社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题。这里主要记录自己的GPU自学历程。
在前面的章节中,我们不止一次看到了在调用定义的核函数时采用了类似下面的形式:
kernel<<<1,1>>>(param1,param2,...)“<<< >>>”中参数的作用是告诉我们该如何启动核函数(比如如何设置线程)。 下面我们先直接介绍参数概念,然后详细说明其意义。
当我们使用 gloabl 声明核函数后
__global__ void kernel(param list){ }在主机端(Host)调用时采用如下的形式:
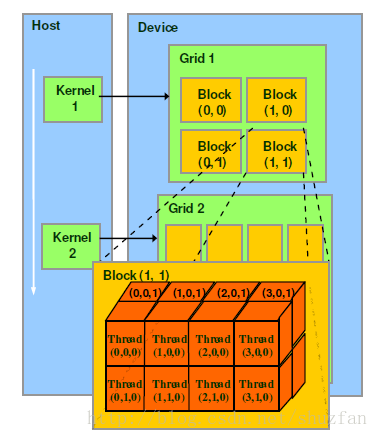
kernel<<<Dg,Db, Ns, S>>>(param list);关于CUDA的线程结构,有着三个重要的概念: Grid, Block, Thread
下图是一个结构关系图:
此外,Block, Thread的组织结构可以是可以是一维,二维或者三维。以上图为例,Block, Thread的结构分别为二维和三维。
CUDA中每一个线程都有一个唯一标识ThreadIdx,这个ID随着组织结构形式的变化而变化。 (注意:ID的计算,同计算行优先排列的矩阵元素ID思路一样。)
回顾之前我们的矢量加法:
// Block是一维的,Thread也是一维的
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x *blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}// Block是一维的,Thread是二维的
__global__ void addKernel(int *c, int *a, int *b)
{
int i = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}// Block是二维的,Thread是三维的
__global__ void addKernel(int *c, int *a, int *b)
{
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int i = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
c[i] = a[i] + b[i];
}
下表是不同计算能力的GPU的技术指标(更多可参见 CUDA Toolkit Documentation)
当然也可以通过下面的代码来直接查询自己GPU的具体指标:
#include "cuda_runtime.h"
#include <iostream>
int main()
{
cudaError_t cudaStatus;
// 初获取设备数量
int num = 0;
cudaStatus = cudaGetDeviceCount(&num);
std::cout << "Number of GPU: " << num << std::endl;
// 获取GPU设备属性
cudaDeviceProp prop;
if (num > 0)
{
cudaGetDeviceProperties(&prop, 0);
// 打印设备名称
std::cout << "Device: " <<prop.name << std::endl;
}
system("pause");
return 0;
}其中 cudaDeviceProp是一个定义在driver_types.h中的结构体,大家可以自行查看其定义。
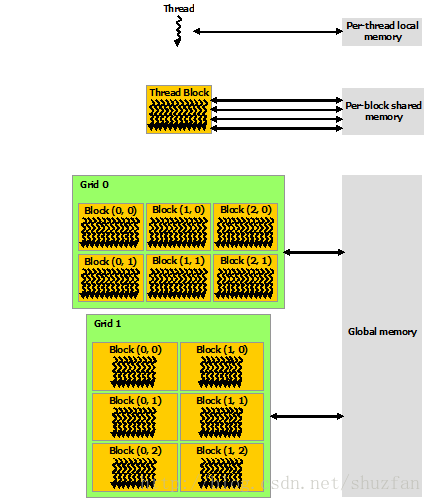
如下图所示,每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
这种特殊的内存结构直接影响着我们的线程分配策略,因为需要通盘考虑资源限制及利用率。 这些后续再进行讨论。
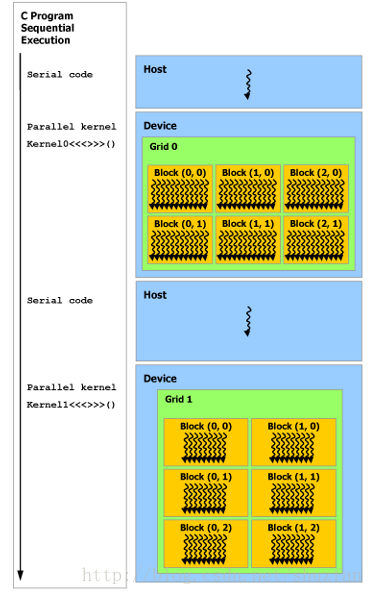
如下图所示,是常见的GPU程序的处理流程,其实是一种异构程序,即CPU和GPU的协同。
主机上执行串行代码,设备上则执行并行代码。
参考资料:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!