社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬虫需要做如下事情:
1. 模拟对服务端的Request请求;
2. 接收Response 内容并解析、提取所需信息;
简单来说,就是模仿浏览器浏览网页信息。
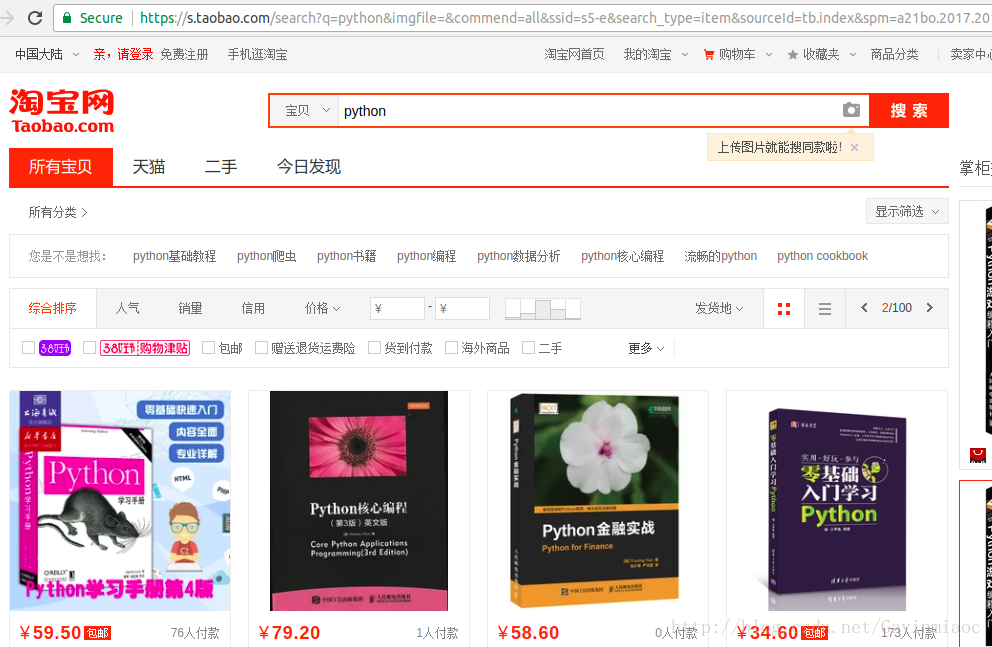
在淘宝首页输入商品数据,搜索出来的商品信息是ajax动态加载出来的,这样的信息再源代码的是找不到,于是爬取这些信息可以选择selenium或者找到这个js文件进行解析,本文这次是抓到这个js文件进行解析的,首先打开淘宝页面,本文以搜索python为例
下面我们来分析爬取的页面结构。利用re正则表达式可以得到想要的结果。
先来看看网页源码。
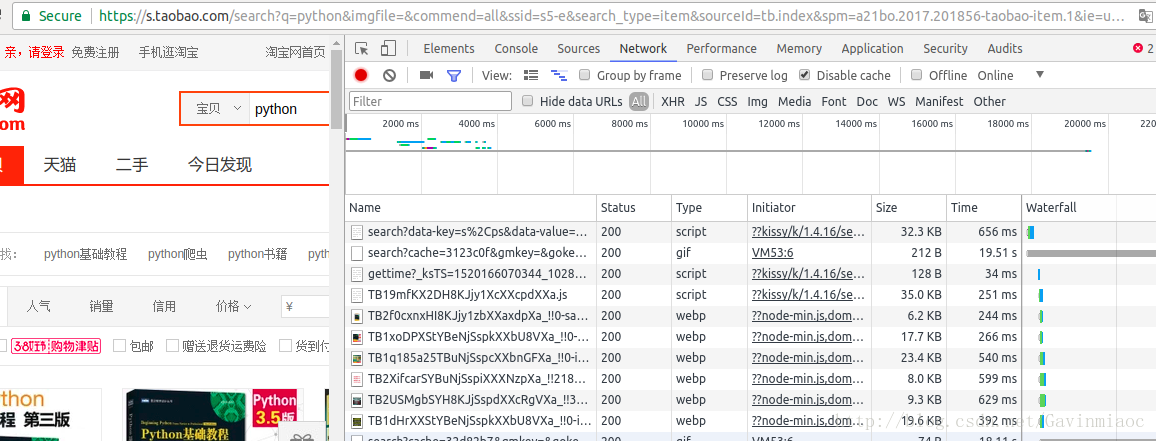
我们使用的是Chrome浏览器,在上述搜索页面中,按F12开发者工具。可以看到如下页面
我们选择搜索页面点击进去,
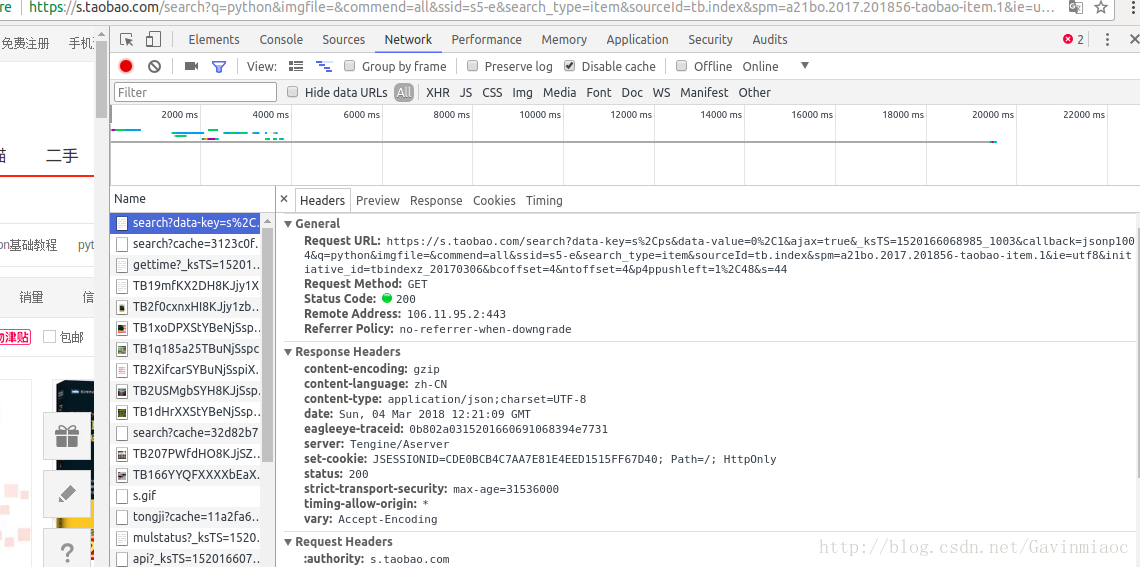
从Headers里面可以看到Request URL地址,可以看到使用的是GET请求。
https://s.taobao.com/search?q=python&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180305&ie=utf8搜索首页面任意输入商品搜索,发现规律,其变化参数如上图Query String Parameters,我们重点关注其中两个:
q:代表输入的搜索词,用来作为查询关键词
initiative_id=staobaoz_20180305 内部参数,带时间戳的显示控制方式
其他的比如
stats_click= 点击方式
ie:显示编码方式
还有常见的
trackid=17 流量来源 17是钻展、1是直通车、2是淘客
isb= 是否商城
shop_type= 店铺类型
base64=1 手机端编码,支持功能手机
sort=排序方式,default是综合排序,renqi-desc是人气排名,sale-desc是销量排名,oldstart是新品排序
loc= 城市
paytype= 支付方式
topSearch=1 搜索显示方式
sid= 请求签名,手机端验证使用
from= 来源位置 spm是具体的点,一个页面什么位置,from是区块
ppath=属性
brand品牌
stats_click= 点击方式
tab=mall 区域 mall是天猫 old是二手 g是全球购
bucketid 内部参数,应该是显示控制方式
基于分析,我们定义一个简单搜索页面url
first_url = "https://s.taobao.com/search?imgfile=&js=1&stats_click=search_radio_all%3A1&ie=utf8"我
我们使用requests.get()用于请求目标网站,类型是一个HTTPresponse类型
使用带参数的GET请求:
先将参数填写在dict中,发起请求时params参数指定为dict
find_arg = {
'q': find_word,
'initiative_id': 'staobaoz_%s%02d%02d' % (t[0], t[1], t[2])
