社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
import requests
import re
def getHTMLText(url):
try:
headers =
{
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Cookie':'cna=rMvxE5KEPygCAXyYz3ySaWmo; tracknick=t_1499512875051_0521; tg=0; enc=WKhhjIEw5hx%2FRJKFnn7FwgHiYOazZBxLXrZQxncWTkMGcJ%2FkYbmGPDdtKo0VQ3Pqd9q0t77d6W3kwCKBUcYK4Q%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; miid=973723631245416133; _cc_=U%2BGCWk%2F7og%3D%3D; t=b163eabb82d02ed05c037f22b430e91d; _m_h5_tk=481d0a05dd192d8490270d96237044d0_1580035714907; _m_h5_tk_enc=033a7edcd36664ca087d0a9e2b68acad; thw=cn; cookie2=1e6d43b1fa16858277b7385b64632dba; v=0; _tb_token_=d718679859e7; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5hp3RMAXcOSWZRv%2Bdy3Y1Ffj%2BbBAKFNk3aFpDRhDhnCVve48be9H5AOdMUXXEylXnm0Q49nlGsj3PY1O884fhm6v0VfEVhZ5wI1KNodEvR27oygtLOLX%2BjbWkDju%2FQFwnS5y86YEaoG3LoZjXHpkkovxTYhtWaTDUT7efY1thqtNaIndtMWz12iDviwGLoEbaB3dB3ZAxcvgzFMas6YTWBJdDKDVRVZJeFjYlPDKBW1YzLfObRJHGChPw%3D%3D; l=cBEyVmERvs4cQzXCBOfZCuI8Lu7t4BAX1sPzw4OMZICP_W5FH1Y1WZmFtkLwCnGVLs9W-3Jt3efYB88UHy4Eh2nk8b8CgsDd.; isg=BFFRj2M0605-AwU6Xs8J9i6yYF3rvsUwyvi1KzPgFJjO2mEseQ98Acl4eK48Ul1o; JSESSIONID=3E36719A923A7E4CC75A68F538DC261D'
}
r = requests.get(url,headers = headers,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
# print(r.text)
return r.text
except:
return ""
def parasePage(ilt,html): # 解析网页代码
try:
# "view_price":"559.00" 正则表达式匹配
plt = re.findall(r'"view_price":"[d.]*"',html)
# "raw_title":"双肩包男士大容学生" 正则表达式匹配
tlt = re.findall(r'"raw_title":".*?"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}t{:8}t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count += 1
print(tplt.format(count,g[0],g[1]))
def main():
goods = "书包"
depth = 2 #爬取的页面数量
start_url = " https://s.taobao.com/search?q="+goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
print(url)
parasePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()

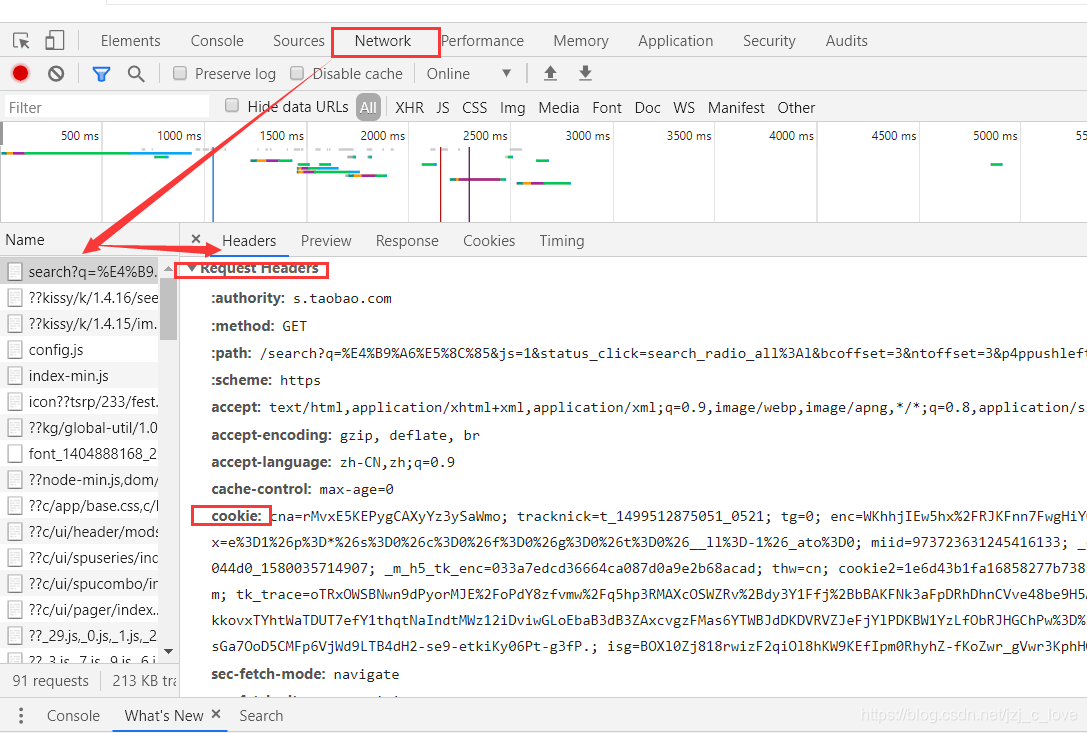
刷新网页,将得到的cookie和headers加入到headers中,具体见getHTMLText中的heades,原因可参考链接。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
