社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Reids是单线程!
Reids是单线程!
Reids是单线程!
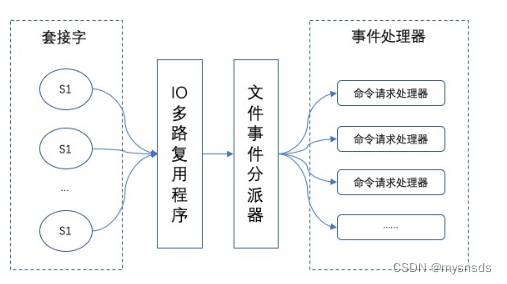
Redis架构模型:Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型 ,即文件事件处理器
主要是包含 4 个部分:
堵塞:一个线程一次只能处理一个。
select和poll和epoll同一时间一个线程可以处理多个,所以不是堵塞。
含义:I/O 指的是网络I/O。
多路指的是多个TCP 连接(Socket 或Channel)。
“复用”指的是复用同一个线程 。
作用:Redis 通过IO 多路复用程序 来监听来自客户端的大量连接(或者说是监听多个 socket)
优点:I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)
过程:
数据类型: fd_set就是一个long int类型的数组。因为每一位可以代表一个文件描述符。所以fd_set最多表示1024个文件描述符
调用过程:
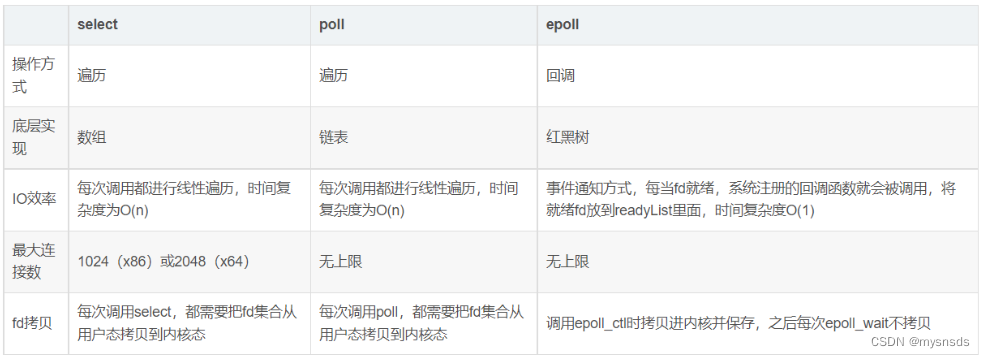
select 是操作系统提供的系统调用函数,select 只能监听 1024 个文件描述符,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理,不过,当 select 函数返回后,用户依然需要遍历刚刚提交给操作系统的 list。
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销。
问题
数据结构: pollfd 结构
**作用:**它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
数据结构:链表加红黑树
链表存储:活跃连接,红黑树存储:socket节点
链表中为活跃的链接,红黑树中放的是所有事件。这样一来,当收到内核的数据时,只需遍历链表中的数据就行了,而注册read事件或者write事件的时候,向红黑树中记录。
调用过程:
epoll_create() 系统启动时,在 Linux 内核里创建 epoll 实例(申请一个红黑树 rbTree 和就绪链表 readyList),以便存放 socket 节点;
epoll_ctl() 每新建一个连接,都通过该函数操作 epoll 对象,在这个对象的红黑树里增、删、改对应的 socket 节点,绑定一个回调函数;
epoll_wait() 阻塞唤醒,只遍历一次,之后等待事件异步唤醒数据传入,并完成对应的 IO 操作。相应分三步:
改进:
内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
如果没有I/O事件产生,我们的程序就会阻塞在select处。有个问题,我们从select仅知道了有I/O事件发生了,但却不知是哪几个流,只能无差别轮询所有流,找出能读或写数据的流进行操作。
使用select,O(n)的无差别轮询复杂度,同时处理的流越多,每一次无差别轮询时间就越长。
原因有下面 3 个:
Redis在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。但如果严格来讲从Redis4.0之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等。
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理80,000到100,000 QPS,这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的QPS。常见的解决方案是在分布式架构中对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的Redis服务器太多,维护代价大;某些适用于单个Redis服务器的命令不适用于数据分区;数据分区无法解决热点读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从Redis自身角度来说,因为读写网络的read/write系统调用占用了Redis执行期间大部分CPU时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
• 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
• 使用多线程充分利用多核,典型的实现比如 Memcached。
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
• 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
• 多线程任务可以分摊 Redis 同步 IO 读写负荷
Redis6.0的多线程默认是禁用的,只使用主线程。
Redis多线程参考:https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw
参考:https://blog.csdn.net/weixin_35973945/article/details/124153253
https://blog.csdn.net/lmx125254/article/details/118935332
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