}
# 搜索页面url
# https://s.taobao.com/search?q=python&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180305&ie=utf8
first_url = "https://s.taobao.com/search?imgfile=&js=1&stats_click=search_radio_all%3A1&ie=utf8"
# url = 'https://s.taobao.com/search?q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306'
# 发送请求
response = requests.get(first_url,params=find_arg)
html = response.text接下来就是提取,筛选,清洗数据翻页:
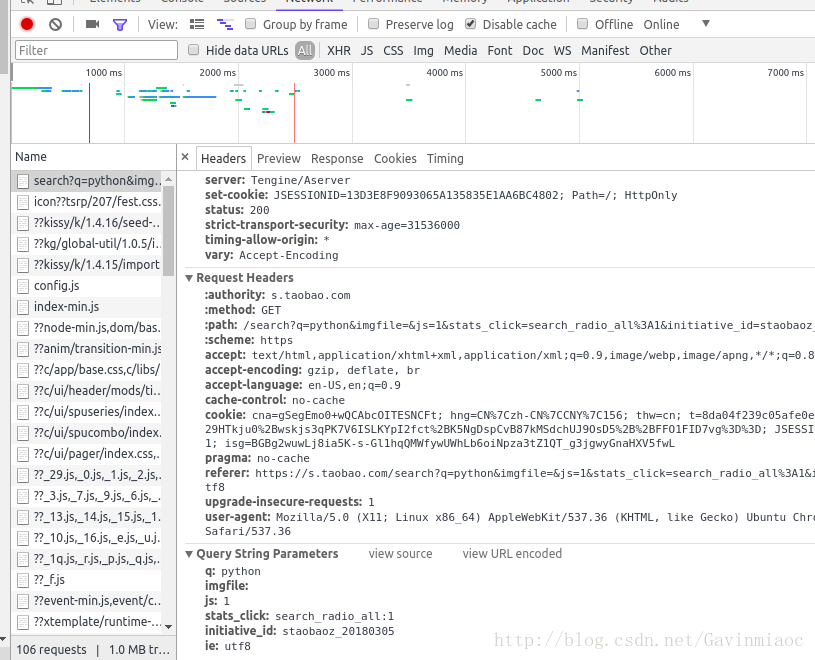
点击商品页面第二页,我们发现JS中多了很多个请求,如图,这里有隐藏着商品信息的js文件。注意,为了便于实时观察,我们可以先将上次的network信息clear(红色圓点旁边那个带斜杠的灰色圆圈)
同样观察Request URL,多试几次发现地址拼接规律。接下来我们就进行模拟请求发送。
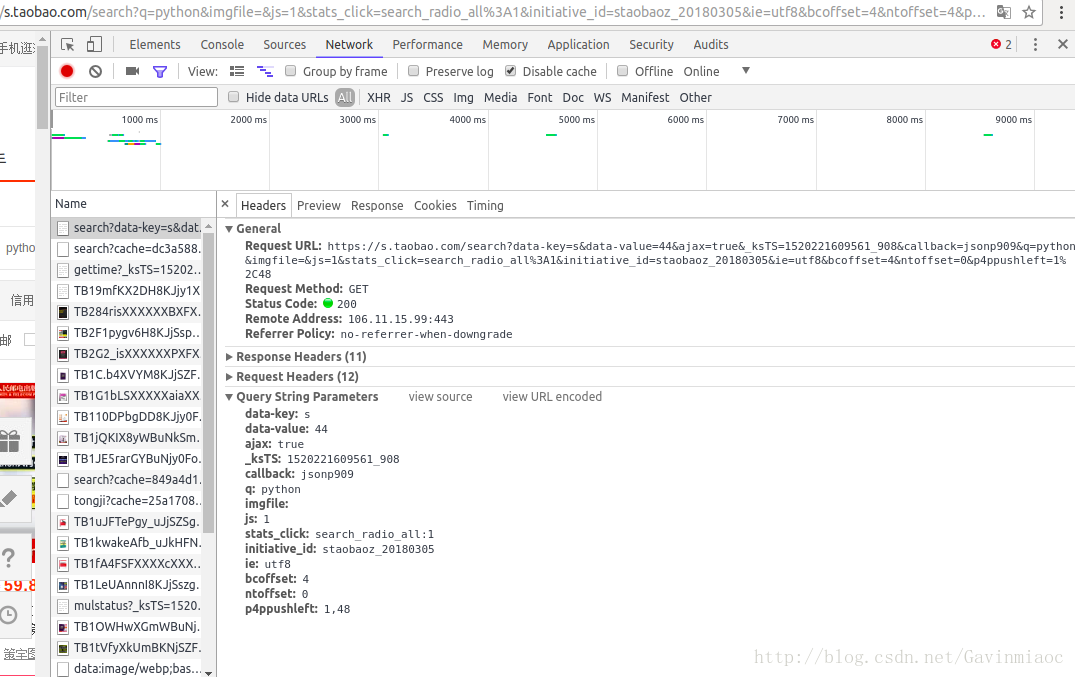
首先找到获得这个文件的链接,如图,
https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksTS=1520221609561_908&callback=jsonp909&q=python&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180305&ie=utf8&bcoffset=4&ntoffset=0&p4ppushleft=1%2C48
参数有:
Query String Parametersdata-key:s
data-value:44
ajax:true
_ksTS:1520221609561_908
callback:jsonp909
q:python
imgfile:
js:1
stats_click:search_radio_all:1
initiative_id:staobaoz_20180305
ie:utf8
bcoffset:4
ntoffset:0
p4ppushleft:1,48其实这个链接很复杂,但是我们可以修改,吧其他东西去掉,剩下这样的
https://s.taobao.com/search?data-key=s&;data-value=44&;ajax=true&;_ksTS=1479917597216_854&;callback&;q={},,于是我们使用这个简化版的url
继续对淘宝的页面进行Inspect,发现每一框的店铺数据储存在g_page_config中的auctions中,并且g_page_config中的数据为json格式。
获取原始数据 (g_page_config以及auctions)
在Python中,可以通过专门的解析器来完成。通过其中的loads 和dumps 可以轻易的在json以及str之间做转换。将str转换为json格式,在通过pandas 的获取json中的数据信息。
