社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
最近,Google的Golang荣获2016年度编程语言,作为一个谷粉,我理应写一篇文章以表祝贺,正好碰上最近在弄一个支持IO无锁并发的脚本引擎,参考了一些Go内部的设计思想,真想不到Go的萌萌的外表下竟隐藏着一颗如此强大的内心,本文主要的分析焦点就是做到更干净的并发编程,让并发编程的代码更加优雅~
首先,我们要写一个并发多任务的程序,首先想到多线程。。。不妨假设一个简单的例子,生产者-消费者模型,生产者负责生成资源,消费者消耗之,一般来说,消费者的处理速度是远不及生产者的产生速度,比如高并发的服务中的MQ,在单进程的环境下可以考虑两个线程完成这个模型,一个线程负责生成数据(客户端的request),一个线程负责处理这些request,显然速度的差异带来的结果就是需要一个异步队列来存放请求,真正的MQ可能会有很多个生产者,也有很多个消费者,我用python来模拟一下上述的情况,
def produce():
print('produce loop thread start')
while True:
while len(asyncQueue) < threshold:
try:
lock.acquire()
asyncQueue.append('task')
print('add a request to queue')
finally:
lock.release()
def consumer():
print('consumer loop thread start')
# time.sleep(600)
counter = 0
while True:
time.sleep(6)
if not len(asyncQueue):
counter = counter + 1
if counter >= 3:
return
continue
try:
lock.acquire()
task = asyncQueue[0]
print('consuming queue, current size of queue is %d' % len(asyncQueue))
callabck(task)
time.sleep(5)
asyncQueue.pop(0)
finally:
lock.release()可以把这些实现放到两个线程中跑,通过多线程的配合,可以很好完成我们的并发任务,然而,这种方式的代价是同步问题,需要互斥锁,锁这种东西是很容易就出现dead lock 这类很尴尬的问题的,而且,线程的切换对于操作系统来说可不是一件小事,虽然当前的page还在内存里,但这种调度发生在内核态,保存原线程的堆栈进stack segment,加载目标线程的堆栈进寄存器,最终跳到它的入口地址,在多线程并发的环境下,用户态会和内核态频繁切换,如果没有内存映射措施对的话,就会不断发生数据的拷贝,这是很消耗CPU资源的一件事,所以在高并发下,多线程比较简单粗暴,但并不是一种很优雅的实现。
那么怎样才比较fashion呢,首先,考虑无锁,其次,如果我们把内核态的调度转移到用户调度,把线程这个概念再抽象一层,我们自己来实现线程,自己来完成线程的调度,这种自己定义的线程完全可以按照自己的需要进行设计,调度,共同协作完成任务,考虑使用协程(Coroutine),我现在用协程的概念再用单线程无锁的方式实现一次生产者-消费者模型,python没有协程的工具包,但可以用生成器(generator)来代替,
def produce():
r = ''
print('switch to await')
while True:
res = yield r
# print type(r)
if not res:
continue
print('get result ==> %d' % res)
r = 'finish'
def consumer(gen):
# initialize generator
gen.send(None)
n = -1;
while n < 5:
n = n + 1
# switch to produce for resource
print('producting resource %s...' % n)
r = gen.send(n)
print('consuming resource %s...' % r)
gen.close()
gen = produce()
consumer(gen)其实基本的概念很简单,假设有两个任务Y1,Y2,Y1执行到一段时间发现它需要依赖另一个任务Y2的结果才能执行下去,于是它就很慷慨的让出CPU时间,对应于上面代码的yield 于是调度器获得执行,然后决定执行Y2,等到Y2产生Y1等待的结果后,Y2再将控制权交回到调度器,调度器再次唤醒Y1,让它接受Y2传递的结果从上次暂停的地方继续执行,这就是基本的工作流程,直到所有的任务都被协作完成,整个流程无需多线程,无锁,代码实现非常干净~
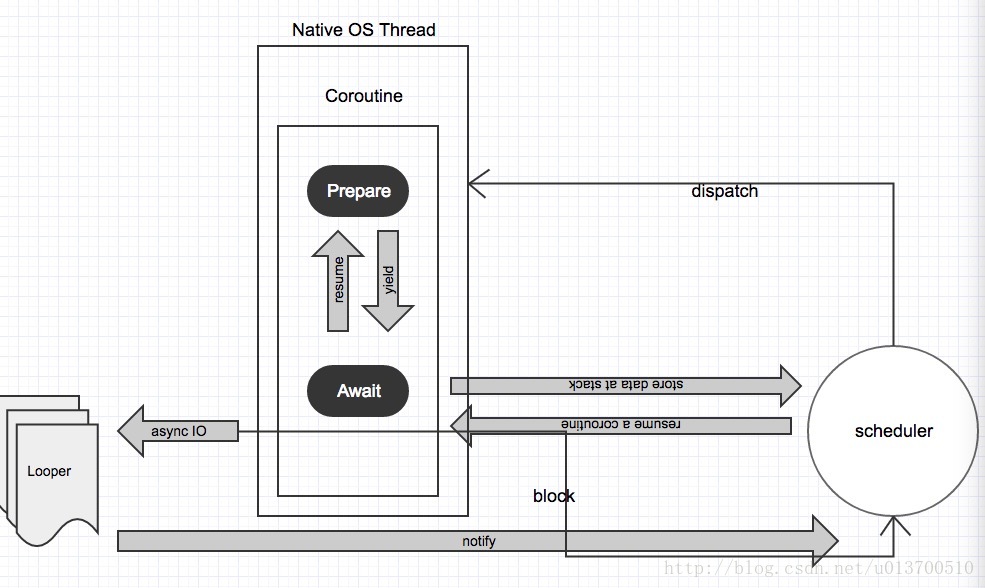
如果要实现一个高并发的IO模型,如何发挥协程的优势呢,首先来看看Node怎么搞的,Node的威力依赖于OS的AIO,网络的IO完全是可以真正意义异步的,然而大量数据库的磁盘IO无能为力,还是依赖底层的线程池分配一个线程阻塞等待(休眠),不能再休眠时间干别的事情,涉及线程池,上面说的切换代价就必不可少了,无独有偶,我在设计引擎的并发模块时参考了Go的内部设计,发现它几乎解决了线程池并发以及协程的一切痛点,于是我选择了一种新的并发模型,将OS内核态的工作自己在用户态手动完成,首先系统真正意义上的线程即native thread 我称为一个container 即上面运行很多更小的运行单元(线程相当于原子,协程单元类比为夸克),她们由协程的调度器进行调度,处于用户态,基本的架构如下
协程单元(之后简称为cor)可以先考虑它会在两个状态之间切换,当然实现起来会有两外的一个初始态和一个调度插入态,当cor遇到yield后,就会保存当前的运行堆栈,跳到调度器的代码段,进入Await状态,等待调度器下一次带着结果将它唤醒,这部分协程级的调度我用下面的代码模拟,
