社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
今天分析的是国家统计局网站上的人口信息。
主要内容如下:
1.爬取1949-2019年的总人口数、男性人口、女性人口、城镇人口、乡村人口、人口出生率、人口死亡率、人口自然增长率、0-14岁人口、15-64岁人口、65岁及其以上人口、总抚养比、少儿抚养比、老年抚养比。
2.对爬取数据进行分析。分析内容主要有总人口、男女人口比例、人口城镇化、人口增长率。
3.其中会掺杂一些基本常识的介绍。
首先看一下我们爬取的网站,这是由国家统计局提供的网站,里面包含很多国家公开的数据信息。
在国家数据网站中,有从新中国成立到2018年的人口相关数据。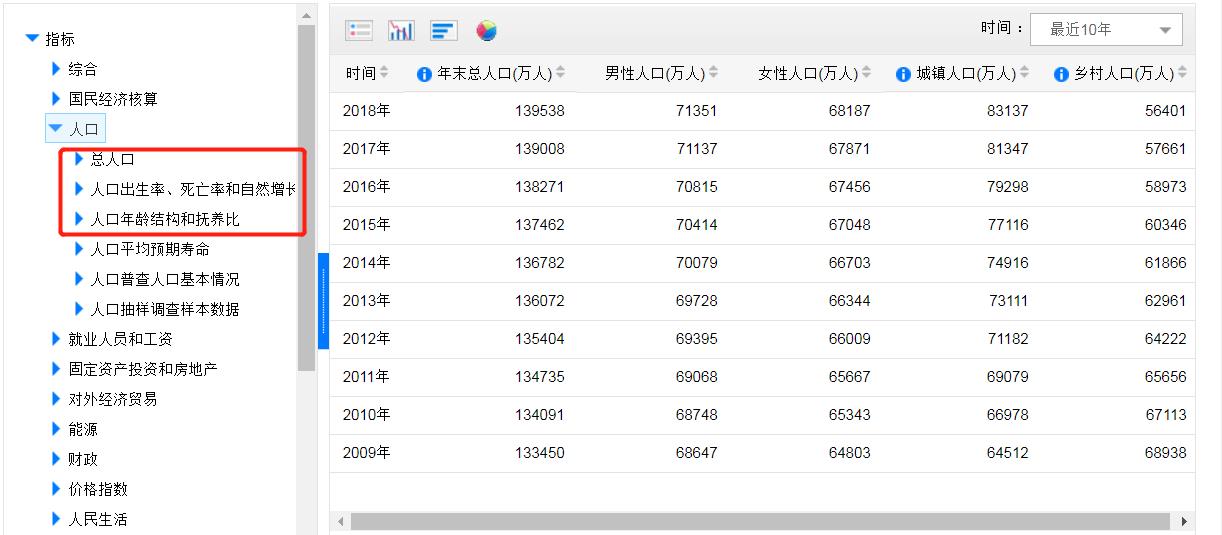
在人口数据中,有三项是我们需要的数据:总人口、增长率、人口结构。
我们按F12查看一下请求的链接,然后复制链接使用requests请求数据。
链接是:http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=%5B%5D&dfwds=%5B%5D&k1=1580908890337&h=1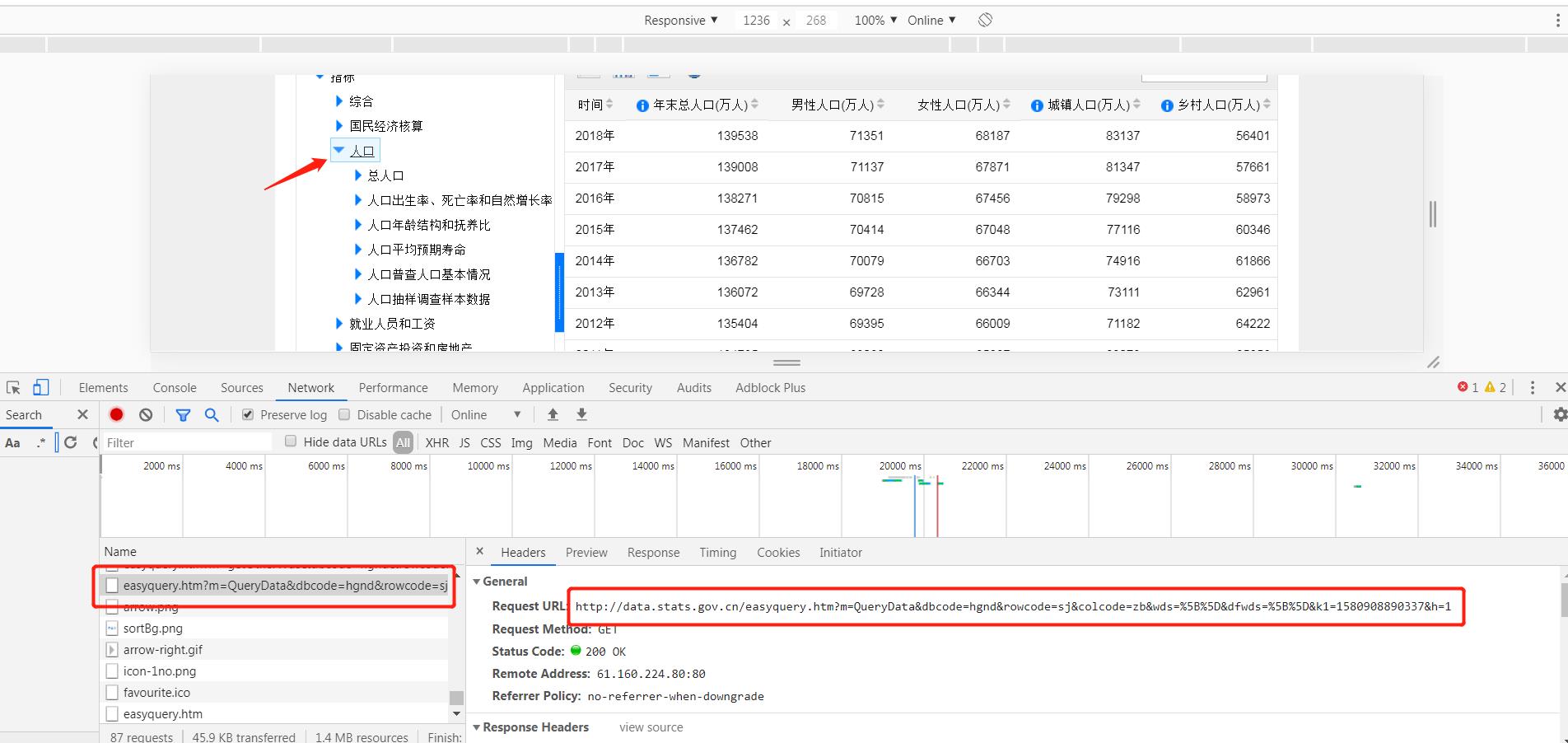
我们使用一个简单的get请求,就把数据获取了,而且返回的直接是json数据!
