社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
pip install requests
pip install BeautifulSoup4
from bs4 import BeautifulSoup
import requests
import re
import os,sys
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
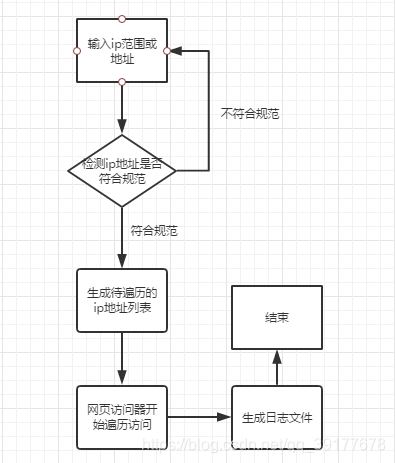
规定输入如下格式的ip地址:
1.172.16.1.1~172.16.1.255
2.172.16.1.1
粗略地址规范检测
# 地址规范检测
def ip_regular_test(ip):
if bool(re.findall('d+.d+.d+.d+', ip)):
return 1
else:
return 0
# 地址拆分
def ip_split(ip_range):
if '~' in ip_range:
ip1, ip2 = ip_range.split('~')
if ip_regular_test(ip1) and ip_regular_test(ip2):
return ip1, ip2
else:
print('错误的ip')
else:
if ip_regular_test(ip_range):
return ip_range, ip_range
else:
print('错误的ip')
输入:将第一部分的元组作为参数传入
返回:列表address_list
base = [str(x) for x in range(10)] + [ chr(x) for x in range(ord('A'),ord('A')+6)]
#十进制0~255转化为二进制,补0到8位
def dec2bin80(string_num):
num = int(string_num)
mid = []
while True:
if num == 0: break
num,rem = divmod(num, 2)
mid.append(base[rem])
result = ''.join([str(x) for x in mid[::-1]])
length = len(result)
if length < 8:
result = '0' * (8 - length) + result
return result
#十进制0~255转化为二进制,补0到32位
def dec2bin320(string_num):
num = int(string_num)
mid = []
while True:
if num == 0: break
num,rem = divmod(num, 2)
mid.append(base[rem])
result = ''.join([str(x) for x in mid[::-1]])
length = len(result)
if length < 32:
result = '0' * (32 - length) + result
return result
#十进制0~255转化为二进制,不补零
def dec2bin(string_num):
num = int(string_num)
mid = []
while True:
if num == 0: break
num,rem = divmod(num, 2)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
#二进制转换为十进制
def bin2dec(string_num):
return str(int(string_num, 2))
#ip列表生成
def iplist(string_startip,string_endip):
#分割IP,然后将其转化为8位的二进制代码
start = string_startip.split('.')
start_a = dec2bin80(start[0])
start_b = dec2bin80(start[1])
start_c = dec2bin80(start[2])
start_d = dec2bin80(start[3])
start_bin = start_a + start_b + start_c + start_d
#将二进制代码转化为十进制
start_dec = bin2dec(start_bin)
end = string_endip.split('.')
end_a = dec2bin80(end[0])
end_b = dec2bin80(end[1])
end_c = dec2bin80(end[2])
end_d = dec2bin80(end[3])
end_bin = end_a + end_b + end_c + end_d
#将二进制代码转化为十进制
end_dec = bin2dec(end_bin)
#十进制相减,获取两个IP之间有多少个IP
count = int(end_dec) - int(start_dec)
#生成IP列表
address_list = []
for i in range(0,count + 1):
#将十进制IP加一,再转化为二进制(32位补齐)
plusone_dec = int(start_dec) + i
plusone_dec = str(plusone_dec)
address_bin = dec2bin320(plusone_dec)
#分割IP,转化为十进制
address_a = bin2dec(address_bin[0:8])
address_b = bin2dec(address_bin[8:16])
address_c = bin2dec(address_bin[16:24])
address_d = bin2dec(address_bin[24:32])
address = address_a + '.'+ address_b +'.'+ address_c +'.'+ address_d
address_list.append(address)
return address_list
# 页面访问器
def page_visitor(ip, mode='http'):
http_mode = 'http://{}'
if mode == 'https':
http_mode = 'https://{}'
try:
req = requests.get(http_mode.format(ip), headers=header, timeout=0.3)
print('连接成功,正在提取页面概要')
except ConnectionError as e:
print(e)
return 0
except:
print('{}未能连接成功'.format(ip))
return ip, '连接超时'
# 粗略提取页面前10个分词
page_content = BeautifulSoup(req.content.decode('utf8', 'ignore'), 'html.parser').get_text().split()
if len(page_content) > 10:
print('{}概要:{}'.format(ip, page_content[0:10]))
else:
print('{}概要:{}'.format(ip, page_content))
# 成功后保存成功log
logger((ip, page_content), 'successful')
return ip, page_content
# 日志创建
def logger(data, name, encoding='gbk'):
try:
with open('{}.log'.format(name), 'a+', encoding=encoding) as f:
f.write('ip:{}tcontent{}'.format(*data))
f.write('rn')
except UnicodeEncodeError:
logger(data, name, encoding='utf8')
if __name__ == '__main__':
# 流程控制
ip_range = input('请输入需要扫描的ip范围:n例:172.16.1.1~172.16.1.255n请在右侧输入>>>')
# 地址拆分
ip_range = ip_split(ip_range)
# 获取地址列表
ip_list = iplist(*ip_range)
# 遍历访问
for ip in ip_list:
print('正在爬取:{}'.format(ip))
log = page_visitor(ip)
logger(log, 'history')
print('ylgb spider 爬行结束')
通过查询ip,可以看到47.74.0.0~47.127.255.255都是阿里云的ip,大约三百五十万,当然,这么个简单的小东西要爬这么多是很难的。于是选了一小段ip来爬。


如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
