社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
一 、kfka:
kafka是apache下一款由scala(面向对象和函数的语言)编写的发布-订阅式(push-subscribe)消息系统。
二、优点:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
三、Kafka一些重要设计思想
0---表示不进行消息接收是否成功的确认;
1---表示当Leader接收成功时确认;
-1---表示Leader和Follower都接收成功时确认;
三、Kafka一些重要设计思想
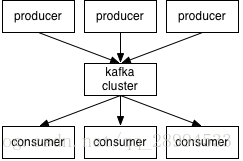
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
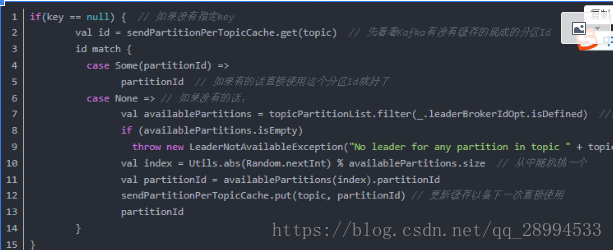
所以,如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
四、Consumer个数与分区数有什么关系?
topic下的一个分区只能被同一个consumer group下的一个consumer线程来消费,但反之并不成立,即一个consumer线程可以消费多个分区的数据,比如Kafka提供的ConsoleConsumer,默认就只是一个线程来消费所有分区的数据。
所以,如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
五、Consumer消费Partition的分配策略
Kafka提供的两种分配策略: range和roundrobin,由参数partition.assignment.strategy指定,默认是range策略。
当以下事件发生时,Kafka 将会进行一次分区分配:
将分区的所有权从一个消费者移到另一个消费者称为重新平衡(rebalance),如何rebalance就涉及到本文提到的分区分配策略。
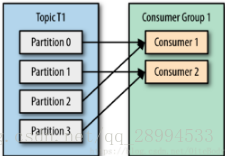
下面我们将详细介绍 Kafka 内置的两种分区分配策略。本文假设我们有个名为 T1 的主题,其包含了10个分区,然后我们有两个消费者(C1,C2)
来消费这10个分区里面的数据,而且 C1 的 num.streams = 1,C2 的 num.streams = 2。
Range strategy
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。在我们的例子里面,排完序的分区将会是0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C2-1。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端。
RoundRobin strategy
使用RoundRobin策略有两个前提条件必须满足:
所以这里假设前面提到的2个消费者的num.streams = 2。RoundRobin策略的工作原理:将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,看下面的代码应该会明白:
最后按照round-robin风格将分区分别分配给不同的消费者线程。
在这个的例子里面,假如按照 hashCode 排序完的topic-partitions组依次为T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9,我们的消费者线程排序为C1-0, C1-1, C2-0, C2-1,最后分区分配的结果为:
多个主题的分区分配和单个主题类似。遗憾的是,目前我们还不能自定义分区分配策略,只能通过partition.assignment.strategy参数选择 range 或 roundrobin。
六、 Kakfa的设计思想
- Kakfa Broker Leader的选举:Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
参考地址:https://blog.csdn.net/OiteBody/article/details/80595971
参考地址:https://blog.csdn.net/suifeng3051/article/details/48053965#commentBox
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!