社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
网络上的服务器,无论是嵌入式的网络设备,还是pc上服务器,整体结构以及主要思想都大体相同:根据业务模型确定主要数据结构,根据数据结构确定线程模型,在各个业务线程内根据围绕主要数据结构进行的操作确定状态机模型,低层使用网络层收发数据完成和其它网元的通讯。线程交互模型简单描述如下图:
图1 线程交互模型
相对而言,网络层的实现相对呆板、模式化,这个层面的要点在系统调用,实现方式要符合操作系统提供的api允许的使用方式,而不能天马行空想当然,因此提高这部分能力的重点在于系统性的学习(《unix网络编程》),不在于经验。
网络层有3部分构成:连接细节、多路复用函数、协议解析。
(1)连接细节。要实现各个协议的网络层(协议栈),首先要面对的就是承载该协议的传输层协议,udp还是tcp,理论本身就不再多说了。简单说下编程上的差异:udp的网络连接简单、收数据简单,tcp的则网络连接复杂、收数据需要在应用层面确定是否一个收包完毕,可以参见《服务器设计系列:网络模型》。
(2)多路复用函数。除了处理udp、tcp本身网络连接的系统调用之外,还存在和udp/tcp无关的多路复用函数(select等),它们可以监控tcp的网络事件,也可以监控udp的网络事件,属于网络层的核心驱动部分。
(3)协议解析。这部分相对独立,是网络层中和网络连接、收发消息无关的部分,主要功能则是对该协议各种消息的解包(decode)、打包(encode)。
网络层的主要线程是多路复用监控线程(select/poll/epoll_wait等),网络消息触发该线程的运转,如果是收包,则调用read类函数,收包完毕,进行解包操作,之后根据需要向业务线程发送消息(也可以收包完毕后即把数据包裹在消息中发送给业务线程,由业务线程解包,单独把解包打包操作归在网络层中)。
性能方面:为了描述方便,引入使用场景:转发rtp码流,这个场景需要尽量大的并发行和实时性。
(1)高性能函数。如果系统支持,使用epoll/port/kqueue等高性能多路复用函数。在此,将多路复用监控线程封装在RtpService类中,将rtp连接,封装在RtpConnection类中。使用模型可以参见《服务器设计系列:网络模型》。
(2)多线程支持。启动多个RtpService示例,也既是启动多个多路复用监控线程。将RtpConnection对象均匀的插入到各个RtpService中,同时在RtpConnection中记录它属于的RtpService,便于删除的时候找到它所在的RtpService。
(3)收数据线程直接转发。处理实时性的需要,一定要在收数据的线程中转发数据,而不是向其它线程发送消息,让其它线程完成发送。这样做一是避免不必要的内存复制,最重要的是线程调度引起的时间不确定性不能保证转发的实时性。
(4)读写锁代替普通锁。分发数据的时候(转发不需要)势必要扫描一个容器中的对象,进行分发操作,分发发生在不同的线程中,加锁成为必然。读写锁代替普通锁,使扫描操作不必互斥,也避免(2)中的多线程不能发挥多线程的效果。实际测试发现,linux2.6内核中的读写锁,只有在静态初时化的时候,才能写优先,使用pthread_rwlock_init进行初始化,不管如何设置它的属性(即便是设置属性为写优先),都不能实现写优先效果,因此需要自己使用pthread_mutex_t和pthread_cond_t实现写优先的读写锁,具体实现的细节就不再多说了(可以参考《服务器设计系列:线程》中线程消息队列中锁的实现),重要的是想法,不是实现。写优先的必要性是因为转发线程活跃频繁,而读线程可以一直进入读锁,造成写线程永久性的处于等待状态。
(5)使用Epoll的ET模式。再此对epoll多说一点,在《服务器设计系列:网络模型》中因为我当时的测试场景是普通的http交互,得出“LT和ET性能相当”的结论,跟帖中网友bluesky给予更正,非常感谢。在这个rtp转发的场景中,特别适合ET模式,一次触发,必须读尽接收缓冲区的数据,一是保证转发实时性,一是避免剩余数据再次触发(并发高的情况下,多路复用函数的被触发已非常频繁,因此要尽量减少不必要的触发),这个场景下,多一次的读操作微不足道。
(6)减少系统调用次数。系统调用是比内存copy性能更差的操作,这个再后面的文章中会再详细描述。网络层中的系统可以减少的就是read/recv/recvfrom类的操作,极端化低性能的操作就是一次读一个字节,造成系统调用的次数大幅上升,一般的做法,是开辟缓存(比如char buf[4096];),一次读取尽可能多的字节。
(7)二进制包使用结构直接解包,字符性包延迟解包。这两点的出发点都是尽量减少内存复制。
二进制解包举例:首先根据协议规定的包结构,定义结构体。比如(注:网友powervv 跟帖指出,要点在于大小端主机序、网络序和主机序之间的转换、以及字节对齐问题,避免误导读者,举例做出修改):
struct RTPHeader
{
#if __BYTE_ORDER == __BIG_ENDIAN
unsigned char v:2;
unsigned char p:1;
unsigned char x:1;
unsigned char cc:4;
unsigned char m:1;
unsigned char pt:7;
#else
unsigned char cc:4;
unsigned char x:1;
unsigned char p:1;
unsigned char v:2;
unsigned char pt:7;
unsigned char m:1;
#endif
unsigned seq:16;
unsigned tm:32;
unsigned ssrc:32;
};Packet *pack=(Packet *)bufchar buf[12];
Packet *pack=(Packet *)buf;
packe->v=2;
...
