社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
protobuf协议是以一个 .proto 后缀的文件为基础,这个文件描述了存在哪些数据,数据类型是怎么样的。
假设有一个person.proto的文件,使用protoc编译器,编译该文件:
protoc -I=SRC_DIR --cpp_out=DST_DIR person.proto
这里以C++为例,上面cpp表示生成C++文件;protobuf协议还支持Java、Python语言,可以换成相应的类型;
上面SRC_DIR表示的是.proto文件所在的路径,DST_DIR表示的是要生成的文件存放到哪里。
这句执行完,就会在DST_DIR目录生成两个文件,person.pb.h和person.pb.cc文件,
前者存放person类的声明,后者是实现。我们只需要包含person.pb.h就可以使用其中的多种序列化方法了。对于使用这个文件,下面说明protobuf序列化原理时会仔细讲的。当然,实现文件需要使用google一个库,可以自己网上下载,放到/usr/include/目录即可。
上面说了protobuf的message中有很多字段,每个字段的格式为:
修饰符 字段类型 字段名 = 域号;
在序列化时,protobuf按照TLV的格式序列化每一个字段,T即Tag,也叫Key;V是该字段对应的值value;L是Value的长度,如果一个字段是整形,这个L部分会省略。
序列化后的Value是按原样保存到字符串或者文件中,Key按照一定的转换条件保存起来,序列化后的结果就是 KeyValueKeyValue…。Key的序列化格式是按照message中字段后面的域号与字段类型来转换。转换公式如下:
(field_number << 3) | wire_type
上面的field_number就是域号, wire_type与字段的类型有关,
| wire_type | meaning | type |
|---|---|---|
| 0 | Vaint | int32、int64、uint32、uint64、sint32、sint64、bool、enum |
| 1 | 64-bit | fixed、sfixed64、double |
| 2 | Length-delimi | string、bytes、embedded、messages、packed repeated fields |
| 3 | Start group | Groups(deprecated) |
| 4 | End group | Groups(deprecated) |
| 5 | 32-bit | fixed32、sfixed32、float |
As you can see, each field in the message definition has a unique numbered tag. These tags are used to identify your fields in the message binary format, and should not be changed once your message type is in use. Note that tags with values in the range 1 through 15 take one byte to encode. Tags in the range 16 through 2047 take two bytes. So you should reserve the tags 1 through 15 for very frequently occurring message elements. Remember to leave some room for frequently occurring elements that might be added in the future.
