社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
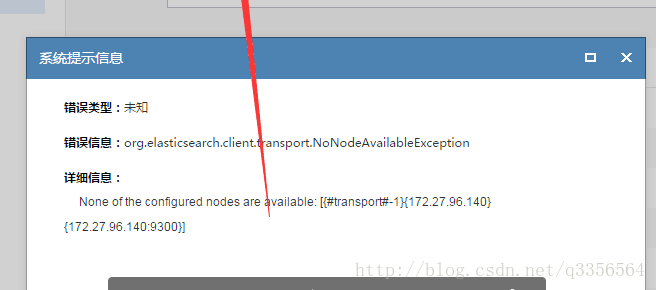
今天其他组的同事过来说他们es生产环境报了一个错误,因为对es有一些了解所以叫我帮忙看看具体错误如下
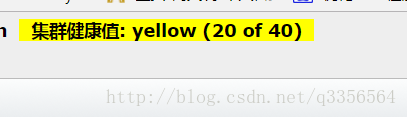
以前我自己在测试的时候也有发现这个错,但是那时候是由于自己本地模拟集群环境,虚拟机的网络没调好,但是过一会就恢复了没在意,所以和他们说也许过一会就会恢复,但是到了中午他们正式环境还是有这个问题,一直不能解决。我第一个感觉是不是es挂了,于是上head插件排查了。由于这个组是后台的人员查询使用定时任务导入es,所以es只有一个节点,登入head后发现集群状态为黄色,而且后台query能查出数据,基本排除了服务端的问题
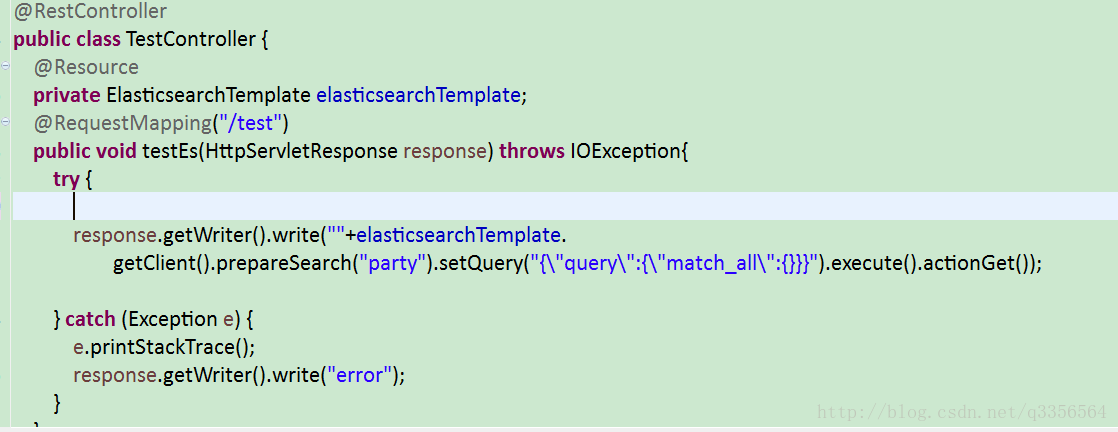
那么现在就往客户端方向排查了,我的第一感觉是可能客户端和服务端的网络环境有问题是不是2台机器的网络不通,但是询问过运维的同事之后,他们告诉我这2台的网络并没有问题,生产环境并没有很具体的日志,而且不能重启,断点,我想彻底验证下是不是2台机器网络出了问题,于是我快速的建立了个spring boot结合es的testjar打包上生产运行下,简单的写几行测试
