社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
首先要查看杰克琼斯一款羽绒服的评论
https://detail.tmall.com/item.htm?spm=a1z10.5-b-s.w4011-14620146553.153.211c5897owzGUF&id=575617865437&rn=951992109b473bd4b71f1783f61d163b&abbucket=4
要找到这款羽绒服的数据都在哪里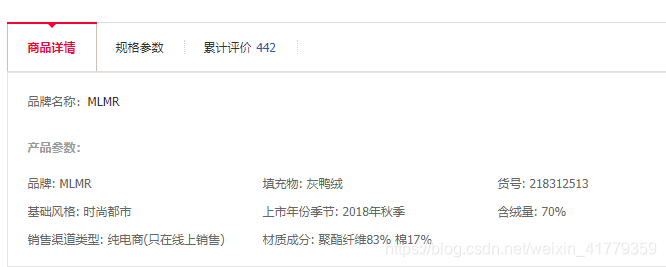
先打开源代码页看看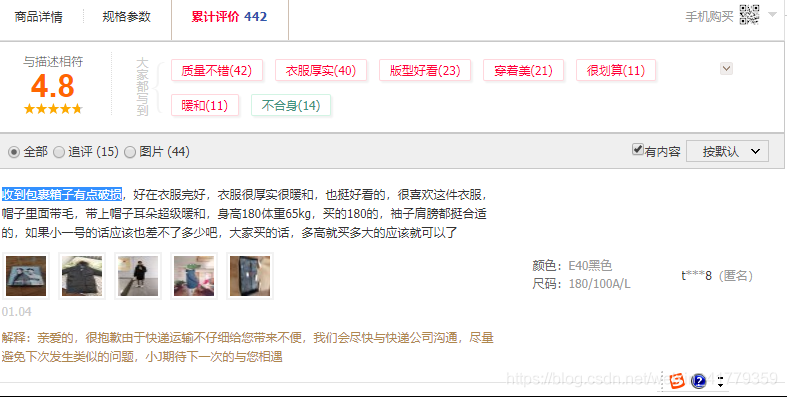

发现源代码页没有任何关于商品评论的信息。
那我们就去检查页找一找。
最后在检查页的json数据里找到
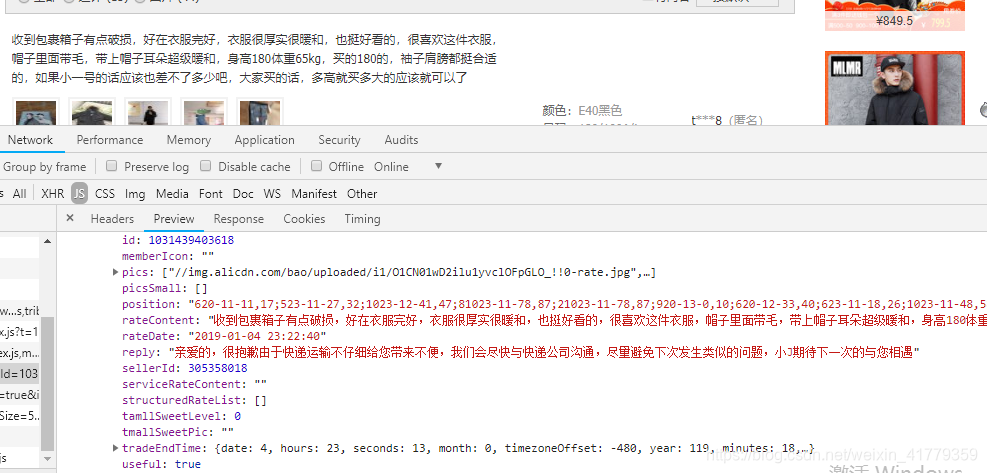
然后就需要向这些数据发送请求了。
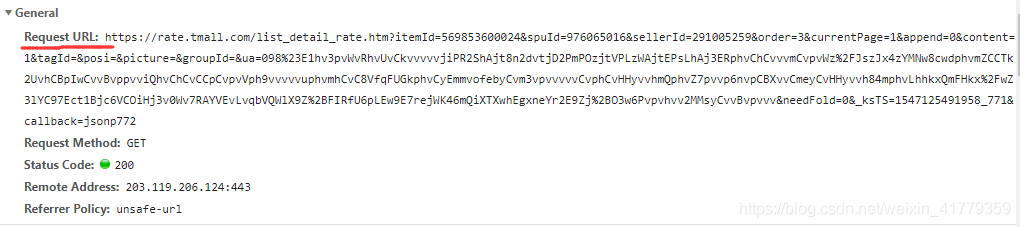

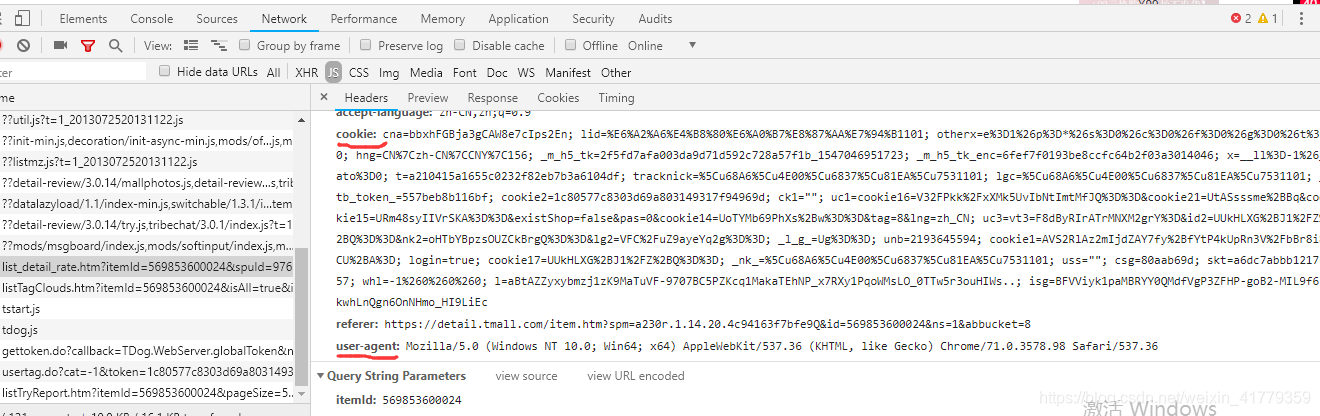
headers={
"cookie": "miid=292998242037415425; t=a210415a1655c0232f82eb7b3a6104df; UM_distinctid=166ceb653b3579-076dd76f89438e-b79183d-100200-166ceb653b4311; cna=bbxhFGBja3gCAW8e7cIps2En; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; tracknick=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; lgc=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; tg=0; ubn=p; ucn=center; enc=UIB9oC%2F4GcT7MT%2BeTYYspmIzgCQGQVgVtIdOafyHPB%2FddpEQuoTVRFhD3T2%2B4ZTQppw07b1yUBPdsBcmiZRl0Q%3D%3D; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; mt=ci=34_1&np=; _m_h5_tk=ab92273cd1f1994a79de75803c72eedd_1542899769491; _m_h5_tk_enc=9af4f2d58367798bd6fd9fc571623a03; v=0; cookie2=1e3e736fa27ece822d8e0584a52fc0e2; _tb_token_=e3e5b95fa56e5; unb=2193645594; sg=142; _l_g_=Ug%3D%3D; skt=6dfe74172437c7ae; cookie1=AVS2RlAz2mIjdZAY7fy%2BfYtP4kUpRn3V%2FbBr8i8CU%2BA%3D; csg=934ced39; uc3=vt3=F8dByR6oLTybe7NAPL0%3D&id2=UUkHLXG%2BJ1%2FZ%2BQ%3D%3D&nk2=oHTbYBpzsOUZCkBrgQ%3D%3D&lg2=VFC%2FuZ9ayeYq2g%3D%3D; existShop=MTU0Mjg5MjM3NQ%3D%3D; _cc_=WqG3DMC9EA%3D%3D; dnk=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; _nk_=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; cookie17=UUkHLXG%2BJ1%2FZ%2BQ%3D%3D; swfstore=