社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1.hive导入hdfs数据
hive> load data inpath '/version/hive/file' into table bigdatacar.car_document;
2.HIve清空表中的数据
truacte table test;
3.shelll获得时间
//完整时间
$(date +'%Y-%m-%d %H:%M:%S')
//日期
$(date +%Y-%m-%d)
3.sqoop从hdfs中读取文件导入到本地数据库中脚本如下:taopaichetoMysql.sh
//数据库加上utf-8不然会差生中文乱码
sqoop export --connect "jdbc:mysql://192.168.1.38:3306/bigdatacar?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 1234 \
//改地址为hdfs中的地址
--export-dir '/version/taopaiche.txt' \
--table taopaicar_color \
--fields-terminated-by '\0002' \
--input-fields-terminated-by '\t' \
--lines-terminated-by '\n' \
-m 1
如果导入的过程中报job错误如下
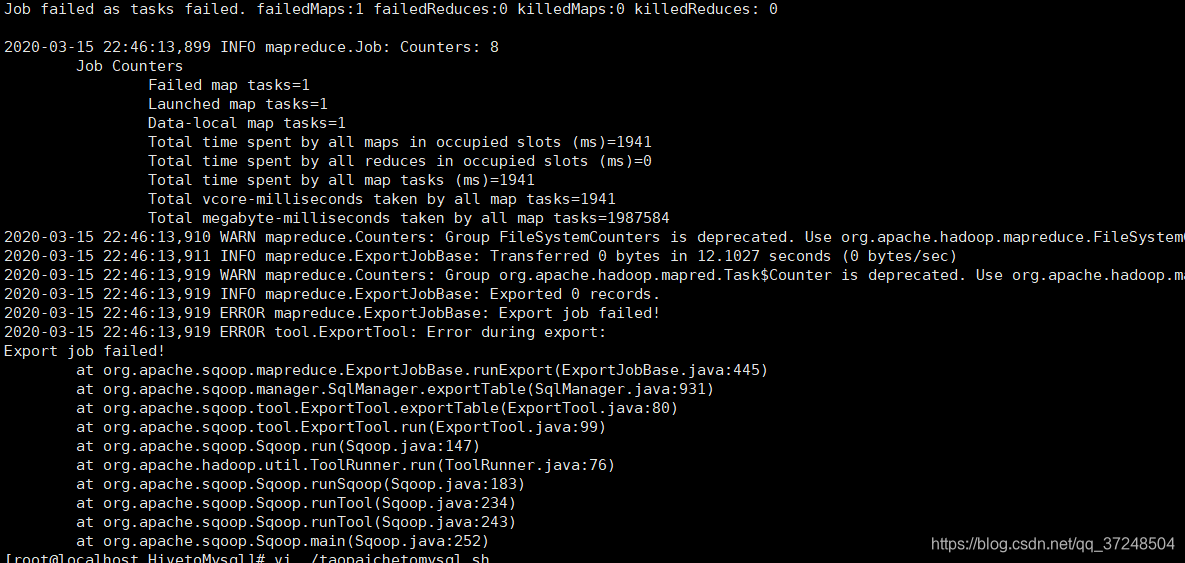
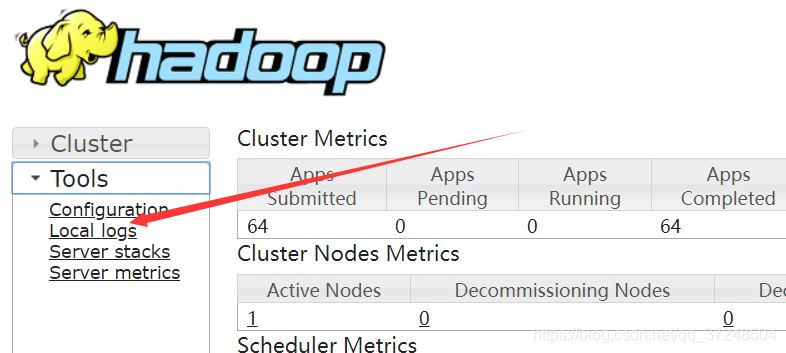
查看Mapreduce过程中的日志文件,点击local logs进入userlogs/文件夹
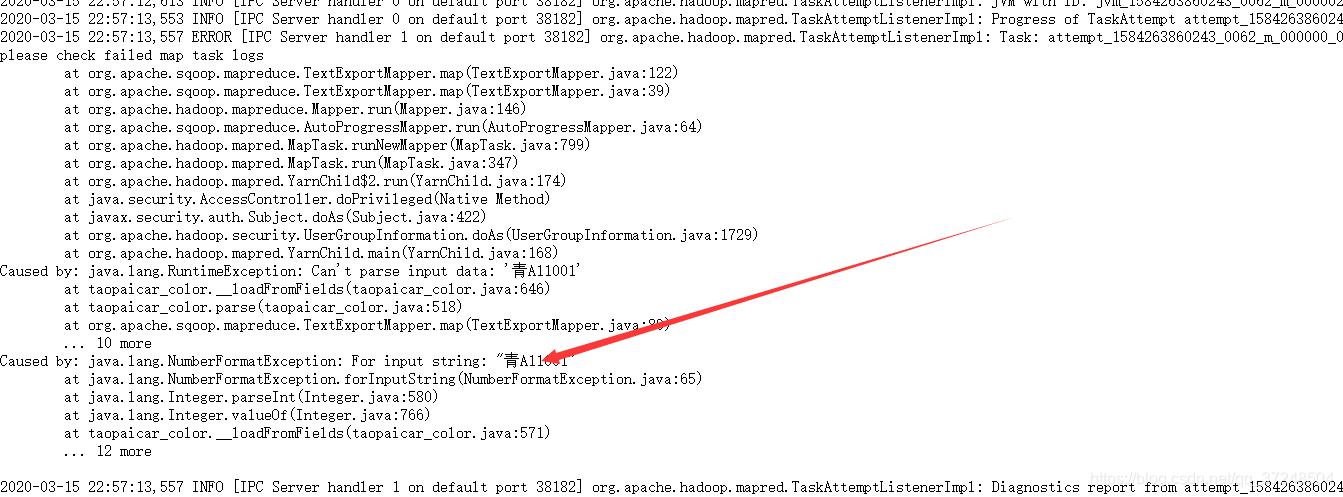
日志消息为本地数据库中的表和读取的字段不兼容,应该是字段顺序或者字段的类型问题,修改就可以。样例数据如下。

数据库中的字段如下:文件中的字段顺序如下,修改啊字段顺序和类型即可。

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
