社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题。这里主要记录自己的GPU自学历程。
GPU通常包含大量的数学计算单元,因此性能瓶颈往往不在于芯片的数学计算吞吐量,而在于芯片的内存带宽,即有时候输入数据的速率甚至不能维持满负荷的运算。 于是我们需要一些手段来减少内存通信量。 目前的GPU均提供了64KB的常量内存,并且对常量内存采取了不同于全局内存的处理方式。 在某些场景下,使用常量内存来替换全局内存可以有效地提高通信效率。
常量内存具有以下特点:
常量内存带来性能提升的原因主要有两个:
对于原因1,涉及到 线程束(Warp)的概念。
在CUDA架构中,线程束是指一个包含32个线程的集合,这个线程集合被“编织在一起”并且以“步调一致(Lockstep)”的形式执行。 即线程束中的每个线程都将在不同数据上执行相同的指令。
当处理常量内存时,NVIDIA硬件将把单次内存读取操作广播到每个半线程束(Half-Warp)。在半线程束中包含16个线程,即线程束中线程数量的一半。如果在半线程束中的每个线程从常量内存的相同地址上读取数据,那么GPU只会产生一次读取请求并在随后将数据广播到每个线程。如果从常量内存中读取大量数据,那么这种方式产生的内存流量只是使用全局内存时的1/16。
对于原因2,涉及到缓存的管理
由于常量内存的内容是不发生变化的,因此硬件将主动把这个常量数据缓存在GPU上。在第一次从常量内存的某个地址上读取后,当其他半线程束请求同一个地址时,那么将命中缓存,这同样减少了额外的内存流量。
另一方面, 常量内存的使用也可能会对性能产生负面的影响。半线程束广播功能实际上是一把双刃剑。虽然当所有16个线程都读取相同地址时,这个功能可以极大提升性能,但当所有16个线程分别读取不同的地址时,它实际上会降低性能。因为这16次不同的读取操作会被串行化,从而需要16倍的时间来发出请求。但如果从全局内存中读取,那么这些请求会同时发出。
下面通过一个光线跟踪的实例来说明一下常量内存的使用效果。
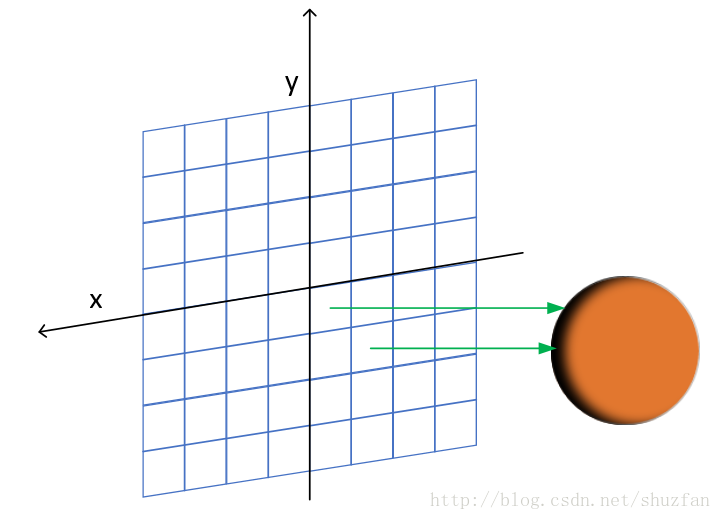
下面的光线跟踪不涉及光源以及光线反射,只是简单的类似于“投影”的操作,如下图所示。
投影平面前面会有大量存在重叠的球体(这里我只画了1个),投影平面上每个像素点会发射出一条射线(射线方向认为是Z方向),我们需要和所有球体判断相交情况。 如果和多个球体相交,则选择最近的交点(即无法看到遮挡的球体)。 根据交点到对应球心的距离(Z方向距离)确定投影点的像素值,距离越远则越亮。
如果距离为无穷大,则表明没有相交,则置为黑色背景。
由于每个像素都会射出一条射线,然后和所有球体计算相交,因此需要经常访问固定的球体参数。 因此,为了提高访问效率,我们将球体信息定义到常量内存。
代码如下(需要OpenCV):
#include "cuda_runtime.h"
#include "highgui.hpp"
#include <time.h>
using namespace cv;
#define INF 2e10f // 定义无穷远距离(用于表示没有球体相交)
#define rnd(x) (x*rand()/RAND_MAX)
#define SPHERES 100 //球体数量
#define DIM 1024 //图像大小
// 球体信息结构体
struct Sphere
{
float r, g, b; // 球体颜色
float radius; // 球体半径
float x, y, z; // 球体空间坐标
// 计算从(ox, oy)发出的射线与球体的交点
// n为交点到球心的距离(Z方向距离)与球半径的比值
__device__ float hit(float ox, float oy, float *n)
{
float dx = ox - x;
float dy = oy - y;
if (dx*dx + dy*dy < radius*radius)
{
float dz = sqrt(radius*radius - dx*dx - dy*dy);
*n = dz / sqrt(radius*radius);
return dz + z;
}
return -INF;
}
};
// 声明球体数组
__constant__ Sphere s[SPHERES];
// 光线跟踪核函数
//__global__ void rayTracing(unsigned char* ptr, Sphere* s)
__global__ void rayTracing(unsigned char* ptr)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 以图像中心为坐标原点
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++)