每一框店铺的数据涵括非常丰富的店铺信息以及销售信息,我们可以收集宝贝分类(category)、评论数(comment_count)、宝贝位置(item_loc)、店铺名称(nick)、宝贝名称(raw_title)、原价格(reserve_price)、显示价格(view_price)、销量(view_sales)进行分析.
具体分析过程:
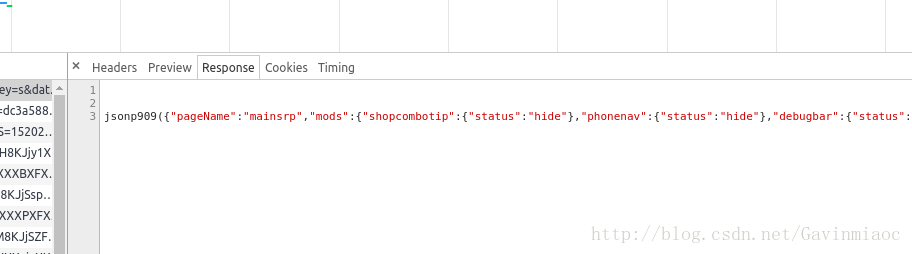
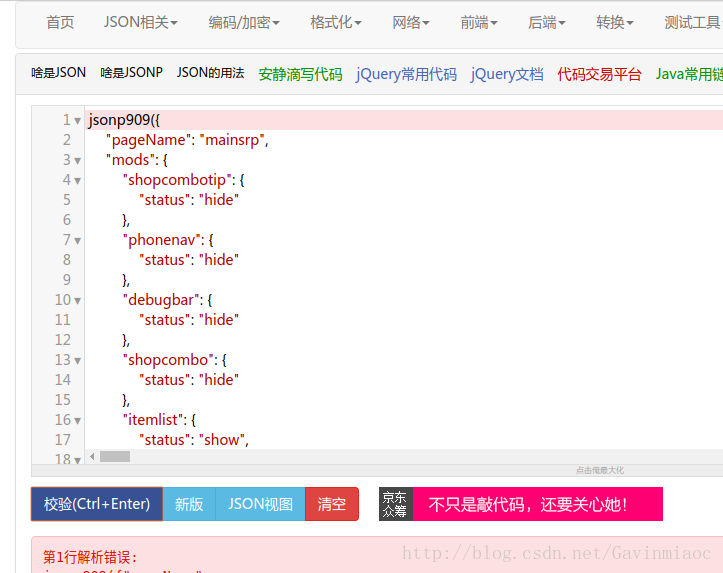
依然在F12页面,我们之前浏览的三Headers信息,现在我们点击Response,可以看到json格式的字符串,为了便于观察分析,我们将其拷贝到在线json解析工具,并转换。
在线转换:
由此一层层的结构关系显而易见。
最终结果展示:
获得数据后我们可以利用画图工具进行饼状图,直方图,折线图等各自图表分析。本文不作详细探讨,后续再聊。
全部代码如下:
# !/usr/bin/python3
# -*- coding:utf-8 -*-
__auther__ = 'gavin'
import requests
import re
import json
import time
from hashlib import md5
import xlwt
# 数据
DATA = []
t = time.localtime()
# 搜索关键字
find_word = 'python'
# 参数
find_arg = {
'q': find_word,
'initiative_id': 'staobaoz_%s%02d%02d' % (t[0], t[1], t[2])
}
# 搜索页面url
# https://s.taobao.com/search?q=python&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180305&ie=utf8
first_url = "https://s.taobao.com/search?imgfile=&js=1&stats_click=search_radio_all%3A1&ie=utf8"
# url = 'https://s.taobao.com/search?q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306'
# 发送请求
response = requests.get(first_url,params=find_arg) #response.json()方法同json.loads(response.text)
html = response.text
# 提取,筛选,清洗数据
content = re.findall(r'g_page_config = (.*?)g_srp_loadCss',html,re.S)[0] # 正则表达式处理的结果是一个列表,取第一个元素(字典)
# 格式化,将json格式的字符串切片
content = content.strip()[:-1]
# 将json转为dict
content = json.loads(content)
