社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
目标网站:https://mm.taobao.com/search_tstar_model.htm?
具体思路:进入页面我们会看见很多图片,其实每张图片对应一个URL,然后点击一张图片我们就会进入到对应主页,主页里面有大量的图片,我们首先就是获取到当前页面的所有url,然后进入每个url获得对应的每个人的所有图片。
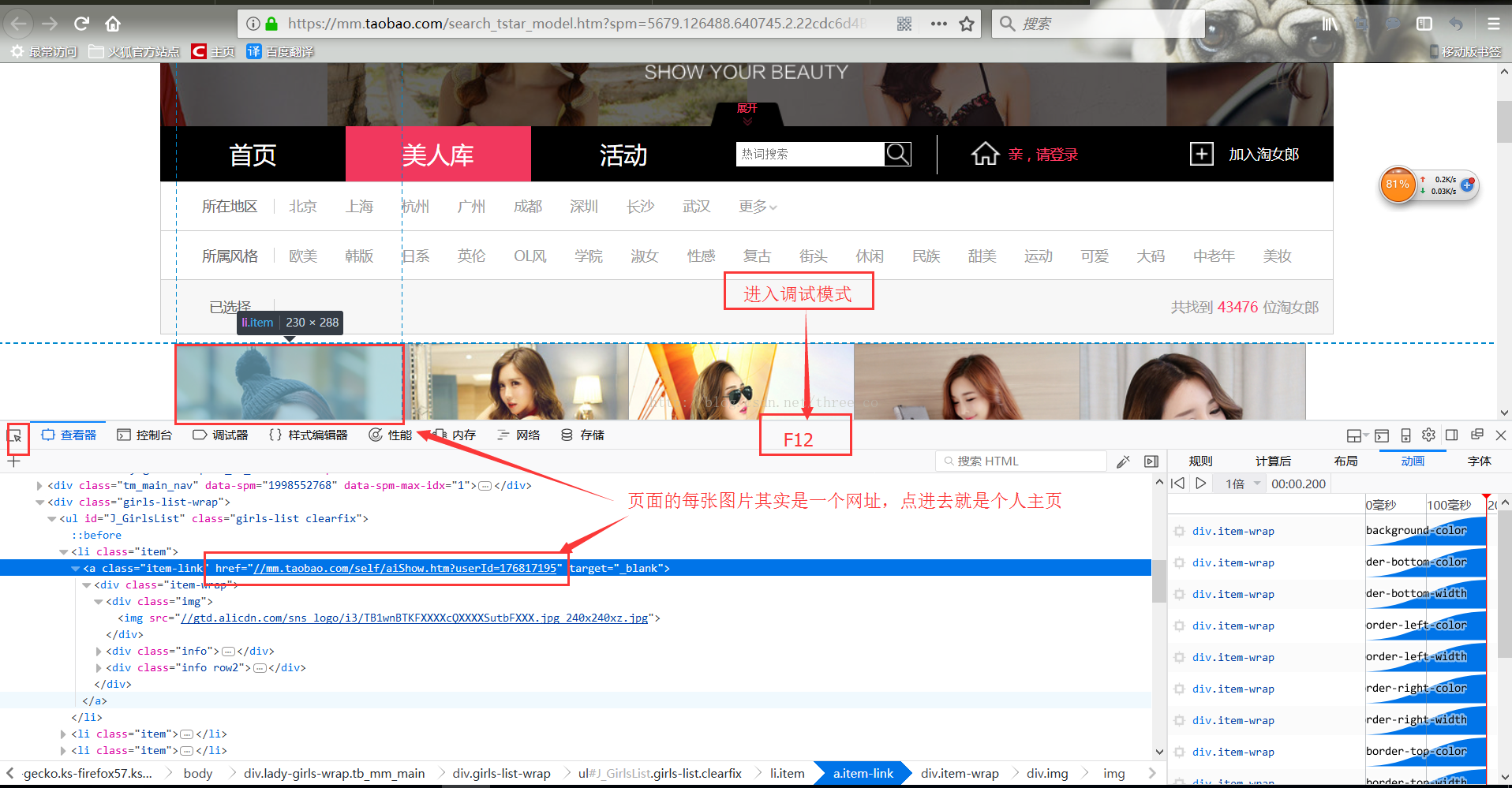
首先我们进入该网页,直接F12进入调试模式,(如果进入不了就右键然后点击审查元素)
然后点击左上角的那一个按钮,从页面中选择一个元素,随后我们选择第一张,然后就可以发现对应的url, 一般来说我们会复制该url,然后查看页面源代码,搜索该url,然后获取该页面所有的类似url,但是很奇怪这里我们去源代码里面搜索发现根本搜索不到该url,源代码里面搜不到但是为什么我审查元素的时候能看到呢,它这里就是一个ajax异步了。
我们需要了解两点:
1、ajax是asynchronous javascript and XML的简写,就是异步的javascript和XML,这一技术能够向服务器请求额外的数据而无须卸载页面,会带来更好的用户体验。
2、ajax技术的核心是XMLHttpRequest对象(简称XHR)。
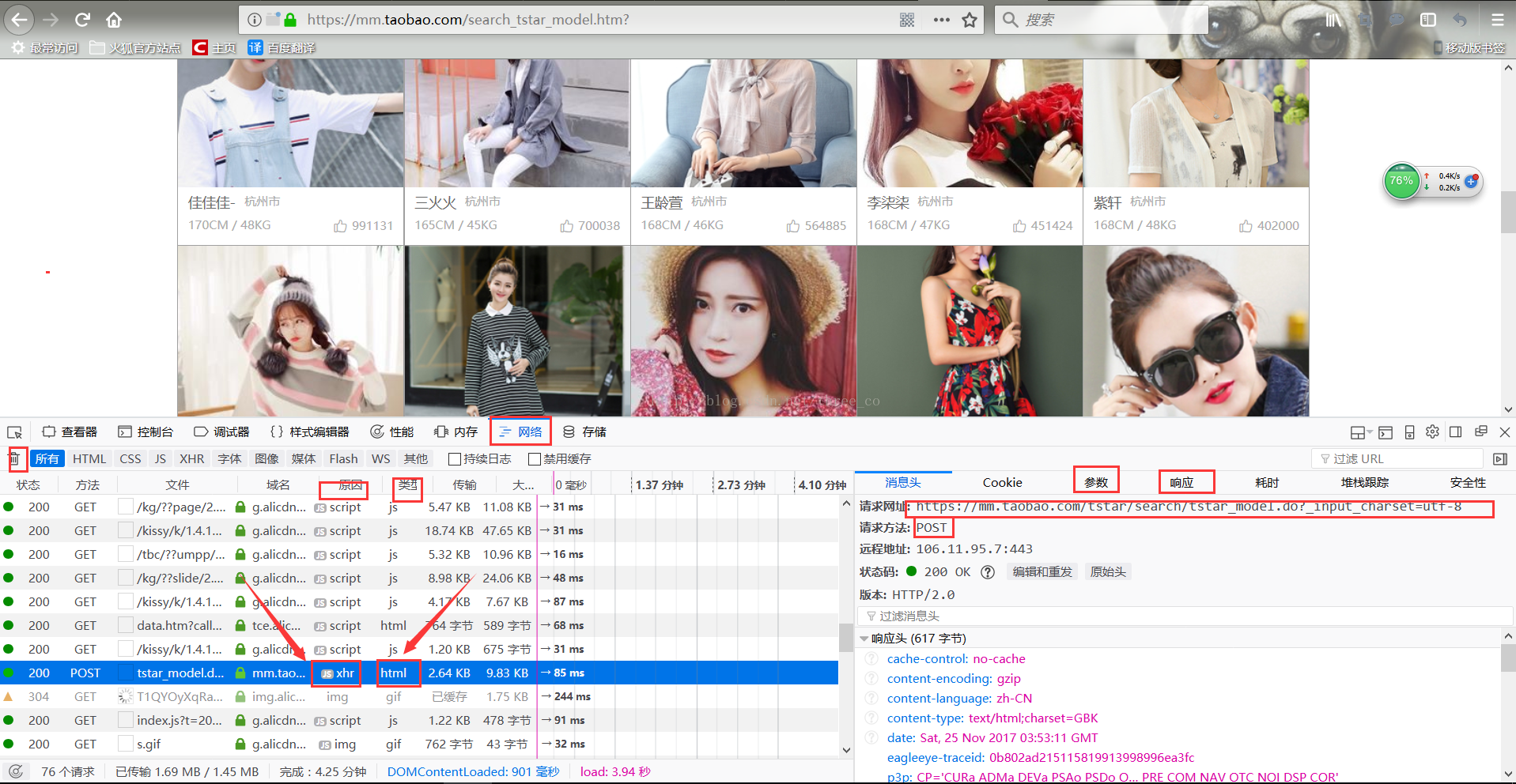