快速的把jar放到和生产一台主机上部署一下(不得不说springboot真的很方便,和各种组件的结合直接加入start就好了,可以快速结合各种插件)。在浏览器输出restcontroller的地址
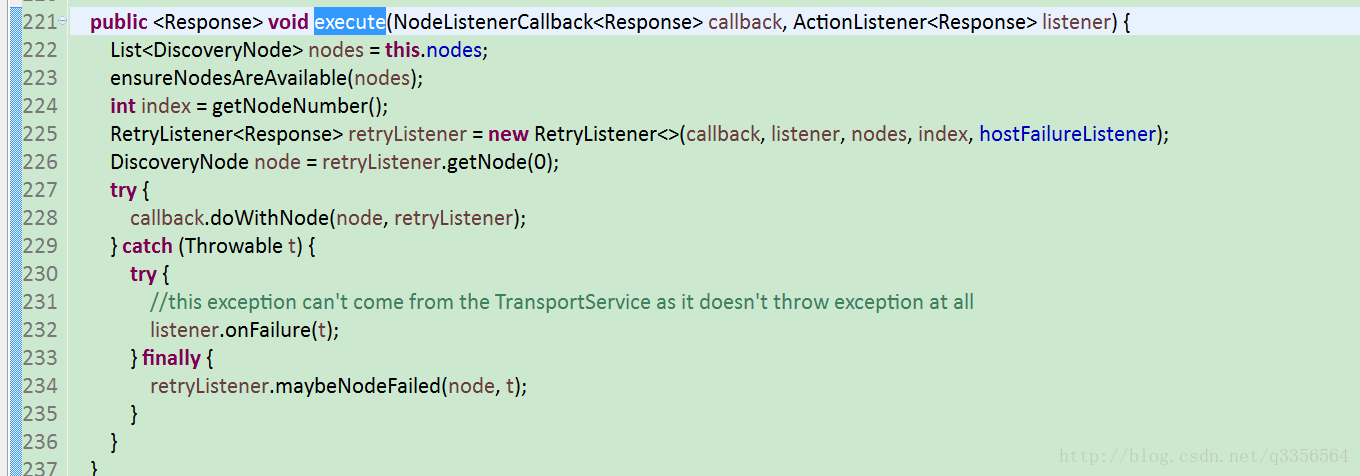
使用springboot进行连接连接es完全没有问题,这时候没有其他办法了,因为当初使用es的时候没出现什么问题并没有深入的去查看源码,查看tomcat的日志查询日志报错是这行话请求执行的时候经过TransportClientNodesService这个类
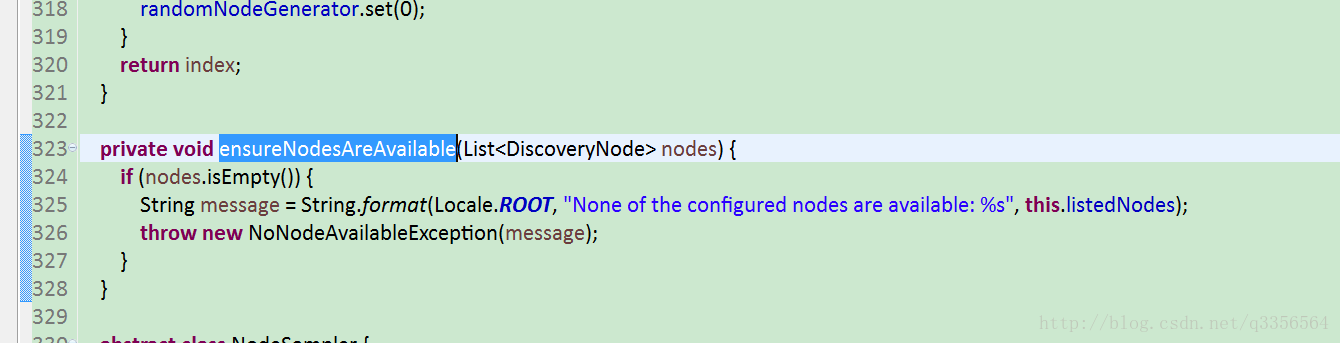
我们使用的es是2.34版本上github 下载TransportClientNodesService.java查看ensureNodesAreAvailable
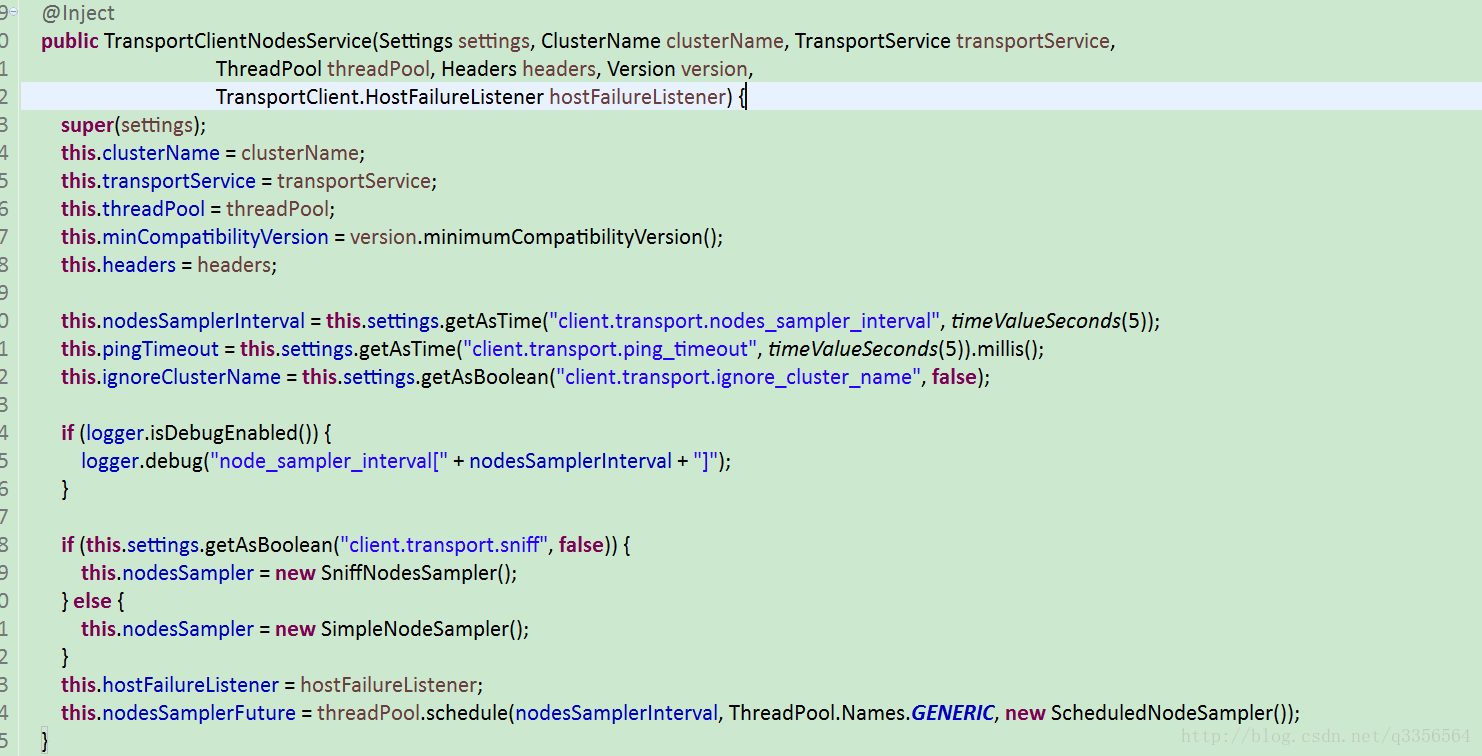
这里得知在请求发现的时候他是获取TransportClientNodesService nodes属性确认可用的节点,如果this.nodes属性为空就报错了,这时候我们来看下TransportClientNodesService 的有哪些属性,看看nodes到底怎么获取。