# 借助json在线解析分析,取dict里的具体data
data_list = content['mods']['itemlist']['data']['auctions']
# 提取数据
for item in data_list:
temp = {
'title' : item['title'],
'view_price' : item['view_price'],
'view_sales' : item['view_sales'],
'view_fee' : '否' if float(item['view_fee']) else '是' ,
'isTmall' : '是' if item['shopcard']['isTmall'] else '否',
'area' : item['item_loc'],
'name' : item['nick'],
'detail_url' : item['detail_url'],
}
DATA.append(temp)
print(len(DATA)) # 36 首页有12条异步加载的数据 ,应该是48
# 保存一下cookie
cookie_ = response.cookies
# 首页有12条异步加载的数据
# url2 = 'https://s.taobao.com/api?_ksTS=1520072935603_226&callback=jsonp227&ajax=true&m=customized&sourceId=tb.index&q=python&spm=a21bo.2017.201856-taobao-item.1&s=36&imgfile=&initiative_id=tbindexz_20170306&bcoffset=0&commend=all&ie=utf8&rn=e061ba6ab95f8c06a23dbe5bfe9a5d94&ssid=s5-e&search_type=item'
ksts = str(int(time.time() * 1000))
url2 = "https://s.taobao.com/api?_ksTS={}_219&callback=jsonp220&ajax=true&m=customized&stats_click=search_radio_all:1&q=java&s=36&imgfile=&bcoffset=0&js=1&ie=utf8&rn={}".format(
ksts, md5(ksts.encode()).hexdigest())
# 发送请求
response2 = requests.get(url2, params=find_arg, cookies=cookie_)
html2 = response2.text
# print(html2)
data_list = json.loads(re.findall(r'{.*}',html2,re.S)[0])['API.CustomizedApi']['itemlist']['auctions']
# 提取数据
for item in data_list:
temp = {
'title' : item['title'],
'view_price' : item['view_price'],
'view_sales' : item['view_sales'],
