社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Kafka是LinkedIn开发并开源出来的一个高吞吐的分布式消息系统。其具有以下特点:
1) 支持高Throughput的应用
2) scale out:无需停机即可扩展机器
3) 持久化:通过将数据持久化到硬盘以及replication防止数据丢失
4) 支持online和offline的场景。
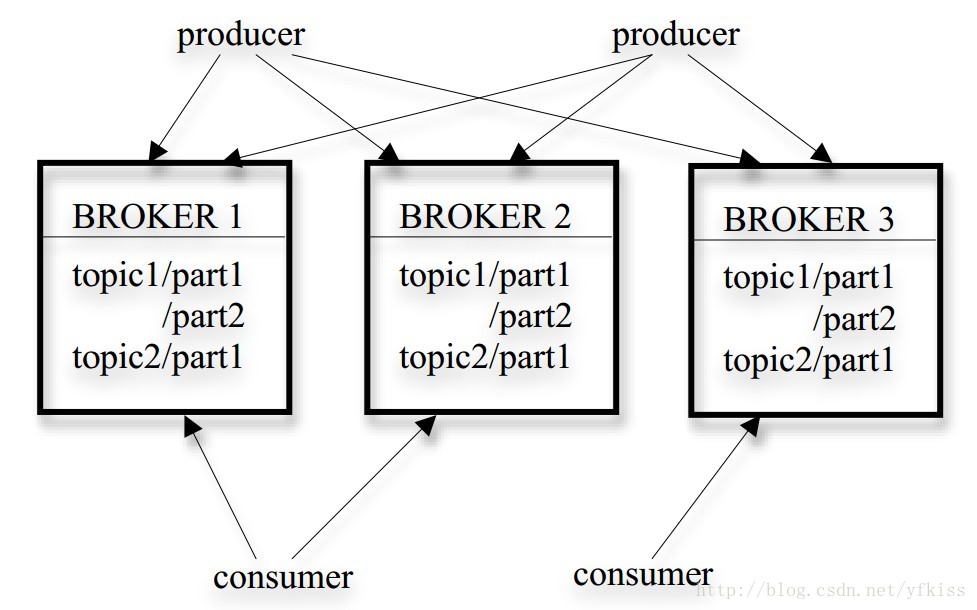
kafka的消息分几个层次:
1) Topic:一类消息,例如page view日志,click日志等都可以以topic的形式存在,kafka集群能够同时负责多个topic的分发
2) Partition: Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
3) Message:消息,最小订阅单元
具体流程:
1. Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
2. kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
3. Consumer从kafka集群pull数据,并控制获取消息的offset
load balance&HA
1) producer根据用户指定的算法,将消息发送到指定的partition
2) 存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上
3) 多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over
4) 通过zookeeper管理broker与consumer的动态加入与离开
pull-based system
由于kafka broker会持久化数据,broker没有内存压力,因此,consumer非常适合采取pull的方式消费数据,具有以下几点好处:
1)简化kafka设计
2)consumer根据消费能力自主控制消息拉取速度
3)consumer根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等
Scale Out
当需要增加broker结点时,新增的broker会向zookeeper注册,而producer及consumer会根据注册在zookeeper上的watcher感知这些变化,并及时作出调整。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