def spider_population():
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=%5B%5D&dfwds=%5B%5D&k1=1580908890337&h=1'
response = requests.get(url)
print(response.json())
spider_population()

我们此次的目的是抓取从新中国至今的所有人口数据,而页面中最多可以获取近20年的数据,所以我们需要分析网页请求中关于分页的参数。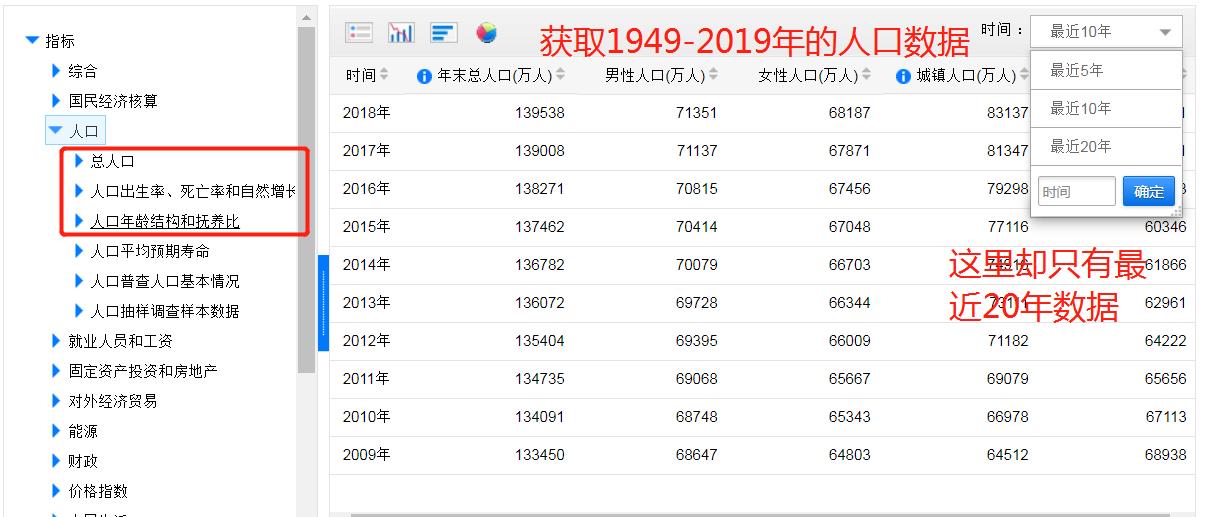 分析请求参数发现主要有两个参数:
分析请求参数发现主要有两个参数:zb、sj,分别表示指标和时间。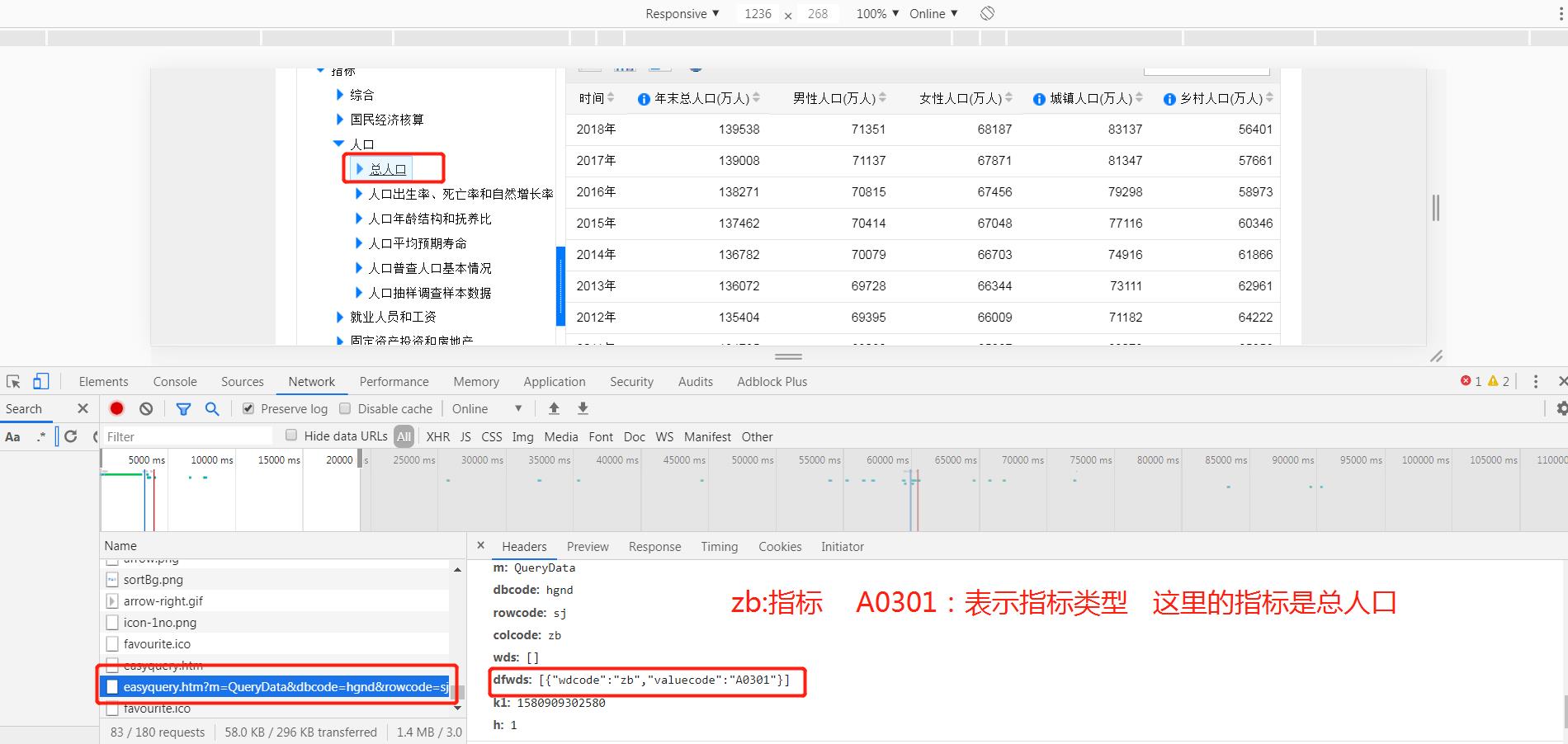
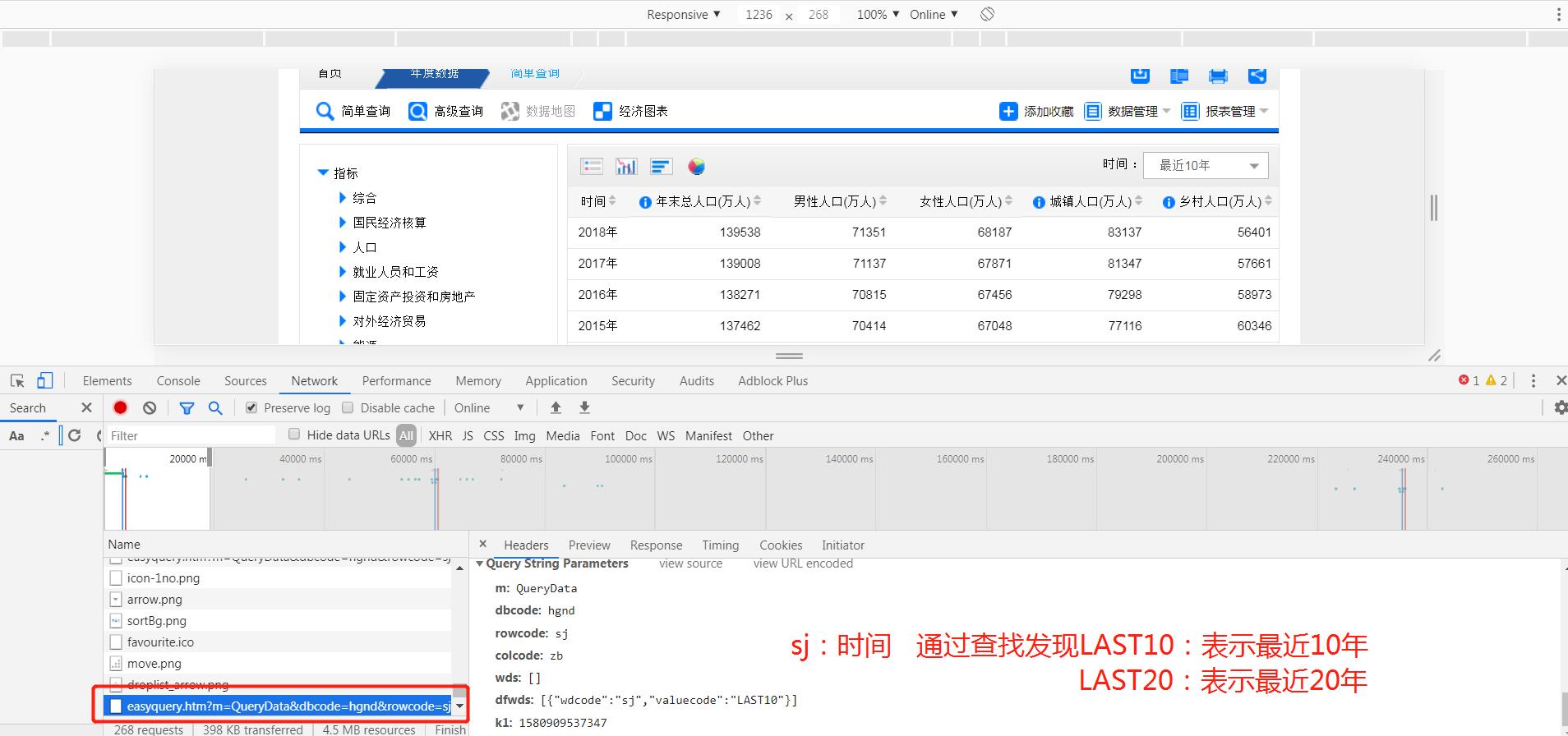
参数:sj=LAST0,表示近10年,于是猜想:sj=LAST70 是不是就可以获取70年的数据呢?
经过代码,发现确实可以找到70年的数据。
def spider_population():
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1))
print(response1.json())
spider_population()

然后我们再将zb参数更换,获取到所有的数据!
def spider_population():
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1))
response2 = requests.get(url.format(dfwds2))
response3 = requests.get(url.format(dfwds3))
spider_population()
获取到数据之后,我们先将数据清洗,提取出我们需要的数据,然后整理保存到Excel中,数据处理方面我们仍然使用pandas。
import pandas as pd
import requests
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = 'population.xlsx'
def spider_population():
"""
爬取人口数据
"""
# 请求参数 sj(时间),zb(指标)
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
# 将所有数据放这里,年份为key,值为各个指标值组成的list
# 因为 2019 年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出
# 数据顺序为历年数据
population_dict = {
'2019': [2019, 140005, 71527, 68478, 84843, 55162, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439,
25.74557483, 18.08384956]}
response1 = requests.get(url.format(dfwds1))