然后我们点击网络那个按钮,然后清空掉页面上的那些传输信息,我们刷新网址,然后我们就会得到暂新的传输信息,我们只需要在这些信息里面找类型是html而原因是xhr的那条信息,如图:
(或许你觉得在这么多传输信息里面去找这么一条xhr信息有点为难,那么我们其实可以简单一点)
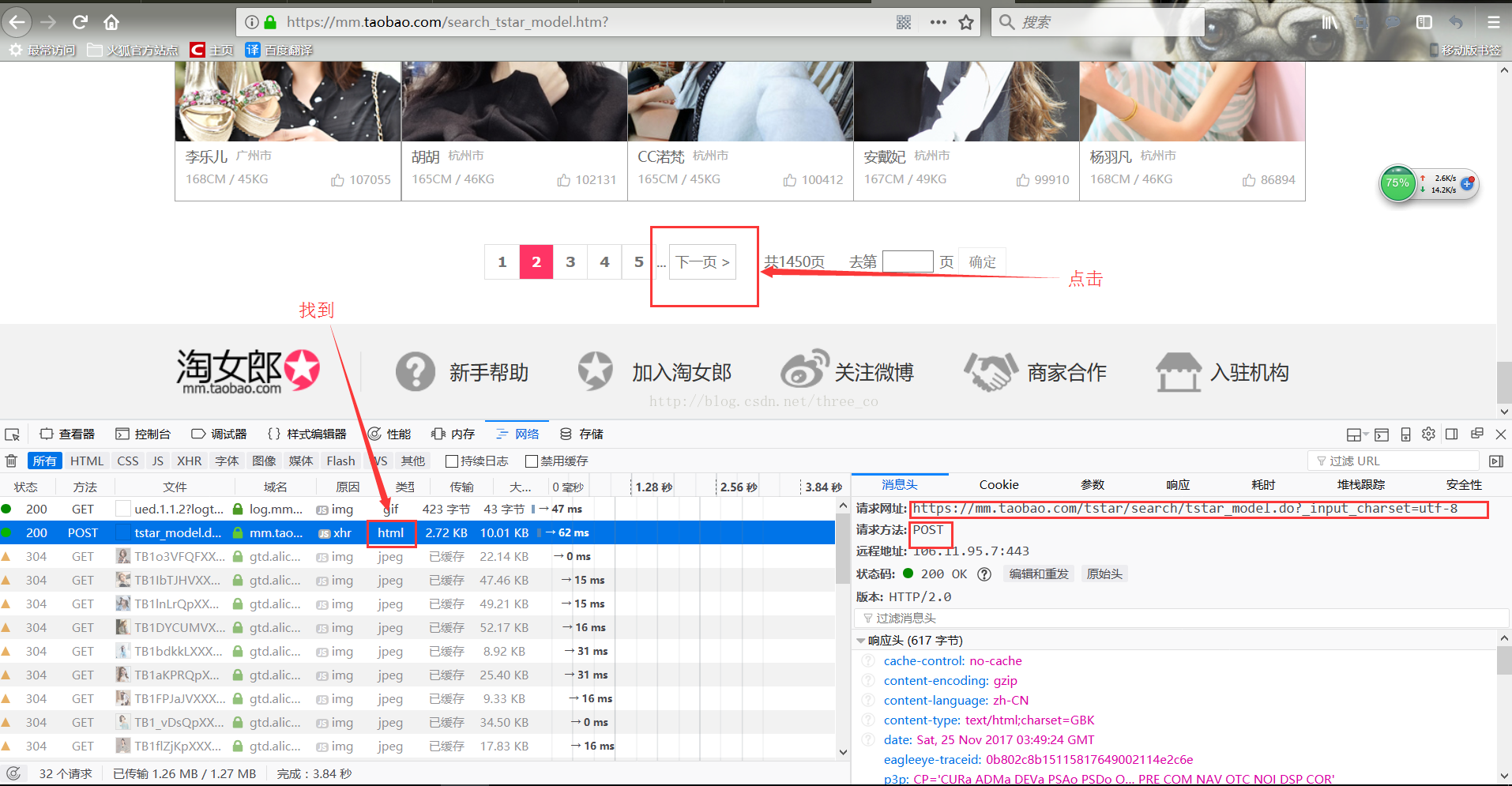
我们下拉页面到最下面会发现有一个下一页的按钮,我们点击下一页,会发现上面的页面没有动,而下面的图片确实更新了,这很显然就是ajax嘛,所以我们清空掉那些传输信息,然后点击下一页然后传输信息就少很多了,找到xhr就很简单了。如下图:
这样我们便找到了我们所需要的,从页面上我们 可以发现是一个post类型的请求,
post类型的请求我们一般只用关注三点:
1、请求的网址
2、请求的类型是post
3、请求的参数
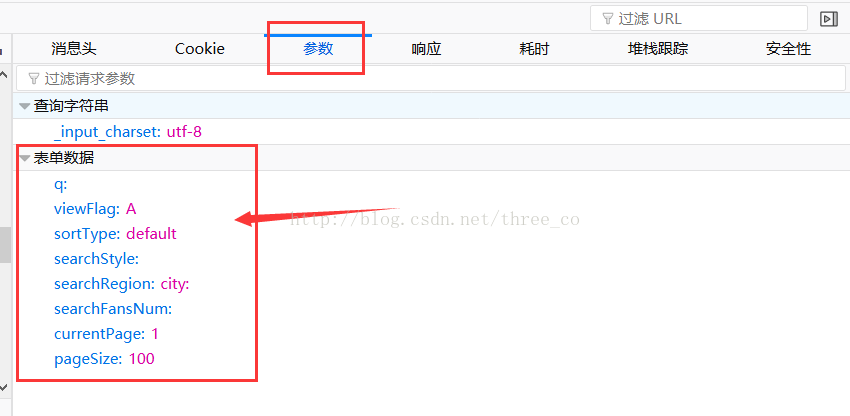
我们点击参数那个按钮,会得到如下图这样一个表单,这就是代码里面那个data数据的由来了。
同时我们多点击几次下一页并查看信息,会发现对于不同的页面,请求的网址是一样的,类型也都是post,变得只是请求参数的里面的那个currentPage后面的那个数字。是第几个页面后面的就是数字几。
所以我们爬取每个页面的所有个人主页的url的时候只需要将参数里面的currentPage改变就可以了。
(具体实现看代码)
然后我们点击响应按钮,看看这个post请求返回的是什么?