pack->seq=htons(1);struct FieldLoc
{
int loc;
int len;
};上面介绍了网络层部分。网络层基本都是多路复用函数作为运行的主线程,使用管道或者sockpair与之通讯,这是网络层线程的固有特点,和业务线程的呈现方式完全不同。经过网络层以后,数据开始流向业务线程,现在就顺着数据流向往上看。《服务器设计系列:线程》有对线程的一个入门描述,里面实现了一个消息队列。
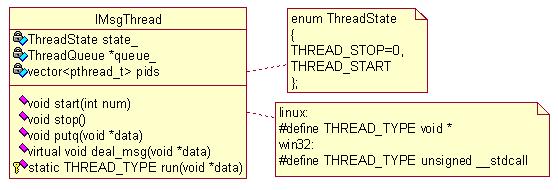
(1)业务线程的划分OA/CRM/WorkFlow的系统的关键在于业务的整理、面向对象的设计。而网络服务器不同,服务器的业务相对清晰,相关性强,它设计的关键在于数据模型的整理、线程的划分。可以说线程是服务器的骨架。这里引入几乎每个服务器都会有的一个基础模块:带消息队列的线程类。《服务器设计系列:线程》实现了一个简单的线程消息队列。在该消息队列基础之上进一步封装,实现带消息队列的线程类。该类的静态类图如下:
图2 带消息队列的线程类
ThreadQueue参见《服务器设计系列:线程》。上图中的start方法中参数默认为1,大于1则是线程池的实现,里面以线程的方式启动run函数,线程号存入vector,供停止时用。putq方法在其它线程中调用,向该线程发送消息,run方法中循环调用getq获取消息,调用deal_msg处理。实际的业务线程只需要继承该类即可成为带消息队列的线程。
(3)监控线程
基于上面这个基础模块,可以进一步开发监控线程,监控线程定时向各个线程发送心跳消息,各普通线程收到心跳信息后向监控线程回复,如果某个线程在一定时间内没有回复心跳,则可以采取进一步的修复处理。该方案可以作为系统安全的一个备选方案。
以上思想同样适用于嵌入式平台,很多嵌入式平台使用多进程协同处理消息,进程之间使用共享内存或者系统消息队列通讯,思想大同小异,并且同样可以设计监控进程。
(1)消息定义以及处理示例
有了线程消息队列,也有就有消息传递,接下来就是业务线程获取到消息处理消息。一个业务线程可能要处理多种消息,为区分不同的消息,引入消息类型。如下:
enum MsgType
{
MSG_TYPE_1=65,//64以下预留,用于统一的管理控制
MSG_TYPE_2,
..
MSG_TYPE_MAX
};
struct Msg
{
MsgType type;
MsgData data;
};switch(msg->type)
{
case MSG_TYPE_1:
do_msg_type_1_();
break;
case MSG_TYPE_2:
do_msg_type_2_();
break;
......
default:
do_default_msg_();
break;
}BEGIN_MESSAGE_MAP(SessionManager,SessionMsg)
ON_MESSAGE(MSG_TYPE_1, SessionManager::do_msg_type_1_)
ON_MESSAGE(MSG_TYPE_2, SessionManager::do_msg_type_2_)
......