183268; uc1=cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&cookie21=W5iHLLyFe3xm&cookie15=UIHiLt3xD8xYTw%3D%3D&existShop=false&pas=0&cookie14=UoTYNOeMOTy2Mw%3D%3D&cart_m=0&tag=8&lng=zh_CN; isg=BJ6eJxdPST-Vf513tvmQfSZu7zQg92O0wyXss0gnR-Hcaz9FsO_g6NBJZxdC01rx",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
def get_page(url):
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
r.encoding='utf-8'
return r.text
except Exception as e:
print(e)

def get_info(page):
try:
items=re.findall(r'"rateContent":"(.*?)"',page,re.S)
for item in items:
yield item
except Exception as e:
print(e)
def save_data(datas):
with open("E:\淘宝评论.txt","a",encoding="utf-8") as f:
for data in datas:
f.write(data)
f.write('n')
f.close()
urls=['https://rate.tmall.com/list_detail_rate.htm?itemId=575617865437&spuId=1038280188&sellerId=305358018&order=3¤tPage={}&append=0&content=1'.format(i) for i in range(1,11)]
for url in urls:
page=get_page(url)
print(url)
datas=get_info(page)
save_data(datas)
所有代码:
import requests
import re
basic_url='https://rate.tmall.com/list_detail_rate.htm?itemId=575617865437&spuId=1038280188&sellerId=305358018&order=3¤tPage={}&append=0&content=1'
headers={
"cookie": "miid=292998242037415425; t=a210415a1655c0232f82eb7b3a6104df; UM_distinctid=166ceb653b3579-076dd76f89438e-b79183d-100200-166ceb653b4311; cna=bbxhFGBja3gCAW8e7cIps2En; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; tracknick=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; lgc=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; tg=0; ubn=p; ucn=center; enc=UIB9oC%2F4GcT7MT%2BeTYYspmIzgCQGQVgVtIdOafyHPB%2FddpEQuoTVRFhD3T2%2B4ZTQppw07b1yUBPdsBcmiZRl0Q%3D%3D; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; mt=ci=34_1&np=; _m_h