'view_fee' : '否' if float(item['view_fee']) else '是' ,
'isTmall' : '是' if item['shopcard']['isTmall'] else '否',
'area' : item['item_loc'],
'name' : item['nick'],
'detail_url' : item['detail_url'],
}
DATA.append(temp)
print(len(DATA)) # +12 首页有12条异步加载的数据
# 翻页
get_args = {}
cookies = response2.cookies #更新一下cookies
for i in range(1,10):
ktsts = time.time()
get_args['_ksTS'] = "%s_%s" % (int(ktsts*1000),str(ktsts)[-3:])
get_args['callback'] = "jsonp%s" % (int(str(ktsts)[-3:]) + 1)
get_args['data-value'] = 44 * i
get_args['q'] = 'python'
#url = 'https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksTS=1520091448743_4613&callback=jsonp4614&q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=4&ntoffset=0&p4ppushleft=1%2C48&s=0'
url = "https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&imgfile=&js=1&stats_click=search_radio_all%3A1&ie=utf8&bcoffset=4&ntoffset=0&p4ppushleft=1%2C48".format(
time.time())
if i > 1:
get_args['s'] = 44*(i-1)
r3 = requests.get(url,params=get_args,cookies = cookies)
html = r3.text
content = re.findall(r'{.*}',html,re.S)[0]
content = json.loads(content)
# print(content['mods']['itemlist']['data']['auctions'])
data_list = content['mods']['itemlist']['data']['auctions']
# 提取数据
for item in data_list:
temp = {
'title': item['title'],
'view_price': item['view_price'],
'view_sales': item['view_sales'],
'view_fee': '否' if float(item['view_fee']) else '是',
'isTmall': '是' if item['shopcard']['isTmall'] else '否',