get_population_info(population_dict, response1.json())
response2 = requests.get(url.format(dfwds2))
get_population_info(population_dict, response2.json())
response3 = requests.get(url.format(dfwds3))
get_population_info(population_dict, response3.json())
save_excel(population_dict)
return population_dict
def get_population_info(population_dict, json_obj):
"""
提取人口数量信息
"""
datanodes = json_obj['returndata']['datanodes']
for node in datanodes:
# 获取年份
year = node['code'][-4:]
# 数据数值
data = node['data']['data']
if year in population_dict.keys():
population_dict[year].append(data)
else:
population_dict[year] = [int(year), data]
return population_dict
def save_excel(population_dict):
"""
人口数据生成excel文件
:param population_dict: 人口数据
:return:
"""
# .T 是行列转换
df = pd.DataFrame(population_dict).T[::-1]
df.columns = ['年份', '年末总人口(万人)', '男性人口(万人)', '女性人口(万人)', '城镇人口(万人)', '乡村人口(万人)', '人口出生率(‰)', '人口死亡率(‰)',
'人口自然增长率(‰)', '年末总人口(万人)', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)', '总抚养比(%)',
'少儿抚养比(%)', '老年抚养比(%)']
writer = pd.ExcelWriter(POPULATION_EXCEL_PATH)
# columns参数用于指定生成的excel中列的顺序
df.to_excel(excel_writer=writer, index=False, encoding='utf-8', sheet_name='中国70年人口数据')
writer.save()
writer.close()
if __name__ == '__main__':
result_dict = spider_population()
# print(result_dict)
我们来看看保存的excel文件数据。
数据保存完毕后我们就可以开始数据分析步骤了,一般在我们数据分析之前我们需要有个思路:要分析什么?从哪些角度分析?选择何种可视化图形?得出了什么结论?(当然实际工作时的分析报告需要更为严谨,但大体思路类似。)
