社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
为了实现组合性、可扩展性和容错性,Goka鼓励开发者通过使用emitters(发射者)、processors(处理者)和views(视图,group表的持久高速缓存)三种组件来分解application到微服务中。下图描绘了使用的三种组件、kafka和扩展的API的架构图。
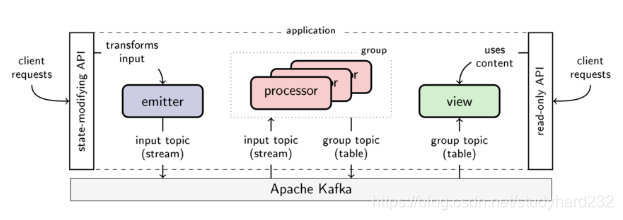
emitters.发射者,在kafka的视角相当于生产者,emitter将事件作为key-value message形式发送给kafka。API提供给开发者,可以自定义emitter的一些配置。
processors.处理者,是一组回调函数的集合。当新消息到达,processor会修改key-value table的内容。processor会消费input topics,当有新消息m到达某一个input topic,相应的回调函数便会被调用。接着回调函数会修改table中与消息m的key对应的value。
Processor groups.处理者组,在kafka的视角相当于消费者组,并且与它需要维护修改的group表(表示处理者组状态)进行绑定。处理者组的多个processor实例可以划分消费input topic和更新table的工作。这些实例属于同一个处理者组。
Group table and group topic.每一个处理者组都绑定到一个table,并且单独拥有写访问权。这个table被称作group table。group topic跟踪group table的更新,并且允许processor实例的恢复和再平衡。每一个processor实例会将负责的分区内容保存到本地存储,默认为leveldb。磁盘中的本地存储允许较小的内存占用并最大限度地缩短恢复时间。
view.视图,group table的持久高速缓存。订阅group topic的所有分区的更新,维持本地磁盘存储与group table的同步工作。另外,通过view,可以通过例如gRPC轻松地提供group table的最新内容。
processor可以通过调用ctx.Emit()发送一些消息到其他流的topic,并且可以通过调用ctx.Join()和ctx.Lookup()从其他processor groups的table中读值。
当使用Goka的构建块来分解应用的时候,便可以很容易地复用其他应用的table和topic,从而扩展应用的边界。下面是两个应用程序用户状态和点击计数,共享topic和table的例子。
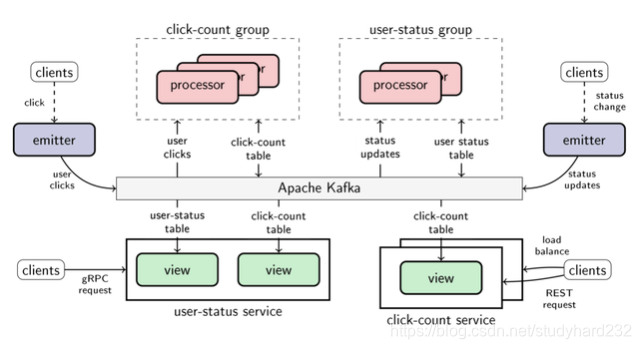
点击计数。只要用户单击特定按钮,emitter就会发送用户单击事件。点击计数processor会计算用户执行的点击次数。点击计数服务通过REST接口提供对点击计数表内容的读访问权限。复制该服务以实现更高的可用性和更短的响应时间。
用户状态。用户状态处理器跟踪平台中每个用户的最新状态消息 - 让我们假设我们的示例是社交网络系统的一部分。只要用户更改其状态,emitter就负责生产状态更新事件。用户状态服务提供用户的最新状态(来自用户状态)以及用户执行的点击次数(来自点击次数)。对于连接表,服务只是为每个表实例化一个视图。
需要注意的是,emitter不必与任何特定的Goka应用程序相关联。它们通常只是简单地嵌入到其他系统中,只是为了宣布要按需处理的相关事件。另外,只要使用相同的编码解码规则对消息进行编码和解码,Goka应用程序就可以与Kafka Streams,Samza或任何其他基于Kafka的流处理框架或库共享流和表。
emitters,发射者是相当简单的组件,可以通过实例化多个发射者来达到扩展的效果。发射者的限制因素是kafka可以承担的最大负载,最大负载取决于可用节点数量,分区总数,消息的大小和可用的网络带宽。
processors,可以通过实例化多个processor来达到扩展的效果。一个processor group的所有input topic都需要与group topic共同分区,使得input topic和group topic拥有相同数量的分区和相同的键范围。这样做使得Goka可以使用kafka的Rebalance机制一致地为processor实例分配工作,并且将所有topic(包括input topic和group topic)的分区组合在一起,然后将这些分区组一次分配给processor实例。例如,如果为processor A分配了input topic的分区1,那么也会为A分配其他input topic的分区1和group table的分区1。
每个processor实例仅保留其负责分区的本地副本,并且仅会消费这些分区而产生流量。而当某个processor实例出现故障时,其余实例会分享这个故障实例的工作和流量,使得流量和存储要求会发生改变。