'area': item['item_loc'],
'name': item['nick'],
'detail_url': item['detail_url'],
}
DATA.append(temp)
cookie_ = r3.cookies
print(len(DATA)) # +12 首页有12条异步加载的数据
# exit(0) # for test 1 times
# 分析
'''
# 画图
data1 = { '包邮':0, '不包邮':0}
data2 = {'天猫':0, '淘宝':0}
# 地区分布
data3 = {}
for item in DATA:
if item['view_fee'] == '否':
data1['不包邮'] += 1
else:
data1['包邮'] += 1
if item['isTmall'] == '是':
data1['天猫'] += 1
else:
data1['淘宝'] += 1
data3[ item['area'].split(' ')[0] ] = data3.get(item['area'].split(' ')[0], )
print(data1)
draw.pie(data1,'是否包邮')
draw.pie(data2,'是否天猫')
draw.bar(data3,'地区分布')
'''
# 持久化
f = xlwt.Workbook(encoding='utf-8')
sheet01 = f.add_sheet(u'sheet1',cell_overwrite_ok=True)
# 写标题
sheet01.write(0,0,'标题')
sheet01.write(0,1,'标价')
sheet01.write(0,2,'购买人数')
sheet01.write(0,3,'是否包邮')
sheet01.write(0,4,'是否天猫')
sheet01.write(0,5,'地区')
sheet01.write(0,6,'店名')
sheet01.write(0,7,'url')
# write data
for i in range(len(DATA)):
sheet01.write(i + 1, 0, DATA[i]['title'])
sheet01.write(i + 1, 1, DATA[i]['view_price'])
sheet01.write(i + 1, 2, DATA[i]['view_sales'])
sheet01.write(i + 1, 3, DATA[i]['view_fee'])
sheet01.write(i + 1, 4, DATA[i]['isTmall'])
sheet01.write(i + 1, 5, DATA[i]['area'])
sheet01.write(i + 1, 6, DATA[i]['name'])
sheet01.write(i + 1, 7, DATA[i]['detail_url'])
f.save(u'搜索%s的结果.xls' % find_word) # 'python'
本文采用的面向过程编程,主要用于学习爬虫,分析数据等。若在实战项目中,可以利用函数式编程或者面向对象风格。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!