首先我们提取Excel中的“年末总人口”这一列的数据进行分析。
import numpy as np
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Line, Bar, Page, Pie
from pyecharts.commons.utils import JsCode
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = './population.xlsx'
# 读取标准数据
DF_STANDARD = pd.read_excel(POPULATION_EXCEL_PATH)
# 自定义pyecharts图形背景颜色js
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
# 自定义pyecharts图像区域颜色js
area_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#eb64fb'}, {offset: 1, color: '#3fbbff0d'}], false)"
)
def analysis_total():
"""
分析总人口
"""
# 1、分析总人口,画人口曲线图
# 1.1 处理数据
x_data = DF_STANDARD['年份']
# 将人口单位转换为亿
y_data = DF_STANDARD['年末总人口(万人)'].map(lambda x: "%.2f" % (x / 10000))
# 1.2 自定义曲线图
line = (
Line(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="总人口",
y_axis=y_data,
is_smooth=True,
is_symbol_show=True,
symbol="circle",
symbol_size=5,
linestyle_opts=opts.LineStyleOpts(color="#fff"),
label_opts=opts.LabelOpts(is_show=False, position="top", color="white"),
itemstyle_opts=opts.ItemStyleOpts(
color="red", border_color="#fff", border_width=1
),
tooltip_opts=opts.TooltipOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1),
# 标出4个关键点的数据
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="新中国成立(1949年)", coord=[0, y_data[0]], value=y_data[0]),
opts.MarkPointItem(name="计划生育(1980年)", coord=[31, y_data[31]], value=y_data[31]),
opts.MarkPointItem(name="放开二胎(2016年)", coord=[67, y_data[67]], value=y_data[67]),