//similar to NThreadScheduler
//In this case, asynchronous task such as NetworkIO which is handled via AIO is handled by coroutine instead of NThreads, which scheduled by system suitable for muti-processers
//but some IO for Disk like database depends on NThread Scheduler to give up and find other hosts
void CorScheduler::Dispatch(msg_t msg) {
//M:N dispatcher
if (priority_cors.IsEmpty()) return;
switch (msg.type) {
case msg_t::kCorEnded:
//a cor yields
case msg_t::kCorsAwait:
__msg_type__ cor_id = msg.content;
//take out the one who has largest priority
//compute via 'M = Y * A', in which 'M' is for priority vector, 'Y' is matrix for resource occupied by cors
//and A is a weight vector, this list is sorted by priority
//FOREACH_EXCEPT_AWAIT(except, set, operation:Lamda expression)
//when 'Await', continue
FOREACH_EXCEPT_AWAIT(cor_id, priority_cors, [](const CoroutineUnit& cor) {
//cors interact with 'args'
if (cor.status == CoroutineUnit::kPreparing)
cor.Start();
else {
cor.Resume(ref_running.args);
}
});
break;
//for preemption
case msg_t::kCorsInterrupt:
//compute cpu usage info and IO time
//predicted by last IO time
auto status = ref_running.status;
_assert(status == CoroutineUnit::kRunning || status == CoroutineUnit::kPreparing);
auto res_info = AnalysisYRes(msg.content);
auto winner = OptimizeRes(ref_running.id, msg.content);
CoroutineUnit& intr_cor = *static_cast<CoroutineUnit*>(msg.data);
if (winner.id == ref_running.id) return;
//current cor -> Await state
auto args = ref_running.Yield();
intr_cor.SetArgsForRes(args);
//only preparing cor can interrupt a running cor
_assert(intr_cor.status == CoroutineUnit::kPreparing);
intr_cor.Start();
break;
//when looper notify scheduler that asynchronous tasks are fullfilled
case msg_t::kCorsAsyncFullfilled:
CoroutineUnit& yielded_cor = *static_cast<CoroutineUnit*>(msg.data);
_assert(yielded_cor.status == CoroutineUnit::kAwait);
auto args_map = SearchForArgs();
if (ref_running.status == CoroutineUnit::kDying) {
yielded_cor.Resume(args_map);
} else {
yielded_cor.Interrupt(args_map);
}
break;
}
}在这个调度器中我设计了一个优先规则,定义一个资源分配矩阵Y,元素为Yst,为cor[s]在t时刻占有资源R[t]的量,定义一个资源权重矩阵A,优先级向量M = Y * A 权重可以根据当前性能限制设定,比如主DBIO的情况下,IO时间短的具有优先级,可以插入长IO操作,提升CPU利用率,堆上分配的内存也可以量化进Y矩阵,代码中所有关于优先级的分析都是基于Y矩阵分析,上面还有一个状态专门描述从AIO尤其是网络IO是不会阻塞当前线程,所以交给当前的cor执行就可以,只有阻塞了当前线程,线程级的调度器才会考虑解决办法。
状态的切换的描述也是比较简单的
void* CoroutineUnit::Yield() {
StoreContext();
this->status = kAwait;
//pass its args to all cors
auto res = SpreadArgsAll(this->scheduler->priority_cors, this->arg_expr);
return res;
}
void CoroutineUnit::Resume(__args_list_type__& args) {
RetrieveContext();
this->status = kRunning;