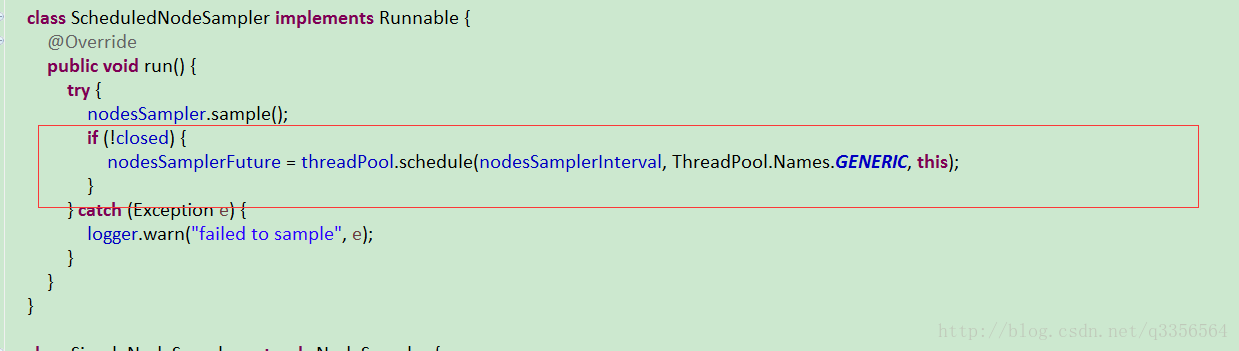
nodesSampler这个属性引起了我的注意变量名节点探测器,线程池5秒后执行任务ScheduledNodeSampler我们来看看ScheduledNodeSampler到底代码是怎么写的
由于我并没有配置client.transport.sniff所以应该使用的是默认的SimpleNodeSampler 实际上sample方法调用的就是 SimpleNodeSampler doSample方法
` @Override
protected void doSample() {
HashSet<DiscoveryNode> newNodes = new HashSet<>();
HashSet<DiscoveryNode> newFilteredNodes = new HashSet<>();
for (DiscoveryNode listedNode : listedNodes) {
if (!transportService.nodeConnected(listedNode)) {
try {
// its a listed node, light connect to it...
