过是解析函数被doit(char* text)调用,在其内部而已。
既然是这样那不妨我们进入到doit(char * text)函数内部看看—>
代码如下:
/* Parse text to JSON, then render back to text, and print! */
void doit(char *text)
{
char *out;
cJSON *json;
json=cJSON_Parse(text);//parse the string into a object(return the root of the object)
if (!json)
{
printf("Error before: [%s]\n",cJSON_GetErrorPtr());
}
else
{
out=cJSON_Print(json);//打印
cJSON_Delete(json);
printf("%s\n",out);
free(out);
}
}我们看到第三行代码
json=cJSON_Parse(text);//parse the string into a object(return the root of the object)这就是cJSON的解析函数,注意其返回一个指向JSON结构体的结构体指针!即把字符串解析成JSON数据结构。
在此我们还是不清楚解析过程是如何进行的。我们再进入到函数cJSON_Parse(text)中看看。
函数代码如下:
cJSON *cJSON_Parse(const char *value)
{
return cJSON_ParseWithOpts(value,0,0);
}从代码中可以看出函数cJSON_Parse(text)调用了cJSON_ParseWithOpts(value,0,0)函数(该函数的定义即说明解析有多种选择,需根据数据类型,type = null \false \true\number\string\array\ object有7种数据,解析方式必然是不一样的 )(层层调用)
下面我就步进到函数内部看看是不是这样!
代码如下:
cJSON *cJSON_ParseWithOpts(const char *value,const char **return_parse_end,int require_null_terminated)//require end with null char!
{
const char *end=0,**ep=return_parse_end?return_parse_end:&global_ep;
cJSON *c=cJSON_New_Item();
*ep=0;
if (!c) return 0; /* memory application fail */
end = parse_value(c,skip(value),ep);
if (!end)
{
cJSON_Delete(c);
return 0;
}/* parse failure. ep is set. */
/* if we require null-terminated JSON without appended garbage, skip and then check for a null terminator */
if (require_null_terminated)
{
end=skip(end);
if (*end)
{
cJSON_Delete(c);
*ep=end;
return 0;
}
}
if (return_parse_end)
*return_parse_end=end;
return c;
}我们会看到该函数又调用了函数 parse_value(c,skip(value),ep),其中也调用了skip(value)函数,该函数的功能是跳过回车、空格和控制字符(ASCII码制<=32)。
下面我再进入到函数parse_value(c,skip(value),ep)
代码如下:
static const char *parse_value(cJSON *item,const char *value,const char **ep)
{
if (!value) return 0; /* Fail on null. */
if (!strncmp(value,"null",4)) { item->type=cJSON_NULL; return value+4; }
if (!strncmp(value,"false",5)) { item->type=cJSON_False; return value+5; }
if (!strncmp(value,"true",4))
{
item->type=cJSON_True;
item->valueint=1;
return value+4;
}
//the difficulties exist in the following four types!
if (*value=='\"') { return parse_string(item,value,ep); } //parse string
if (*value=='-' || (*value>='0' && *value<='9')) { return parse_number(item,value); } //parse number
if (*value=='[') { return parse_array(item,value,ep); } //parse the array
if (*value=='{') { return parse_object(item,value,ep); } //parse object
*ep=value;
return 0; /* failure. */
}你会发现有8种情况(包括 value 是空的情况),其余的七中情况就是我之前在上面提到过的7种数据类型,value = null \false \true\number\string\array\ object不同类型会调用不同的解析函数,前3种较为简单。
解析过程和JSON数据的结构紧密联系所以之前的 cJSON英文版 cJSON中文版也是做此解析项目非常重要的地方。
所以这几个解析函数需要自己去琢磨,这样才能学到东西!
parse_string(item,value,ep);
parse_number(item,value);
parse_array(item,value,ep);
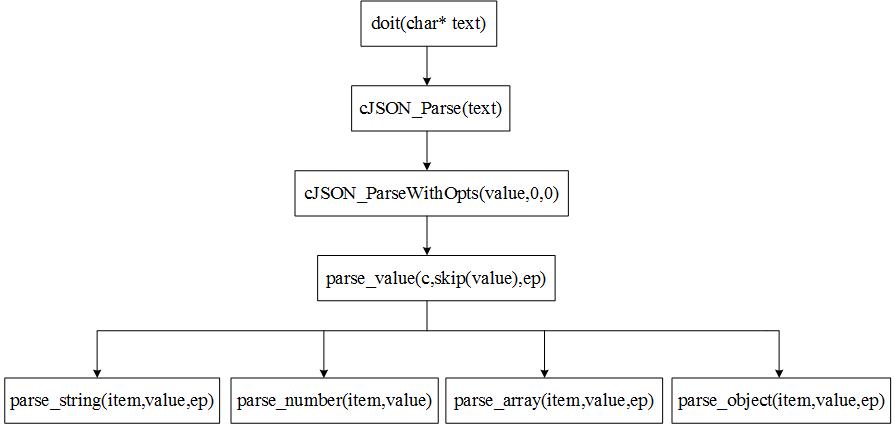
parse_object(item,value,ep);到这里我们基本清楚整个解析部分的函数是如何层层调用和施展的了!
上图为层层调用的关系图!(也可以说是对上面解析部分的一个总结!)
下一部分为构造部分:待续!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!