END_MESSAGE_MAP() 另外,发送消息的方法/处理消息的方法职责要明确、命名要统一。发送消息的方法负责把方法参数转化为消息内容,调用putq发送消息,该方法不得操作本类的任何私有属性。处理消息的方法负责对消息做出处理、响应。命名方面,比如发送消息的方法可以以ON_开头,处理消息的方法可以以DO_开头。
这些规范不应该只是规范,而应该是发自内心的需要。当然没有什么规范是必须的,你仍然可以使用你喜欢的或者认为可行的方式,如果你的方法在程序1w行、10w行、50w行的时候,仍能清晰表现程序的数据流向,仍有很好的可维护性、可扩充性。
开发领域的烙印。不多说了,一句话:重要的是思想,不是平台和语言。
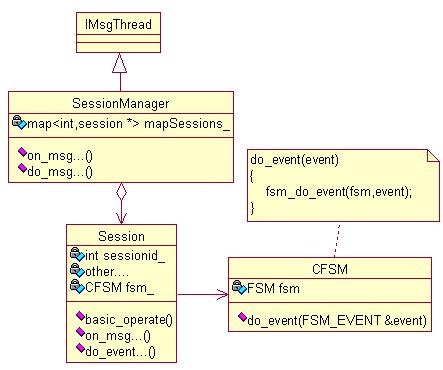
网络请求包经过网络层被解析翻译成程序自定义的消息,之后被投递到业务线程的线程消息队列中。业务线程在队列的另一端取出消息,开始处理。业务处理部分主要有会话类(Session)和会话管理类(SessionManager,常见该类为单例)。先给出类图:
图3 业务处理类图
1、SessionManager的职责:
(1)继承IMsgThread,调用该类的start方法,启动业务线程。
(2)提供on_.../do_...方法,供其它线程向业务线程投递消息,以及消息在业务线程的处理入口。
(3)主要的私有属性是session类的容器对象。容器类的选型的依据,首先是查询性能,之后是插入删除的性能。
array:数组下标为session对象的seesionid_(此处sessionid,不要理解为常见协议中的session字段,可以理解为session对象的索引)。可以做到插入删除(参考内存管理chunk分配算法)查询都在O(1)完成,缺点是不能动态增大。
为了实现动态增长,可以参考定长内存池的分配算法,动态申请255个array为一个chunk,所有chunk使用vector管理,各chunk中array编号递增255,同样可以达到增删查O(1)的效率。缺点:一方面,sessionid_会被重复使用,加上消息经过消息队列形成的处理延迟,可能造成下一个session对象处理上一个同样sessionid的session对象遗留下来的消息,实际使用中每个session对象有自己的状态机,这种残留的消息危害并不大。另一方面,需要自己实现,对比map的O(logn),这点细微的性能提升无任何意义(也就是减少了几次整型之间的对比)。相比不需要自己额外实现的普通数组还算有点实用价值。
vector:如果被插入的session的sessionid是递增的,查询可以做到折半查找logn的性能,但随机删除造成的内存移动是O(n),无法接受。
map:以红黑树为基础实现。增删查找的性能都可以平稳的保持在O(logn),当sessionid_为整型或者其operater<实现简单的时候是最常用的容器。
hash_map:哈希表,使用大量内存尽量使数据均匀分布,查询性能分hashcode的计算(hash函数)和查找部分,hash函数一般为所有有效信息的移位计算(经典的是字符串的33算法)叠加,查找部分最理想的是O(1),最差是O(n),取决于hash函数计算结果碰撞的几率。当sessionid_为字符串或者其operater<实现复杂的时候常用。
(4)该类处理消息的方式举例如下:(容器以map<int,session *> mapSessions_为例)
void do_msg_type_1_(MsgData &msg)
{
int id=msg.sessionid;
if(mapSessions_.find(id)!=mapSessions_.end())
{
session *pSession=mapSessions_[id];
pSession->on_msg_1(msg);
}
else
{
write_warning_log;
}
}void on_msg...(MsgData &msg)
{
EventData event;
event.detail=msg.detail;//todo
fsm.do_event(event);
}
void do_event...(EventData &event)
{
//change session's data or send msg to other thread or response request or others..
}参考文献:
服务器技术系列综述:http://www.cppblog.com/CppExplore/MyPosts.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!