views,本地视图包含他们订阅的完整table的副本。如果通过使用一个view实现服务,则可以通过生成服务的另一个副本来扩展服务。view的每个实例都使用group table的所有分区,而且每个view实例都将table的副本保存在本地存储中,从而增加磁盘的使用量。事实上,内存占用量不一定与磁盘占用空间一样大,因为只有用户经常检索的键值才会被LevelDB高速缓存在内存中。
emitters,发射者完成指定topic的消息发送后,该消息将会保证由订阅该topic的processor处理。如果发送了两条消息,processor也会按照相同的顺序处理。
processors,保证每条输入消息至少处理一次。作为kafka的消费者,processors会持续跟踪他们处理的每个topic的分区。只要输入消息被完全处理并且processor的输出持久化到了kafka后,processor便会将输入消息的偏移量提交到kafka。
如果processor在提交消息偏移量之前崩溃,则会在恢复之后再处理该消息,并进行相应的table的更新和输出消息。如果该processor实例未恢复,则group会进行Rebalance,为剩余processor实例分配失败实例的所属分区,kafka中的每个分区由不同的processor以相同的顺序消费,因此状态更新在恢复后会以相同的顺序重新消费,即使是另一个processor实例也会如此。
view,视图最终会看到它所订阅的table的所有更新,因为处理器组会将每个group table的修改消息发送到group table中。但是当processor group在一次失败后重新处理消息,视图可能会断断续续。如果视图本身出现失败,可以在其他地方(重新)实例化并从Kafka中恢复其所属的table。
type cbContext struct {
ctx context.Context // 标准库的context对象
graph *GroupGraph // 处理者组的对象
commit func() // 在process.go/process方法中赋值
emitter emitter // 同样在process.go/process方法中实现并赋值
failer func(err error)
storage storage.Storage // 当处理者为有状态的时候,才会被赋予本地存储的对象
pviews map[string]*partition // string为topic名
views map[string]*View // string为topic名
pstats *PartitionStats // 分区状态指标
msg *message // 处理者消费到的原始数据
done bool
counters struct {
emits int
dones int
stores int
}
errors multierr.Errors
m sync.Mutex
wg *sync.WaitGroup
}
处理者组中的Input Edge使用到回调函数。通过实现func(ctx Context, msg interface{})方法,第二个参数是消费到的反序列化后的消息数据,第一个参数保证了用户可以大展拳脚,这里的ctx是context.go中cbContext对象,其中包含了goka几乎所有重要的结构对象,所以通过实现自定义的回调函数,可以很自由地实现过滤、填充、翻译、简单的聚合和join操作等等(goka的issue中有提到过聚合和join的实现思路)。这样将具体流处理的业务逻辑函数以回调函数的形式分离出整个流处理结构。在诸多单一具体简单的流处理实际场景中,代码效率和可复用性便大大提高了。
HWM(high water mark)高水位线,在goka项目中指下一条消息被消费的偏移量。processor在完成创建分区和更新即将被消费的消息的偏移量之后,才真正进行流的消费。
在processor.go/process方法中,新建了一个cbContext的实例,其中的一个名为emitter的field,被赋给了一个实现的匿名函数。
emitter: func(topic string, key string, value []byte) *kafka.Promise {
return g.producer.Emit(topic, key, value).Then(func(err error) {
if err != nil {
g.fail(err)
}
})
},
用户在实现自己有关input的Edge的回调函数时,结束前需要执行ctx.SetValue()或ctx.Emit(),这两个方法内部会执行ctx的emitter的函数,将消息发送指定topic中。而ctx.SetValue()还会更新group table中指定key的value。所以简单做一下比较,ctx.SetValue()是对所属的processor group进行的操作,而ctx.Emit()则是对其他的processor groups进行的操作。