opts.MarkPointItem(name="2019年", coord=[70, y_data[70]], value=y_data[70])
]
),
# markline_opts 可以画直线
# markline_opts=opts.MarkLineOpts(
# data=[[opts.MarkLineItem(coord=[39, y_data[39]]),
# opts.MarkLineItem(coord=[19, y_data[19]])],
# [opts.MarkLineItem(coord=[70, y_data[70]]),
# opts.MarkLineItem(coord=[39, y_data[39]])]],
# linestyle_opts=opts.LineStyleOpts(color="red")
# ),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="新中国70年人口变化(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16),
),
# x轴相关的选项设置
xaxis_opts=opts.AxisOpts(
type_="category",
boundary_gap=False,
axislabel_opts=opts.LabelOpts(margin=30, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(is_show=False),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=25,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# y轴相关选项设置
yaxis_opts=opts.AxisOpts(
type_="value",
position="left",
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# 图例配置项相关设置
legend_opts=opts.LegendOpts(is_show=False),
)
)
# 2、分析计划生育执行前后增长人口
# 2.1 数据处理
total_1949 = DF_STANDARD[DF_STANDARD['年份'] == 1949]['年末总人口(万人)'].values
total_1979 = DF_STANDARD[DF_STANDARD['年份'] == 1979]['年末总人口(万人)'].values
total_2010 = DF_STANDARD[DF_STANDARD['年份'] == 2010]['年末总人口(万人)'].values
increase_1949_1979 = '%.2f' % (int(total_1979 - total_1949) / 10000)
increase_1979_2010 = '%.2f' % (int(total_2010 - total_1979) / 10000)
# 2.2 画柱状图
bar = (