logger.trace("connecting to listed node (light) [{}]", listedNode);
transportService.connectToNodeLight(listedNode);
} catch (Throwable e) {
hostFailureListener.onNodeDisconnected(listedNode, e);
logger.info("failed to connect to node [{}], removed from nodes list", e, listedNode);
continue;
}
}
try {
LivenessResponse livenessResponse = transportService.submitRequest(listedNode, TransportLivenessAction.NAME,
headers.applyTo(new LivenessRequest()),
TransportRequestOptions.builder().withType(TransportRequestOptions.Type.STATE).withTimeout(pingTimeout).build(),
new FutureTransportResponseHandler<LivenessResponse>() {
@Override
public LivenessResponse newInstance() {
return new LivenessResponse();
}
}).txGet();
if (!ignoreClusterName && !clusterName.equals(livenessResponse.getClusterName())) {
logger.warn("node {} not part of the cluster {}, ignoring...", listedNode, clusterName);
newFilteredNodes.add(listedNode);
} else if (livenessResponse.getDiscoveryNode() != null) {
// use discovered information but do keep the original transport address, so people can control which address is exactly used.
DiscoveryNode nodeWithInfo = livenessResponse.getDiscoveryNode();
newNodes.add(new DiscoveryNode(nodeWithInfo.name(), nodeWithInfo.id(), nodeWithInfo.getHostName(), nodeWithInfo.getHostAddress(), listedNode.address(), nodeWithInfo.attributes(), nodeWithInfo.version()));
} else {
// although we asked for one node, our target may not have completed initialization yet and doesn't have cluster nodes
logger.debug("node {} didn't return any discovery info, temporarily using transport discovery node", listedNode);
newNodes.add(listedNode);
}
} catch (Throwable e) {
logger.info("failed to get node info for {}, disconnecting...", e, listedNode);
transportService.disconnectFromNode(listedNode);
hostFailureListener.onNodeDisconnected(listedNode, e);
}
}
nodes = validateNewNodes(newNodes);
filteredNodes = Collections.unmodifiableList(new ArrayList<>(newFilteredNodes));
}
}`
这里一共干了这几件事情
1、循环初始注册的地址列表listedNodes属性先去缓存里面取地址列表(ConcurrentMap)查询有就直接跳下一步请求节点具体信息,如果没有先进行一次轻连接(数据包较小的连接底层使用netty通信)如果timeout跳出本次循环,抛弃本次的连接地址
2、如果地址缓存列表向服务器请求livenessResponse(netty封装的网络通信)得到livenessResponse信息后查看是否有配置ignoreClusterName如果有把他加入 filteredNodes 里面属于不可用节点,连接失败的话移出已经有的节点缓存
3、把上面得到的新的节点列表赋值给nodes使得client得到最新的地址列表
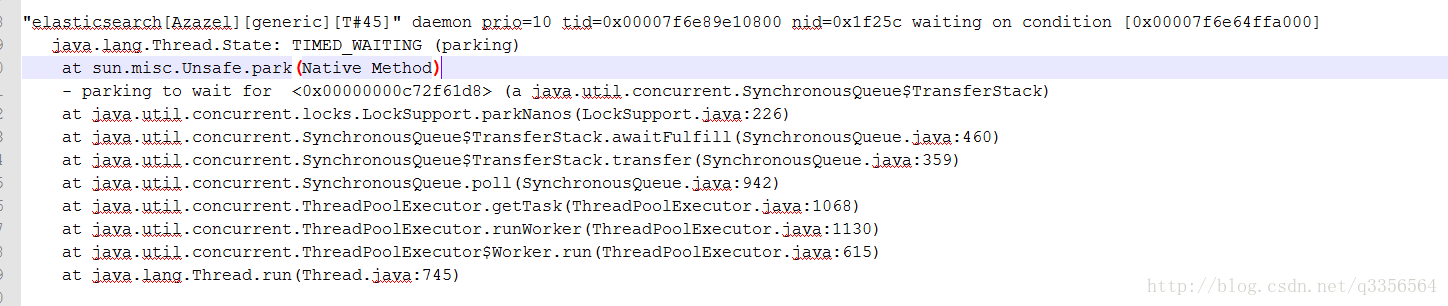
按照上面的代码就算暂时节点不能用在下一次5秒任务的时候也会自动恢复,而且已经测试过不是网络问题,这时候我严重怀疑这个任务并没有在运行,于是上生产环境打印jstack
多次打印都在time_wating 看了下代码任务触发条件
严重怀疑是生产的连接被关了导致任务没有运行,于是询问开发人员,果然在代码里发现这么一行话 到网上搜索了下
感觉有可能是这句话出现了问题,于是在本地试了下关掉client果然重现了这个问题。总结了下出现这个错误有可能是1.esclient被关闭 2.网络pingout超时导致,具体可能要根据生产系统的现象进行排查
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!