我们发现返回的是json类型的数据,我们需要用import json 然后json.loads(...)将json类型转换为原始数据类型即是dict。然后我们可以发现在这个dict里面可以找到对应页面的所有人的个人信息,city、height、weight、realname、等,其中userId非常重要。
看见上面这张图可以明白userId有多重要了吧,我们访问的每一个人的主页的网址都是前面一部分没变,变得只是后面那个userId。
简单来说就是只要拿到了userId我们就能去到每个人的主页,去到每个人的主页后,拿到她们的图片还不是轻而易举?
这里我们像之前操作那样,查看页面元素,然后发现图片的地址,然后接着到页面源代码里面去查找,会发现每个图片的地址都有两条,所以我们对查找出来的那些图片地址的list要进行一个除重(set即可以)
下面来看下代码吧:当然数据库建表的操作没有写出来,代码注释也没有写,所以建议先看之前那篇博客,里面有详细的介绍:http://blog.csdn.net/three_co/article/details/78575634
看完再来看这个应该能看的差不多。
import requests,json,re,pymysql
class taobaoMMSpider():
def __init__(self):
self.topUrl = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
self.basicUrl = 'https://mm.taobao.com/self/aiShow.htm?userId='
self.count = 0
def getuserInfo(self,page):
data = {
'q':'',
'viewFlag':'A',
'sortType':'default',
'searchStyle':'',
'searchRegion':'city:',
'searchFansNum':'',
'currentPage':'%d'%page,
'pageSize':'100',
}
res = requests.post(self.topUrl,data = data)
html = res.text
userInfoList = json.loads(html)['data']['searchDOList']
for userInfo in userInfoList:
name = userInfo['realName']
city = userInfo['city']
height = userInfo['height']
weight = userInfo['weight']
userId = userInfo['userId']
url = self.basicUrl + '%s'%userId
#print(url)
res = requests.get(url)
html = res.text
imageUrlRe = r'(//img.alicdn.com/imgextra/.*?)"'
