社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
风险价值(VaR)是最广泛使用的风险测度之一, 也是饱受争议的测度之一。从业人员喜欢其直观性. 但是许多人对其有限的尾部风险捕捉能力进行广泛的讨论和批评——主要是在理论依据上。从字面上讲, VaR 是一个以货币单位(如 美元、欧元、日元)表示的数字, 表示在给定时间周期中不超过某种置信度(概率)的损失(或者一个投资组合、股票头寸等)。
考虑一个当日价值为100万美元的股票头寸, 在30天( 1个月)内、 置信度为99%的情况下 VaR 为 5 万美元。 这个 VaR 数字说明, 30天内损失不超过 5 万美元的概率为99% ( 100 个案例中有 99 个)。但是, 它并不说明一旦损失超过 5万美元, 损失的规模会达到什么程度——也就是如果最大损失为10万或者50万美元时, 这种特定的“高于 VaR 的损失” 概率有多大。它所说明的只是,发生 5万美元或者更大损失的概率为 1%。我们再次假定使 Black-Scholes-Merton 设置,考虑如下的参数化和未来日期 T=30/365(即假定 30 天的一段时期)指数水平的模拟:
import numpy as np
import numpy.random as random
import matplotlib.pyplot as plt
S0 = 100
r = 0.05
sigma = 0.25
T = 30 / 365.
I = 10000
ST = S0 * np.exp((r - 0.5 * sigma ** 2) * T + sigma * np.sqrt(T) * random.standard_normal(I))
为了估算VaR数字,需要模拟的绝对利润和相对于近日持仓价值的亏损,并加以排序,即从最严重的亏损到最大的利润:
R_gbm = np.sort(ST - S0)
下图展示了模拟绝对绩效的直方图:
plt.hist(R_gbm, bins=50)
plt.xlabel('absolute return')
plt.ylabel('frequency')
plt.grid(True)

有了包含排序结果的ndarray对象,scoreatpercentile函数已经取得了成功。我们所需要做的就是定义感兴趣的百分比(以百分数表示),在列表对象percs中,0.1转换为置信度100%-0.1%=99.9%。在本例中,置信度为99.9%的30日VaR为20.2货币单位, 而89%置信度下为8.9个货币单位
import scipy.stats as scs
percs = [0.01, 0.1, 1., 2.5, 5., 10.]
var = scs.scoreatpercentile(R_gbm, percs)
print("%16s %16s" % ('Confidence Level', 'Value-at-Risk'))
print(33 * '-')
for pair in zip(percs, var):
print("%16.2f %16.3f" % (100 - pair[0], -pair[1]))
Confidence Level Value-at-Risk
---------------------------------
99.99 23.229
99.90 19.679
99.00 14.877
97.50 12.792
95.00 10.913
90.00 8.509
作为第2个例子,回忆一下Merton的跳跃扩散,我们打算动态模拟:
# Meron的跳跃扩散 动态模拟
lamb = 0.75
mu = -0.6
delta = 0.25
M = 50
dt = 30. / 365 / M
rj = lamb * (np.exp(mu + 0.5 * delta ** 2) - 1)
S = np.zeros((M + 1, I))
S[0] = S0
# 为了模拟跳跃扩散,需要生成3组(独立)随机数:
sn1 = random.standard_normal((M + 1, I))
sn2 = random.standard_normal((M + 1, I))
poi = random.poisson(lamb * dt, (M + 1, I))
for t in range(1, M + 1, 1):
S[t] = S[t - 1] * (np.exp((r - rj - 0.5 * sigma ** 2) * dt
+ sigma * np.sqrt(dt) * sn1[t])
+ (np.exp(mu + delta * sn2[t]) - 1)
* poi[t])
S[t] = np.maximum(S[t], 0)
R_jd = np.sort(S[-1] - S0)
在这个例子中,利用均值为负数的跳跃成分,我们可以看到下图中类似二项分布的模拟利润/亏损。从正态分布的角度来看,在左侧有明显的“大尾巴”:
plt.hist(R_jd, bins=50)
plt.xlabel('value')
plt.ylabel('frequency')
plt.grid(True)
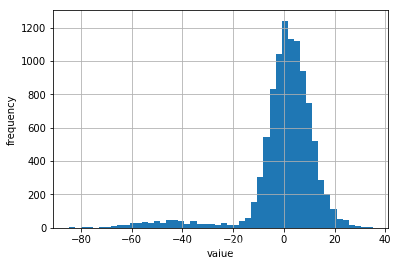
对于这种过程和参数化,置信度 90%的 30日VaR 相差很少,但是在 99.9%置信度下与几何布朗运动相比高出 3 倍多( 79.703对22.079 货币单位)。
percs = [0.01, 0.1, 1., 2.5, 5., 10.]