SetArgsForRes(args);
}假设我们有N个协程,又一个进入等待状态,那么如果它需要向它的合作者传递一个信息,嘿,我目前的进展是这个,你接着我这个继续往下干呗,但这样很难知道究竟要向哪一个目标传达,为了简单粗暴(而且由于线程级调度的存在,容器跟cor的耦合度不能太高,cor集合是可能变化的),直接就让它对着N - 1个协程发个广播消息,你们听好啦,我现在干到这一步,如果你们中谁有幸接替了我的工作,就根据这个信息继续干,我睡觉去了哈~
现在问题来了,如果当前的cor阻塞了整个线程,线程级调度该怎么解决,要知道,还有很多cor基于这个container 等着执行,所以容器不行了,第一件事就是及时切换容器,我们需要分析当前线程的负载状况,找出一个比较闲的线程(如果没有线程,就分配一个新的),将剩余的cor装进去,丢下正在pending状态的cor以及它的NThread ,然后过了那么一段时间,这个被遗忘的cor终于从漫长的阻塞中返回了,然而它却处于一个空负载的状态,所以它需要。。去偷cor,先去看看其它的线程有没有机会下手,比如看看哪个线程负载特别繁重,那就偷它的,或者大家都很清闲,那就偷全局的cor队列,这个全局队列都是由一些孤儿组成,当孤儿cor寻找宿主时会通过Y矩阵计算优先级向量,将一些优先级低的cor暂时放在全局队列,等待复苏的线程进行接管,由于这个时间延迟不确定,所以只能选择优先级低的cor,再来模拟一下线程级的调度
void NThreadScheduler::Dispatch(msg_t msg) {
if (this->pool.size() < kNThreadPoolSize) {
CreateNewNThread(kNThreadPoolSize - this->pool.size());
}
switch (msg) {
case msg_t::kNThreadsBlock:
//we will find another idle thread
NThread t_idle = this->pool.Retrieve();
NThread t_block = this->pool.Get(msg.content);
TransferContext(t_block, t_idle);
break;
case msg_t::kNThreadsLoopSysCallReturn:
//search for globalRunQueue and steal from others
NThread t_retrieved = this->pool.Get(msg.content);
auto target = AnalysisUnbalance();
if (target) {
t_retrieved.appendCors(StealCors(target.president->cors, Common::Fix(target.president->cors.size() / 3)));
return;
}
if (!globalRunQueue.IsEmpty()) {
//just comsume 1/6 of this queue, for balance
size_t ns = Common::Fix(globalRunQueue.size() / 6);
t_retrieved.appendCors(StealCors(globalRunQueue, ns));
}
break;
case msg_t::kNThreadsRun:
__assert(this->pool.IsInitialized());
this->pool.StartAllTask();
}
}可以看到状态kNThreadsBlock 跟kNThreadsLoopSysCallReturn 描述了线程进入阻塞以及复苏,基本跟上面描述的过程一致,不过我添加了一些控制负载均衡的系数,其实这里的NThread 还是维护在一个池对象里面,不过用户级控制的比重大大增加,而且可以看到,通过协程,现在我们定义的线程处理多任务的能力是大大提升了,传统线程池线程阻塞后基本它之后的代码无法执行,然而现在线程执行的任务被拆分成很多个cor,阻塞只会影响其中一个cor,其它属于这个线程的代码会以其它cor的形式转移给其它线程,针对现在多核架构这个利用率将是很高的。
转移线程的过程也是一个偷取过程,目标线程将阻塞线程剩余的cor都偷去过来,然后跟自己的优先级进行优先级向量的比较,进行适当的cor的优先调度,这样CPU将会很高效地帮我们干活~
void NThreadScheduler::TransferContext(NThread& from, NThread& dest) {
auto new_cors = StealCors(from.president->cors, from.president->cors.size() - 1);
dest.appendCors(new_cors);
//remove all the idle cors
from.ClearIdle();
//interrupt the current and adjust the queue, maybe some cors will be pushed to the global queue
auto optimal_cor = CorScheduler::SelectOptimalCor(new_cors);
dest.president->Dispatch({ msg_t::kCorsInterrupt, optimal_cor.id, &optimal_cor });
}OK,这种并发模型的核心部分原理基本就是这样,威力是非常强大的,看看Go,就知道这东西有多厉害~~
当然还有一些网络IO库采用这种并发模型,其实大致的思想是类似的,都是想让线程发挥更大的效能,当然,我在自己的轮子中还是可以继续借鉴一下这种方式的,目前在设计脚本的并发模块yarm,之后再来给大家分享网络模块pink,以及VM Zygotor,代码之旅,永不停息~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!