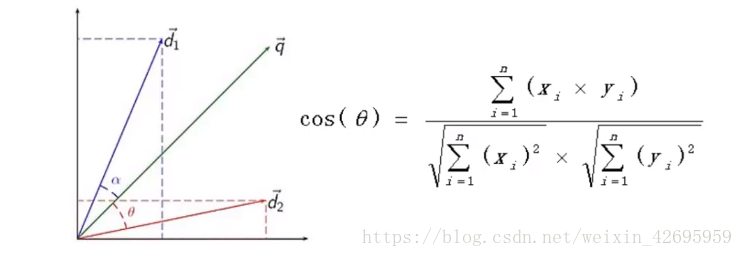社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
相似文本推荐:在用户阅读某篇文章的时候,为用户推荐更多与在读文章内容类似的文章。
**推荐:**指介绍好的人或事物,希望被任用或接受。数据挖掘领域,推荐包括相似推荐及协同过滤推荐。
**相似推荐:**指当用户表现出对某人或某物的兴趣时,为他推荐与之类似的人,或者物。核心定理:物以类聚,人以群分。
**协同过滤推荐:**是指利用已有用户群过去的行为或意见,预测当前用户最有可能喜欢哪些东西或对哪些东西感兴趣。
相关文章推荐的原理主要是余弦相似度。
**余弦相似度:**用向量空间中,两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近于1,就表明夹角越接近零度,也就是两个向量越相似,这个特征也叫余弦相似性。
下面进行代码演示:
前面的部分与之前的操作一样,首先构建语料库。
#相似文章推荐
import os;
import numpy;
import os.path;
import codecs;
#构建语料库
filePaths = [];
fileContents = [];
for root, dirs, files in os.walk(
r"C:Userswww12DesktopDAdata2.9SogouC.mini\Sample"
):
for name in files:
filePath = os.path.join(root, name);
filePaths.append(filePath);
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
import pandas;
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
接着进行分词处理,提取中文词
import re
zhPattern = re.compile(u'[u4e00-u9fa5]+')
import jieba
#分词
segments = []
filePaths = []
for index, row in corpos.iterrows():
segments = []
filePath = row['filePath']
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if zhPattern.search(seg):
segments.append(seg) #匹配中文分词
filePaths.append(filePath)
row['fileContent'] = " ".join(segments); #将分词间添加空格
过滤停用词,用sklearn包生成词频矩阵
from sklearn.feature_extraction.text import CountVectorizer