var = scs.scoreatpercentile(R_jd, percs)
print("%16s %16s" % ('Confidence Level', 'Value-at-Risk'))
print(33 * '-')
for pair in zip(percs, var):
print("%16.2f %16.3f" % (100 - pair[0], -pair[1]))
Confidence Level Value-at-Risk
---------------------------------
99.99 84.378
99.90 72.652
99.00 57.598
97.50 46.390
95.00 28.664
90.00 9.067
这说明标准VaR测度在捕捉金融市场经常遇到的尾部风险方面的问题。
为了进一步说明这一点,我们最好以图形方式展示两种情况的VaR测度以便比较。如下图所示,在典型置信度范围内的VaR测度表现完全不同:
# 几何布朗运动和跳跃扩散的风险价值
percs = list(np.arange(0.0, 10.1, 0.1))
gbm_var = scs.scoreatpercentile(R_gbm, percs)
jd_var = scs.scoreatpercentile(R_jd, percs)
plt.plot(percs, gbm_var, 'b', lw=1.5, label='GBM')
plt.plot(percs, jd_var, 'r', lw=1.5, label='JD')
plt.legend(loc=4)
plt.xlabel('100 - confidence level [%]')
plt.ylabel('value-at-risk')
plt.grid(True)
plt.ylim(ymax=0.0)
(-88.7173879493488, 0.0)
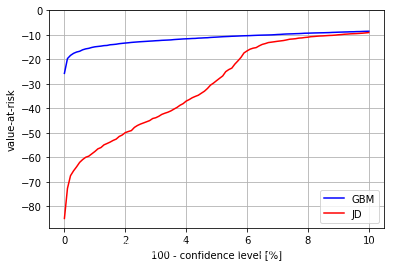
几何布朗运动和跳跃扩散的风险价值
其他重要的风险测度是信用风险价值(CVaR)和从CVaR中派生而来的信用价值调整(CVA)。粗略地讲, CVaR 是对手方可能无法履行其义务所引发风险(例如, 对手方破产)的一个测度。在这种情况下, 有两个主要的假设:违约概率 和 (平均)损失水平。
举个具体的例子, 我们再次考虑Black-Scholes-Merton 的基准设置,使用如下参数:
S0 = 100.
r = 0.05
sigma = 0.2
T = 1.
I = 100000
ST = S0 * np.exp((r - 0.5 * sigma ** 2) * T + sigma * np.sqrt(T) * random.standard_normal(I))
在最简单的情况下,人们可以考虑固定(平均)损失水平L和对手方违约(每年)概率P:
# 固定(平均)损失水平
L = 0.5
# 对手方违约(每年)概率
p = 0.01
使用泊松分布,违约的方案可以用如下代码生成, 考虑了违约只能发生一次的事实:
D = random.poisson(p * T, I)
D = np.where(D > 1, 1, D)
如果没有违约,未来指数水平的风险中立价值应该等于资产当日现值(取决于数值误差造成的差异):
np.exp(-r * T) * 1 / I * np.sum(ST)
100.02947673916002
在我们假定的条件下,CVaR可以这样计算:
CVaR = np.exp(-r * T) * 1 / I * np.sum(L * D * ST)
CVaR
0.47893908348836345
类似地,经过信用风险调整之后的资产现值可以这样计算:
S0_CVA = np.exp(-r * T) * 1 / I * np.sum((1 - L * D) * ST)
S0_CVA
99.55053765567163
这应该(大约)等于CVaR价值减去当前资产价值:
S0_adj = S0 - CVaR
S0_adj
99.52106091651163
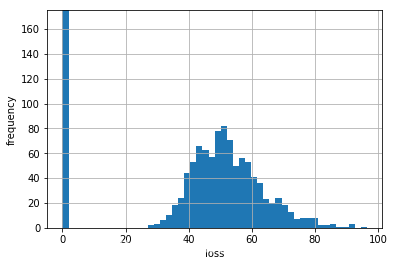
在这个特殊的模拟示例中,我们观察到关于由于信用风险引起的大约1000次亏损,这是假定违约概率为1%、10万次模拟下预期的结果:
np.count_nonzero(L * D * ST)
955
下图展示了由于违约引起亏损的完整频率分布。当然,在大部分情况下(10万例中99000例),没有发现亏损:
plt.hist(L * D * ST, bins=50)
plt.xlabel('loss')
plt.ylabel('frequency')
plt.grid(True)
plt.ylim(ymax=175)
######由于风险中立预期违约引起的亏损(股票)#########
(0.0, 175)
现在考虑欧式看涨期权的情况。它在行权价100时的价值大约为10.4个货币单位:
K = 100 # 行权价100
hT = np.maximum(ST - K, 0)
C0 = np.exp(-r * T) * 1 / I * np.sum(hT)
C0
10.460723606533472
在相同的违约概率和损失水平假设下,CVaR大约为5分:
CVaR = np.exp(-r * T) * 1 / I * np.sum(L * D * hT)
CVaR
0.051251816444561775
相应的,调整后的期权价值大约低了5分:
C0_CVA = np.exp(-r * T) * 1 / I * np.sum((1 - L * D) * hT)
C0_CVA
10.409471790088908
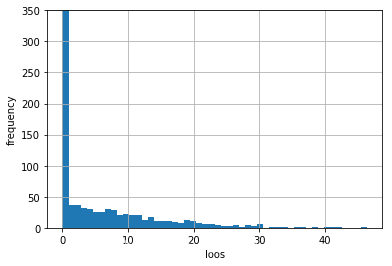
和常规资产相比,期权有不同的特性。我们只看到略低于500次因违约引起的亏损,但是仍然有大约1000次违约。这一结果源于这样的事实:期权到期日时的收益为0的概率很大:
np.count_nonzero(L * D * hT) # number of losses
537
np.count_nonzero(D) # number of defaults
955
I - np.count_nonzero(hT) # zero payoff
44000
下图说明,期权的CVaR和常规资产相比有着完全不同的频率分布:
plt.hist(L * D * hT, bins=50)
plt.xlabel('loos')
plt.ylabel('frequency')
plt.grid(True)
plt.ylim(ymax=350)
#######由于风险中立预期违约引起的亏损(看涨期权)########
(0.0, 350)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