imageUrlList = list(set(re.findall(imageUrlRe,html)))
#print(imageUrlList)
self.count +=1
print(self.count,'正在爬取%s的信息'%name,'她一共%s张图片'%len(imageUrlList))
for imageUrl in imageUrlList:
self.conndb().execute("insert into image(`name`,`city`,`height`,`weight`,`imageUrl`) values('{}','{}','{}','{}','{}')".format(name,city,height,weight,imageUrl))
self.db.commit()
def conndb(self):
self.db = pymysql.connect(
host = '127.0.0.1',
port = 3306,
user = 'test1',
password = '5531663',
db = 'taobaomm',
charset = 'utf8',
)
cursor = self.db.cursor()
return cursor
spider = taobaoMMSpider()
for page in range(1,167):
spider.getuserInfo(page)
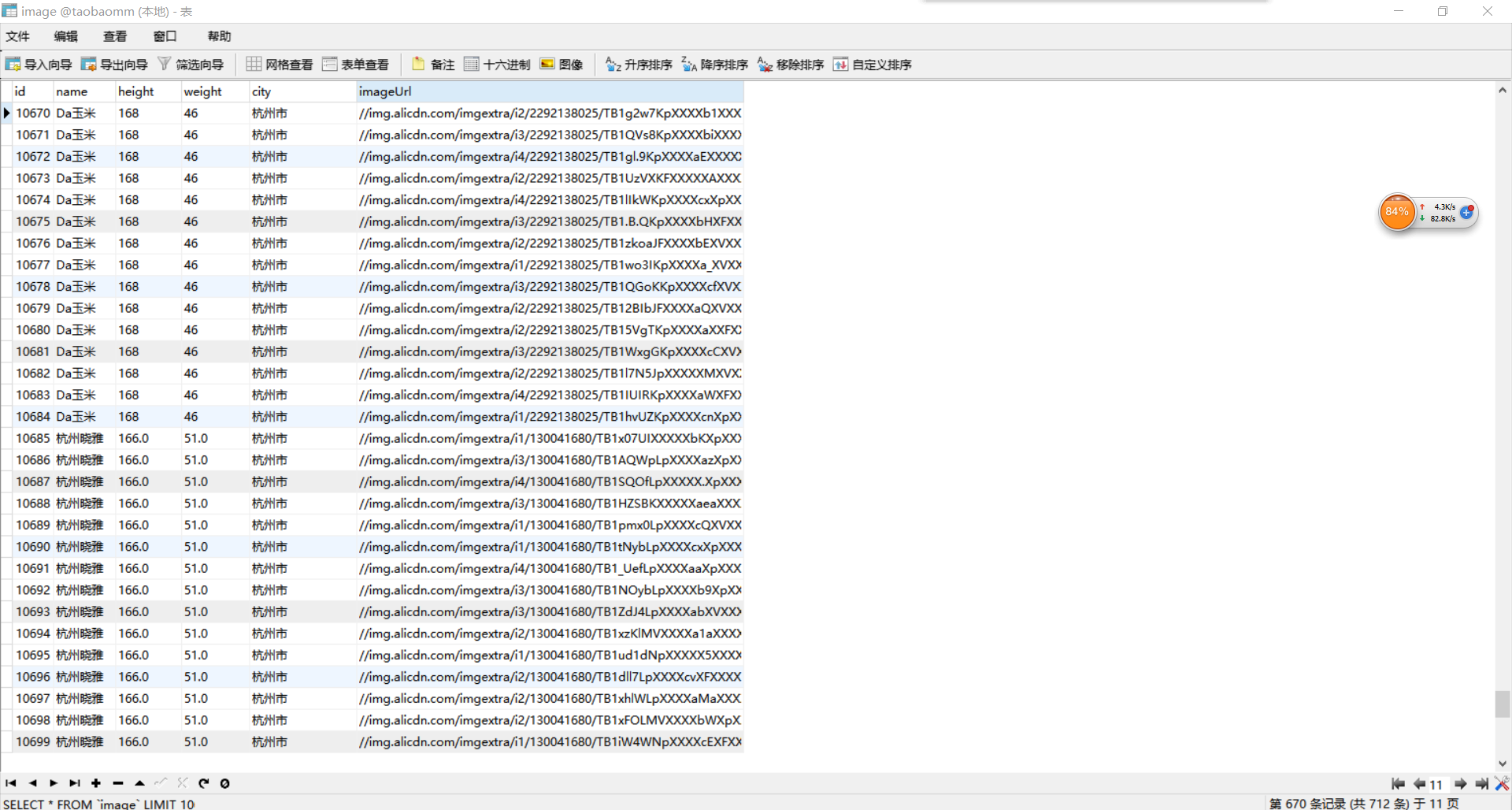
效果图:一会就存进了10000条图片url。
===================================================================================================
以上,如有不足请多指教。Thanks~!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!