社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
作者: 李佶澳 转载请保留:原文地址 发布时间:2018/07/28 23:17:00
这是”网易云课堂IT技术快速入门学院使用的素材。
操作和讲解视频位于《HyperLedger Fabric手把手入门》第四章中。
在Fabric1.2以及之前的版本中,使用kafka进行排序是比较贴近生产的。Fabric支持 的三种共识机制:solo(单台orderer相当于没有共识)、kafka、pbft(还在开发中)
Bringing up a Kafka-based Ordering Service中介绍了使用kafka进行排序时需要注意的事项。
Kafka is a distributed streaming platform,也就是我们通常将的“消息队列”。
生产者可以通过kafka将消息传递给消费者,kafka保证消息的顺序以及不丢失:
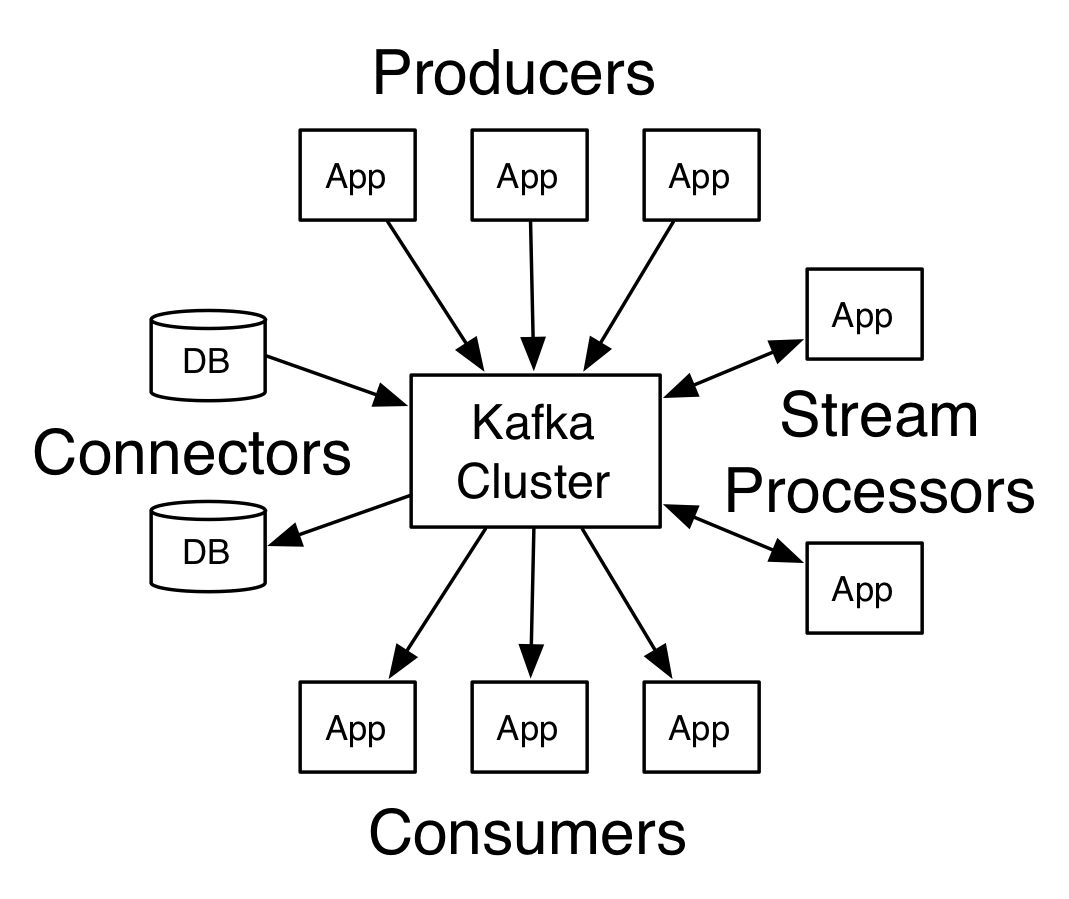
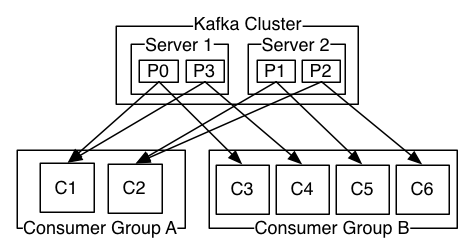
需要注意的是,kafka虽然是一个分布式系统,但它本身是被中心化管理,并且依赖zookeeper。
Fabric使用kafka的时候,为了安全,应当配置tls加密和认证,特别是经过公网的时候。为了演示不过于繁琐,下面 没有配置认证和tls加密,可以仔细研读Generate SSL key and certificate for each Kafka broker,进行尝试。
首先要有一个kafka集群,kafka本身是一个分布式系统,部署配置略复杂。
这里的重点是Fabric,因此只部署了单节点的kafk,参考kafka quick start。
下载kafka,下载地址:
wget http://mirror.bit.edu.cn/apache/kafka/1.1.1/kafka_2.12-1.1.1.tgz
tar -xvf kafka_2.12-1.1.1.tgz
cd kafka_2.12-1.1.1/
安装java,运行kafka需要java:
$ yum install -y java-1.8.0-openjdk
$ java -version
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
启动kafka自带的zookeeper:
./bin/zookeeper-server-start.sh config/zookeeper.properties
根据HyperLedger Fabric对kafka的需求修改kafka的配置文件,可以到这里查看kafka的所有配置项):
# 默认为false
unclean.leader.election.enable = false
# 根据kafka的节点数设置,需要小于备份数
# 意思完成了“指定数量”的备份后,写入才返回成功
min.insync.replicas = 1
# 数据备份数
default.replication.factor = 1
# 需要大于创世块中设置的 Orderer.AbsoluteMaxBytes
# 注意不要超过 socket.request.max.bytes(100M)
# 这里设置的是10M
message.max.bytes = 10000120
# 需要大于创世块中设置的 Orderer.AbsoluteMaxBytes
# 注意不要超过 socket.request.max.bytes(100M)
# 这里设置的是10M
replica.fetch.max.bytes = 10485760
# 当前orderer不支持kafka log,需要关闭这个功能
# @2018-07-29 08:19:32
log.retention.ms = -1
将上面的配置添加到config/server.properties中,然后启动kafka:
bin/kafka-server-start.sh config/server.properties
注意,你可能需要根据自己的实际情况配置advertised.listeners,使用kafka的机器需要能够通过 下面配置的hostname访问对应的节点,默认获取当前hostname,如果不配置hostname,可以修改为主机的对外IP。