Bar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis([''])
.add_yaxis("前31年:1949-1979", [increase_1949_1979], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.add_yaxis("后31年:1980-2010", [increase_1979_2010], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.set_global_opts(
title_opts=opts.TitleOpts(
title="计划生育执行前31年(1949-1979)与后31年(1980-2010)增加人口总数比较(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16)
),
xaxis_opts=opts.AxisOpts(
# 隐藏x轴的坐标线
axisline_opts=opts.AxisLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
# y轴坐标数值
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
# y 轴 轴线
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
# y轴刻度横线
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 3、渲染图像,将多个图像显示在一个html中
# DraggablePageLayout表示可拖拽
page = Page(layout=Page.DraggablePageLayout)
page.add(line)
page.add(bar)
page.render('population_total.html')
analysis_total()
上面的代码和pyecharts自带曲线有点不同的是:添加了自定义曲线背景色和区域色的功能。
在下图中主要标注了四个点:
1949年:新中国成立,总人口 5.42亿
1980年:计划生育正式开始,总人口 9.87亿
2006年:全面放开二胎,总人口 13.83亿
2019年:总人口 14亿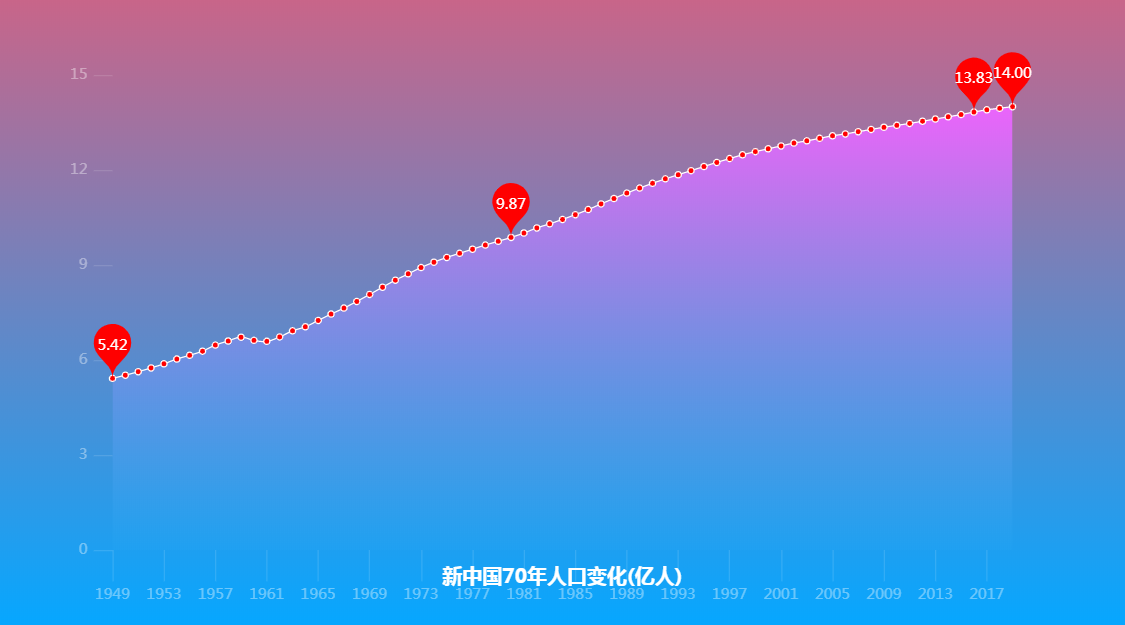
通过观察总人口曲线图得知:
1.人口总体在增加,但增长曲线慢慢放缓,据社科院预测:中国人口将在2029年达到峰值14.42亿,往后逐步下降
2.新中国成立至今(2020年)唯一出现人口减少的是1960和1961年,这两年是我国的自然灾害年。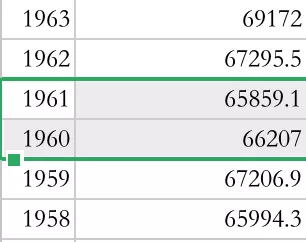
3.根据总人口数,我们再来分析一下 执行计划生育前31年 与 后31年增长的人口分别是多少?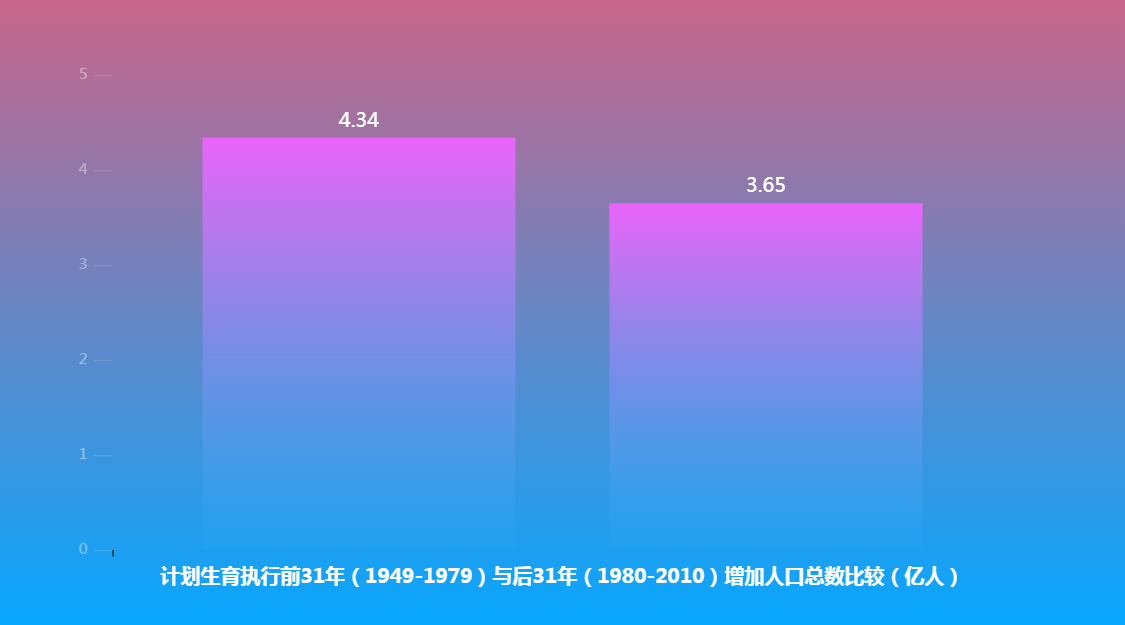
根据上图我们可以看出:计划生育确实控制了人口的增长!
而放开二胎后并未迎来生育高峰期,联合国相关机构发布的《世界人口展望》2017修订版给出了类似的预期。它倾向于认定中国人口已经开始了倒V型反转,在人口到达高峰后,2050年将会保持13亿多,然后就会加速下滑。