goka中名为kafka的包里有一个promise.go文件,借鉴了“Future and Promise”,promise是一种用来包装与组合可预测的未来值,且易复用的机制。这里的使用场景并不复杂,只是单单对异步写消息到kafka的topic这一操作进行了promise。当创建生产者实例的时候会同时启动一个goroutine用来监听等待解析(resolve)或拒绝(reject)一个promise(生产消息是否成功),通过调用producer.Emit(…).Then(…),生产者实例在调用Emit()方法后会返回一个promise对象,接着调用Then(s func(err error)),如果当前没有完成promise的解析或拒绝,promise对象会将传入的回调函数保存在一个回调函数数组中,等待完成promise之后再执行回调函数。
总的来说,对kafka生产消息的这一过程提供了promise机制,可以很方便地监听生产者生产消息的工作是否正常,而具体的生产者并不用关心工作是否正常。这种方式很优雅地体现了关注分离(separation of concerns)的思想。
// 总的来说,golang.org/x/sync/errgroup,结合了WaitGroup和context来对goroutine进行控制,而goka的封装是对goroutine可能返回错误信息进行收集整理。例如,当一个函数A用goka给到的Go()函数进行调用时,会启动一个goroutine来执行函数A,而函数A内部业务逻辑中需要有子函数B也需要以goroutine的形式运行。那么在函数A和函数B最好都有一个形参(这样的场景,默认是第一个形参了)为context,传入了context便可以很好地对goroutine和子goroutine进行状态控制。另外使用到WaitGroup,对父goroutine的抢占行为做出了控制。当某个goroutine中的函数返回错误,错误信息会被保存并且执行context的取消函数,进而终止诸多goroutine(当然诸多这样的goroutine内部需要有类似context.Done()的监听通道来响应取消函数)。
// in golang.org/x/sync/errgroup
type Group struct {
cancel func() // cancel()会在调用WithContext()时,由函数内部的WithCancel()返回的取消函数赋值
wg sync.WaitGroup
errOnce sync.Once
err error
}
func WithContext(ctx context.Context) (*Group, context.Context) {
ctx, cancel := context.WithCancel(ctx)
return &Group{cancel: cancel}, ctx
}
func (g *Group) Go(f func() error) {
g.wg.Add(1)
go func() { // 启动一个goroutine
defer g.wg.Done()
if err := f(); err != nil {
g.errOnce.Do(func() { // 当出现第一次错误,执行一次,与内部即将执行的取消函数(第一次调用context的取消函数之后,对取消函数的后续调用便不会执行任何操作)的特性很好地契合。
g.err = err
if g.cancel != nil {
g.cancel()
}
})
}
}()
}
// in goka
type ErrGroup struct {
*errgroup.Group
err Errors // 该结构对象中有一个error数组和一个锁
}
//
func NewErrGroup(ctx context.Context) (*ErrGroup, context.Context) {
g, ctx := errgroup.WithContext(ctx)
return &ErrGroup{Group: g}, ctx
}
func (g *ErrGroup) Go(f func() error) {
g.Group.Go(func() error {
if err := f(); err != nil {
g.err.Collect(err) // 将错误内容收集到g.err对象的[]error中,可以在Go()函数之后集中获取。
return err
}
return nil
})
}
goka框架比较轻量,可以对流数据进行定制化的过滤和翻译等清洗操作。因为具有较高的可复用性,goka应该可以适应多样的简单的流处理场景。但goka内部并没有对聚合和join有类似于Input、Persist等Edge的实现,具体实现聚合和join需要利用Input这个Edge,而Input其中的回调函数需要开发者自己实现,所以在复杂场景中实现还是比较吃力的。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