#导入停用词
stopwords = pandas.read_csv(
r"C:Userswww12DesktopDAdata2.9\StopwordsCN.txt",
encoding='utf8',
index_col=False,
quoting=3,
sep="t"
)
#保留长度大于0的词,过滤停用词
countVectorizer = CountVectorizer(
stop_words=list(stopwords['stopword'].values),
min_df=0, token_pattern=r"bw+b"
)
#将分词结果转化成词频矩阵
textVector = countVectorizer.fit_transform(
corpos['fileContent']
)
接着计算每篇文章之间的余弦相似度,用到的包是sklearn.metrics
#计算每行之间的余弦距离
from sklearn.metrics import pairwise_distances# 该方法用来计算余弦相似度
#余弦相似度计算得到每篇文章之间的余弦距离矩阵,数值越小代表越相似
distance_matrix = pairwise_distances(
textVector,
metric="cosine"
)#第一个参数为要计算的矩阵,第二个参数为计算公式,即余弦距离
#距离矩阵变成数据框
m = 1- pandas.DataFrame(distance_matrix)
m.columns = filePaths;
m.index = filePaths;
#对每行进行排序,取所有行中最相似的前五个
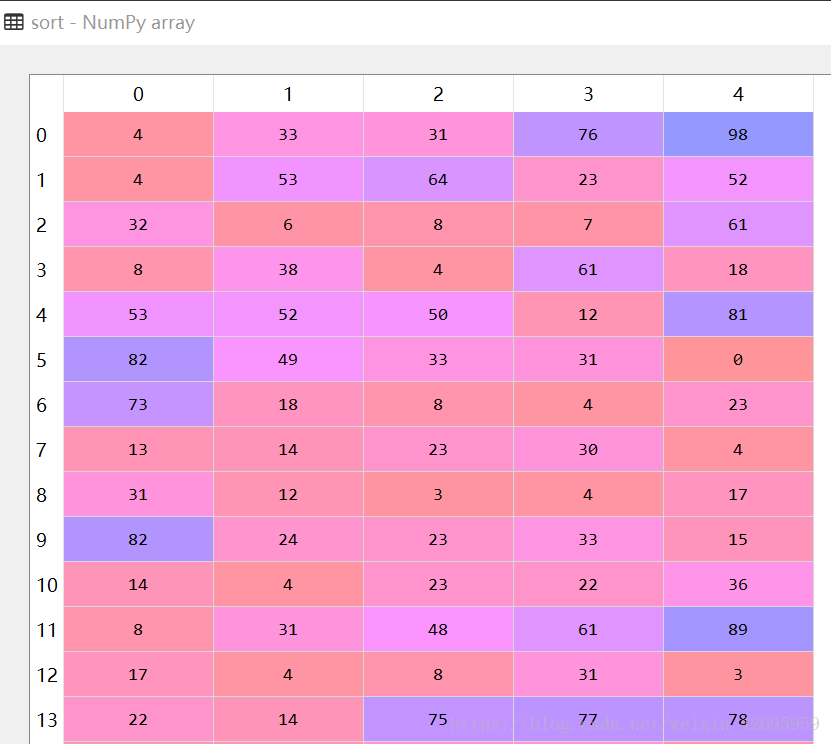
sort = numpy.argsort(distance_matrix, axis=1)[:,1:6]
#得到每篇文章最相似的五篇文章
similarity5 = pandas.Index(filePaths)[sort].values
#最后结果生成数据框格式
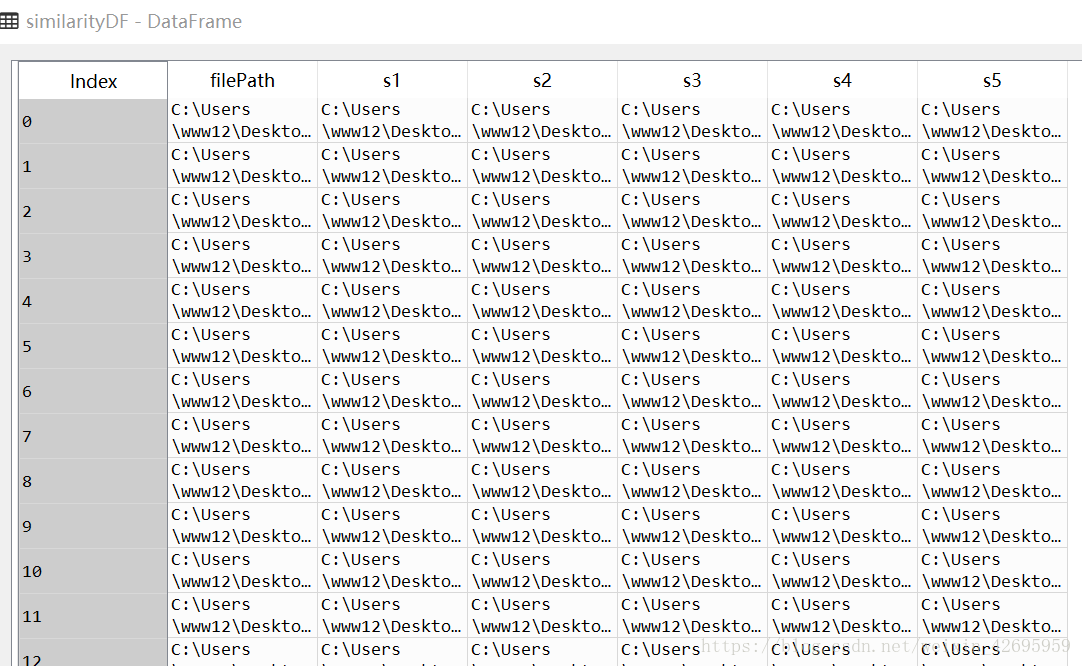
similarityDF = pandas.DataFrame({
'filePath':corpos.filePath,
's1': similarity5[:, 0],
's2': similarity5[:, 1],
's3': similarity5[:, 2],
's4': similarity5[:, 3],
's5': similarity5[:, 4]
})
最后就得到了每篇文章的五篇相似文章,如图:
API小结:余弦距离计算方法:
sklearn.metrics.pairwise_distances(metrix,metric=’‘cosine’’)
metrix:表示要计算的矩阵
cosine:余弦距离
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!