我们经常会听到别人说:“中国男女比例失衡,将有3000万中国男性娶不到老婆”。
其实这是我国男女比例失衡造成的结果。
下面就从以下4个角度来分析我国男女比例的关系:
1.2019年男女比
2.男性占总人口比例
3.男女人口数曲线
4.男女人口数差值
def analysis_sex():
"""
分析男女比
"""
# 年份
x_data_year = DF_STANDARD['年份']
# 1、2019年男女比饼图
sex_2019 = DF_STANDARD[DF_STANDARD['年份'] == 2019][['男性人口(万人)', '女性人口(万人)']]
pie = (
Pie()
.add("", [list(z) for z in zip(['男', '女'], np.ravel(sex_2019.values))])
.set_global_opts(title_opts=opts.TitleOpts(title="2019中国男女比", pos_bottom="bottom", pos_left="center"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
# 2、历年男性占总人数比曲线
# (男性数/总数)x 100 ,然后保留两位小数
man_percent = (DF_STANDARD['男性人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100))
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis(
series_name="男性占总人口比",
y_axis=man_percent.values,
# 标出关键点的数据
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max")]),
# 画出平均线
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1949-2019)男性占总人数比", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(type_="value", max_=52, min_=50,
axislabel_opts=opts.LabelOpts(formatter='{value} %')),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 3、男女折线图
# 历年男性人口数
y_data_man = DF_STANDARD['男性人口(万人)']
# 历年女性人口数
y_data_woman = DF_STANDARD['女性人口(万人)']
line2 = (
Line()
.add_xaxis(x_data_year
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_35770067/article/details/104188637
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