#advertised.listeners=PLAINTEXT://your.host.name:9092
如果要进行多节点部署,在另一台机器上用同样方式部署:
注意更改server.properties中的zk地址,所有节点要使用同一个zk
其它节点不需要再启动zookeeper
zookeeper也可以进行多节点部署,这里就不展开了,参考zookeeper的资料。
部署启动后,测试一下kafka:
# 创建名为`test`的topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
# 查看topic
$ bin/kafka-topics.sh --list --zookeeper localhost:2181
test
# 启动生产者,并输入任意字符
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
>This is a message
>This is another message
# 启动消费者,接收到生产者的输入
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
需要注意现在(@2018-07-29 08:20:48)Fabric不支持切换共识机制!一旦选定了共识机制后,无法修改,除非清空所有数据,重新部署。
修改configtx.yaml中Orderer部分的内容,将共识机制修改为kafka,并填入kafka节点的地址:
101 Orderer: &OrdererDefaults
102 OrdererType: kafka
103 Addresses:
104 - orderer0.member1.example.com:7050
105 BatchTimeout: 2s
106 BatchSize:
107 MaxMessageCount: 10
108 AbsoluteMaxBytes: 8 MB # 注意要小于kafka中设置的10M
109 PreferredMaxBytes: 512 KB
110 MaxChannels: 0
111 Kafka:
112 Brokers:
113 - 192.168.88.11:9092 # 可以填入多个kafka节点的地址
如果kafka配置了tls加密,还要修改修改每个orderer的配置文件orderer.yaml中的Kakfa部分的内容,并上传证书。
重新生成创世块,重新部署Fabric,即可。
./prepare.sh example
ansible-playbook -i inventories/example.com/hosts -u root playbooks/manage_destroy.yml
ansible-playbook -i inventories/example.com/hosts -u root deploy_nodes.yml
ansible-playbook -i inventories/example.com/hosts -u root deploy_cli.yml
ansible-playbook -i inventories/example.com/hosts -u root deploy_cli_local.yml
Fabric重新部署启动后,可以看到kafka中多了一个名为genesis的topic,genesis是我们这里使用的创世区块的channel的名称:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
genesis
test
创建了名为mychannel的channel之后,kafka中多出了一个同名的topic:
$bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
genesis
mychannel
test
如果要重新部署,清空zk和kafka的数据:
rm -rf /tmp/zookeeper/
rm -rf /tmp/kafka-logs/
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