5_tk=ab92273cd1f1994a79de75803c72eedd_1542899769491; _m_h5_tk_enc=9af4f2d58367798bd6fd9fc571623a03; v=0; cookie2=1e3e736fa27ece822d8e0584a52fc0e2; _tb_token_=e3e5b95fa56e5; unb=2193645594; sg=142; _l_g_=Ug%3D%3D; skt=6dfe74172437c7ae; cookie1=AVS2RlAz2mIjdZAY7fy%2BfYtP4kUpRn3V%2FbBr8i8CU%2BA%3D; csg=934ced39; uc3=vt3=F8dByR6oLTybe7NAPL0%3D&id2=UUkHLXG%2BJ1%2FZ%2BQ%3D%3D&nk2=oHTbYBpzsOUZCkBrgQ%3D%3D&lg2=VFC%2FuZ9ayeYq2g%3D%3D; existShop=MTU0Mjg5MjM3NQ%3D%3D; _cc_=WqG3DMC9EA%3D%3D; dnk=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; _nk_=%5Cu68A6%5Cu4E00%5Cu6837%5Cu81EA%5Cu7531101; cookie17=UUkHLXG%2BJ1%2FZ%2BQ%3D%3D; swfstore=183268; uc1=cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&cookie21=W5iHLLyFe3xm&cookie15=UIHiLt3xD8xYTw%3D%3D&existShop=false&pas=0&cookie14=UoTYNOeMOTy2Mw%3D%3D&cart_m=0&tag=8&lng=zh_CN; isg=BJ6eJxdPST-Vf513tvmQfSZu7zQg92O0wyXss0gnR-Hcaz9FsO_g6NBJZxdC01rx",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
def get_page(url):
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
r.encoding='utf-8'
return r.text
except Exception as e:
print(e)
def get_info(page):
try:
items=re.findall(r'"rateContent":"(.*?)"',page,re.S)
for item in items:
yield item
except Exception as e:
print(e)
def save_data(datas):
with open("E:\爬虫\@爬虫教程\数据\淘宝评论.txt","a",encoding="utf-8") as f:
for data in datas:
f.write(data)
f.write('n')
f.close()
urls=['https://rate.tmall.com/list_detail_rate.htm?itemId=575617865437&spuId=1038280188&sellerId=305358018&order=3¤tPage={}&append=0&content=1'.format(i) for i in range(1,11)]
for url in urls:
page=get_page(url)
print(url)
datas=get_info(page)
save_data(datas)
结果展示: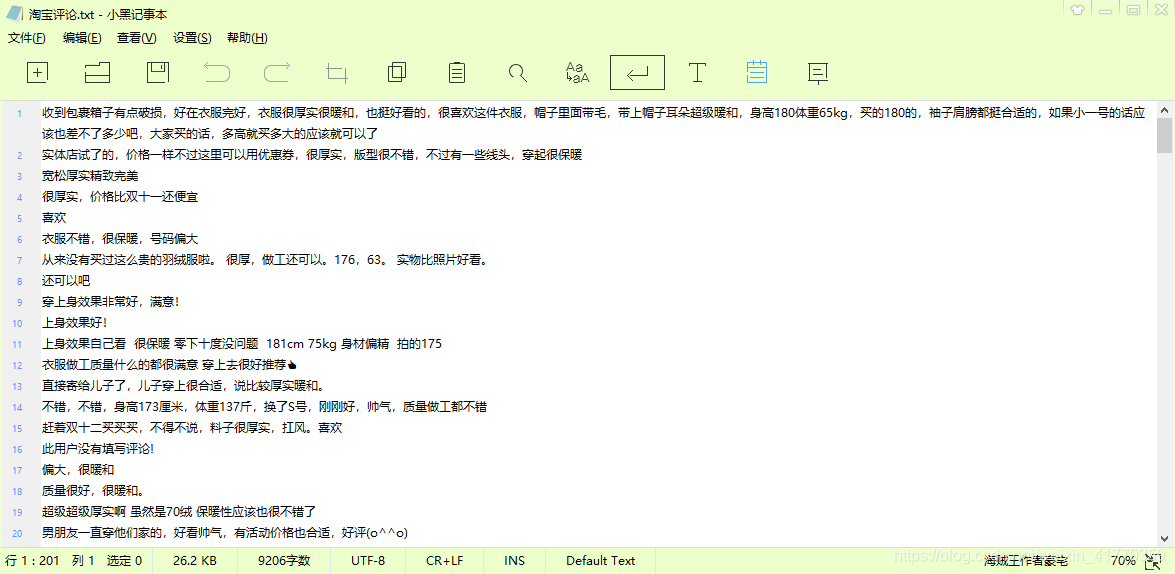
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
