社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
接上一篇,需要把爬下来的csv格式股票数据存入到mysql数据库中:
这里介绍两种方法:
mysql安装看这里:https://blog.csdn.net/tonydz0523/article/details/82501177
安装 pip install pymysql
还需要使用pandas pip install pandas
首先,与mysql建立连接
import pymysql
# 参数设置 DictCursor使输出为字典模式 连接到本地用户ffzs 密码为666
config = dict(host='localhost', user='ffzs', password='666',
cursorclass=pymysql.cursors.DictCursor
)
# 建立连接
conn = pymysql.Connect(**config)
# 自动确认commit True
conn.autocommit(1)
# 设置光标
cursor = conn.cursor()
使用pandas读取csv文件。需要数据测试的可以去网易财经随便下一个:http://quotes.money.163.com/trade/lsjysj_600508.html#01b07
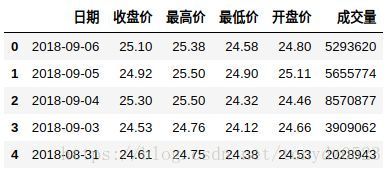
我们先来看看数据是什么样的:
参数有点多,我只需要日期,收盘价,最高价,最低价,开盘价和成交量,其他数据都不要
import pandas as pd
# pandas读取文件 这里随便找了一个爬取的股票文件改的名字
# usecols 就是说我只用这些列其他列不需要
# parse_dates 由于csv只储存str、int、float格式无法储存日期格式,所以读取是设定吧日期列读作时间格式
df = pd.read_csv('stock.csv', encoding='gbk', usecols=[0, 3, 4, 5, 6, 11], parse_dates=['日期'] )
df.head()结果如下:
格式转换,在创建table时需要设置列的类型,这里写一个function 将pandas的类型转换为sql类型:
# 一个根据pandas自动识别type来设定table的type
def make_table_sql(df):
columns = df.columns.tolist()
types = df.ftypes
# 添加id 制动递增主键模式
make_table = []
for item in columns:
if 'int' in types[item]:
char = item + ' INT'
elif 'float' in types[item]:
char = item + ' FLOAT'
elif 'object' in types[item]:
char = item + ' VARCHAR(255)'
elif 'datetime' in types[item]:
char = item + ' DATETIME'
make_table.append(char)
return ','.join(make_table)
创建table 并批量写入mysql:
# csv 格式输入 mysql 中
def csv2mysql(db_name, table_name, df):
# 创建database
cursor.execute('CREATE DATABASE IF NOT EXISTS {}'.format(db_name))
# 选择连接database
conn.select_db(db_name)
# 创建table
cursor.execute('DROP TABLE IF EXISTS {}'.format(table_name))
cursor.execute('CREATE TABLE {}({})'.format(table_name,make_table_sql(df)))
# 提取数据转list 这里有与pandas时间模式无法写入因此换成str 此时mysql上格式已经设置完成
df['日期'] = df['日期'].astype('str')
values = df.values.tolist()
# 根据columns个数
s = ','.join(['%s' for _ in range(len(df.columns))])
# executemany批量操作 插入数据 批量操作比逐个操作速度快很多
cursor.executemany('INSERT INTO {} VALUES ({})'.format(table_name,s), values)
然后运行function :
csv2mysql(db_name=stock, table_name=test1 , df)
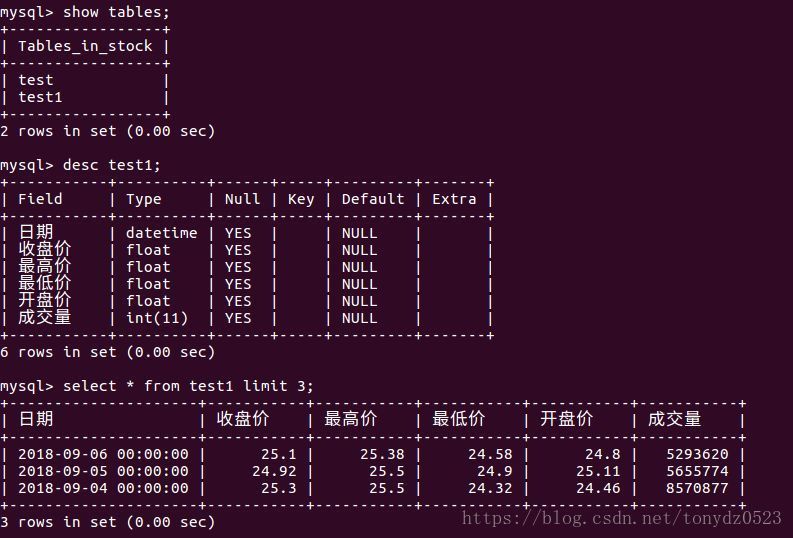
测试一下是否成功写入:
cursor.execute('SELECT * FROM test1 LIMIT 5')
# scroll(self, value, mode='relative') 移动指针到某一行; 如果mode='relative',则表示从当前所在行移动value条,如果 mode='absolute',则表示从结果集的第一行移动value条.
cursor.scroll(4)
cursor.fetchall()
结果如下:
登入数据库查看
使用完毕关闭光标和连接:
# 光标关闭
cursor.close()
# 连接关闭
conn.close()
## 使用sqlalchemy
使用sqlalchemy 要比pymysql 简单一些
安装 pip install sqlalchemy
同样先与mysql 建立连接:
import pandas as pd
from sqlalchemy import create_engine
from datetime import datetime
from sqlalchemy.types import NVARCHAR, Float, Integer
# 连接设置 连接mysql 用户名ffzs 密码666 地址localhost:3306 database:stock
engine = create_engine('mysql+pymysql://ffzs:666@localhost:3306/stock')
# 建立连接
con = engine.connect()
pandas读取csv文件:
df = pd.read_csv('stock.csv', encoding='gbk',usecols=[0, 3, 4, 5, 6, 11], parse_dates=['日期'])
类型转换function
# pandas类型和sql类型转换
def map_types(df):
dtypedict = {}
for i, j in zip(df.columns, df.dtypes):
if "object" in str(j):
dtypedict.update({i: NVARCHAR(length=255)})
if "float" in str(j):
dtypedict.update({i: Float(precision=2, asdecimal=True)})
if "int" in str(j):
dtypedict.update({i: Integer()})
return dtypedict
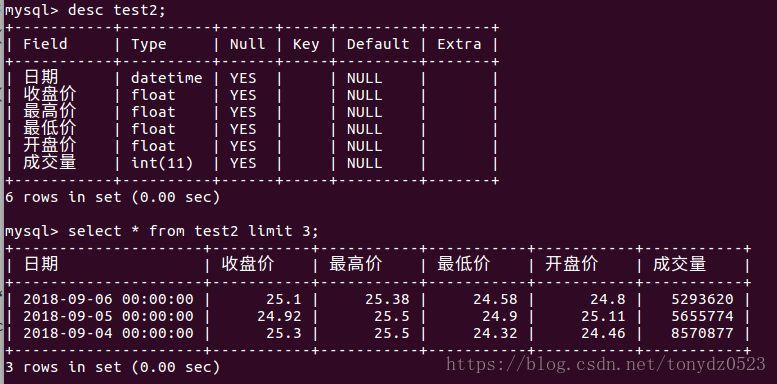
存入mysql :
dtypedict = map_types(df)
# 通过dtype设置类型 为dict格式{“col_name”:type}
df.to_sql(name='test2', con=con, if_exists='replace', index=False, dtype=dtypedict)
看下结果:
下一篇会对爬取的股票数据进行简单分析。。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!