{
float n;
float t = s[i].hit(ox, oy, &n);
// 判断是否存在相交球体
if (t > maxz)
{
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 3 + 2] = (int)(r * 255);
ptr[offset * 3 + 1] = (int)(g * 255);
ptr[offset * 3 + 0] = (int)(b * 255);
}
int main(int argc, char* argv[])
{
// 建立事件用于计时
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
Mat bitmap = Mat(Size(DIM, DIM), CV_8UC3, Scalar::all(0));
unsigned char *devBitmap;
(cudaMalloc((void**)&devBitmap, 3 * bitmap.rows*bitmap.cols));
// cudaMalloc((void**)&s, sizeof(Sphere)*SPHERES);
// 创建随机球体
Sphere *temps = (Sphere*)malloc(sizeof(Sphere)*SPHERES);
srand(time(0)); //随机数种子
for (int i = 0; i < SPHERES; i++)
{
temps[i].r = rnd(1.0f);
temps[i].g = rnd(1.0f);
temps[i].b = rnd(1.0f);
temps[i].x = rnd(1000.0f) - 500;
temps[i].y = rnd(1000.0f) - 500;
temps[i].z = rnd(1000.0f) - 500;
temps[i].radius = rnd(100.0f) + 20;
}
// cudaMemcpy(s, temps, sizeof(Sphere)*SPHERES, cudaMemcpyHostToDevice);
// 将球体参数copy进常量内存
cudaMemcpyToSymbol(s, temps, sizeof(Sphere)*SPHERES);
free(temps);
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
// rayTracing<<<grids, threads>>>(devBitmap, s);
rayTracing << <grids, threads >> > (devBitmap);
cudaMemcpy(bitmap.data, devBitmap, 3 * bitmap.rows*bitmap.cols, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("Processing time: %3.1f msn", elapsedTime);
imshow("Ray Tracing", bitmap);
waitKey();
cudaFree(devBitmap);
// cudaFree(s);
return 0;
}
实验效果如下图:
为了直观地看到常量内存带来的增益,我们需要测量程序运行的时间。
以往的话我们大多采用CPU或者操作系统中的某个计时器,但是这很容易带来各种延迟(包括操作系统线程调度、高精度CPU计时器可用性等)。 特别地,核函数与CPU程序是异步执行的,这更易带来意想不到的延迟。当然,针对这个问题,我们可以使用cudaThreadSynchronize()函数进行同步然后再利用CPU计时。
除了采用CPU主机端计时之外,更准确的方法应该是利用CUDA的事件API。
计时模板如下:
cudaEvent_t start, stop;
float time = 0.f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
/*****************************************
*********** 需要计时的代码部分**************
******************************************/
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&ime, start, stop);
std::cout << time << std::endl;
cudaEventDestroy(start);
cudaEventDestroy(stop);参考资料
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!