上面一段话是来自Google Protobuf Documents,上面有几个信息需要注意的地方:
protobuf协议使用二进制格式表示Key字段;对value而言,不同的类型采用的编码方式也不同,如果是整型,采用二进制表示;如果是字符,会直接原样写入文件或者字符串(即不编码)。由于刚开始接触protobuf协议,我也在学习中,下面我会给出一个例子,对于其他一些类型的编码方式,可以仿照这个例子自己实验一下。
(这个例子主要是讲述Key的编码方式)
上面说过,对于message中的每一个域,都对应一个域号。protobuf规定:
Key编码过后,该字节的第一个比特位表示之后的一个字节是否与当前这个字节有关:
结合公式 (field_number << 3)| wire_type ,如果域号大于等于16,两个字节共16位,去掉移位的3位,去掉两个字节中第一个比特位,
总共16个比特位只有16-5==11个比特位用来表示Key,所以Key的域号要小于2^11== 2048。
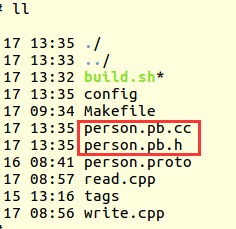
1、创建一个.proto文件,内容如下:
2、使用protoc编译后,生成两个文件:
protoc -I=. –cpp_out=. person.proto
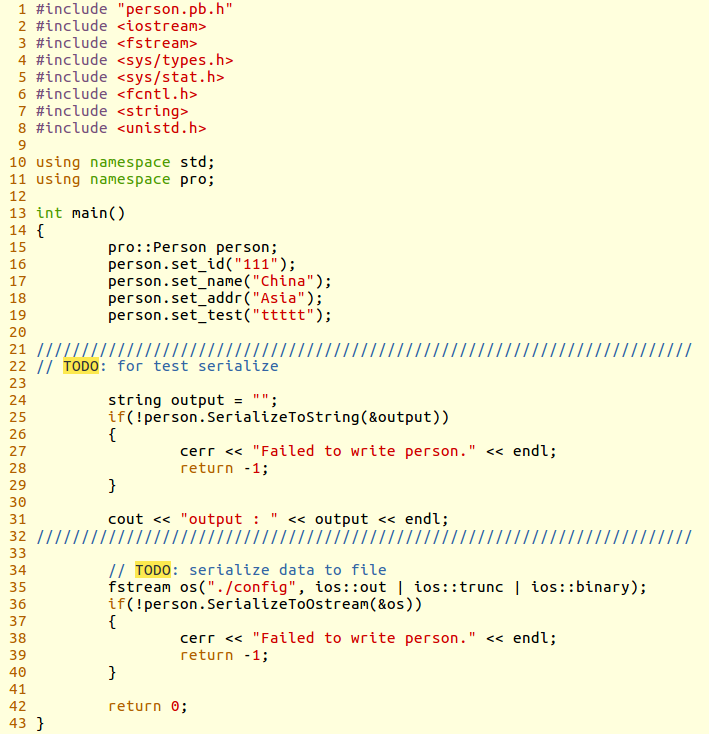
3、写端程序如下:
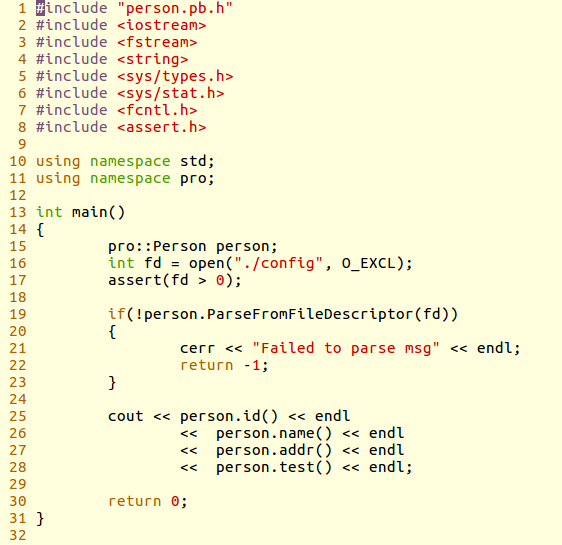
4、读端程序:
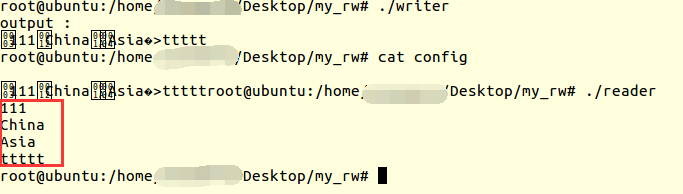
5、首先运行写端程序,把序列化内容写入config文件;再运行读端程序,反序列化文件中的内容,把各个字段的内容打印出来。
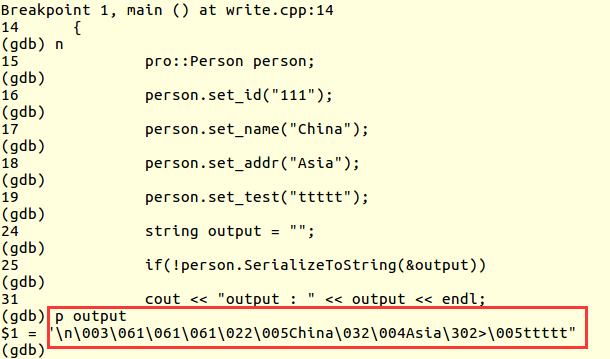
6、调试写端程序,看序列化后的内容是怎么样的:
‘n’是id字段的Key,后面的�03(八进制)表示id字段的值长度为3;
key的域号不超过15的序列化解析:
因为id字段的域号为1,是小于15的,所以id字段的Key序列化要占1个字节的空间,00000001左移3位变成 00001000,因为string的wire_type值是2,所以00001000再或上2,变成00001010,就是十进制的10,即字符’n’。下面的字段如果域号不超过15,解析同id字段。
后面连续3个’61’(八进制)即字符’1’;
同样�22�05是name字段的key和value长度,后面是name字段的值;
�32�04是addr字段的key和value长度;
最后,302>�05是test字段的Key和Value长度;
key的域号大于15的序列化解析:
由于CSDN编辑器不支持CSS格式,没有办法标记下面的解析内容的颜色,只有放一个图片上去了 ^_^;
下面图片中的76就是302后面的‘>’字符的八进制表示,302与>共同组成最后一个字段的Key的表示(因为最后一个字段test的域号1000大于15,所以需要占两个字节表示Key)
以上就是我最近对protobuf的了解,也还在学习中。。。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!