社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
腾讯AI开放平台提供了三大功能:自然语言处理、计算机视觉和智能语音。
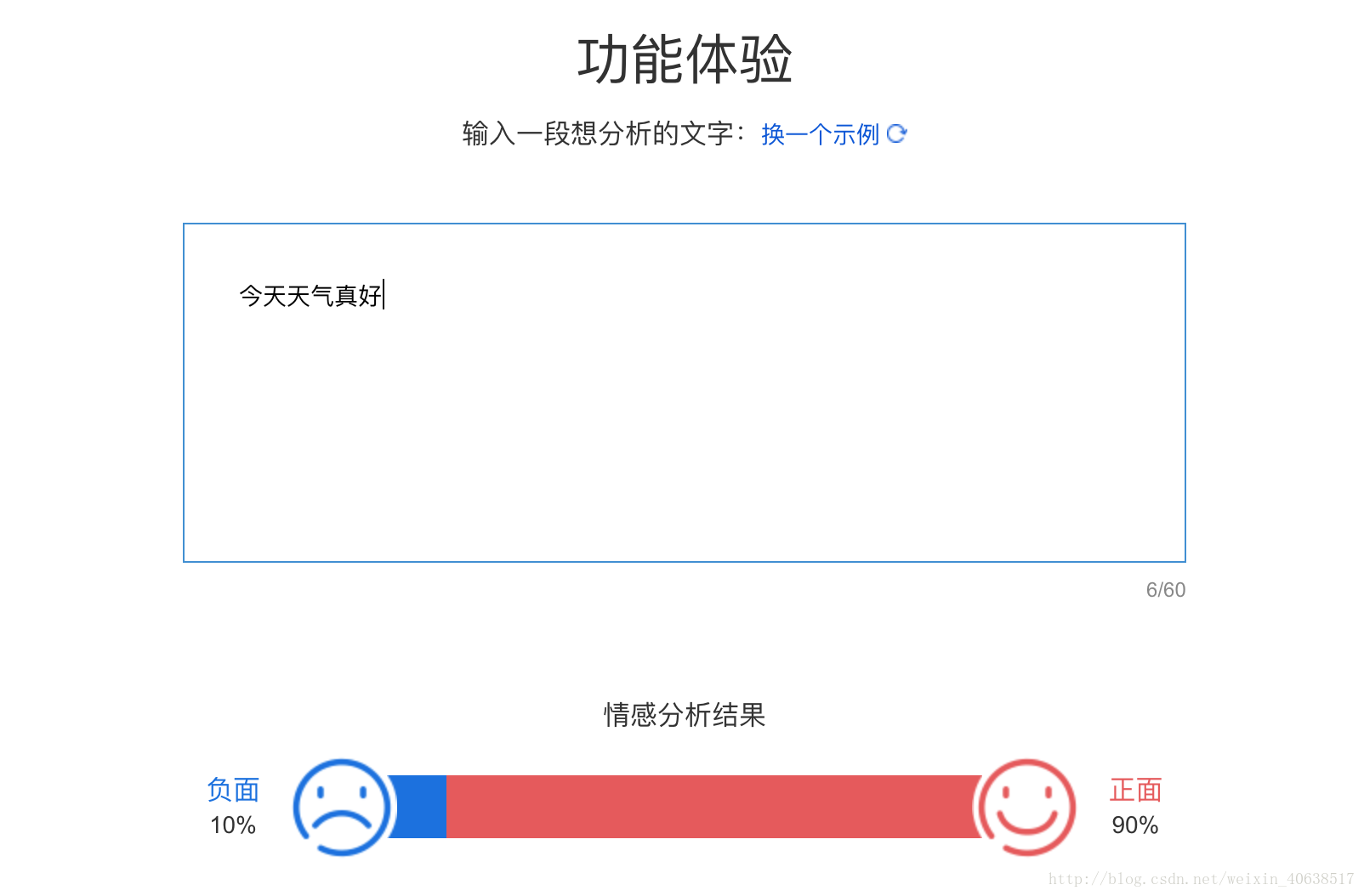
情感分析是自然语言处理下的一大分支,腾讯AI的情感分析界面如下:
这里介绍一下如何利用python来使用腾讯的情感分析API接口服务以便进行大量数据的情感分析。
1、首先你需要利用QQ号登陆该平台,进入到控制台。
2、创建应用,选择你需要使用的接口(这里以情感分析为例)。
3、进入应用详情、你就会看到你的AppID和AppKey。
4、参考情感分析的技术文档,利用python进行接入。
首先我们在调用API时要搞定接口鉴权,即签名算法。
根据接口鉴权的技术文档,可知签名算法采用MD5摘要方式实现,且算法的实现步骤技术文档里面很详细,刚好python里面有相应的包,直接import hashlib即可,我这里就直接贴代码了。
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: md5sign
Description :
Author : YOUQING
date: 2017/11/20
-------------------------------------------------
Change Activity:
2017/11/20:
-------------------------------------------------
"""
import hashlib
import time
import random
import string
import urllib
import sys
def get_params(plus_item):
'''请求时间戳(秒级),用于防止请求重放(保证签名5分钟有效)'''
t = time.time()
time_stamp=int(t)
'''请求随机字符串,用于保证签名不可预测'''
nonce_str = ''.join(random.sample(string.ascii_letters + string.digits, 10))
'''应用标志,这里修改成自己的id和key'''
app_id='XXXXXX'
app_key='XXXXXXXXXXXX'
'''值使用URL编码,URL编码算法用大写字母'''
text1=plus_item
text=urllib.quote(text1.decode(sys.stdin.encoding).encode('utf8')).upper()
'''拼接应用密钥,得到字符串S'''
sign_before='app_id='+app_id+'&nonce_str='+nonce_str+'&text='+text+'&time_stamp='+str(time_stamp)+'&app_key='+app_key
'''计算MD5摘要,得到签名字符串'''
m=hashlib.md5()
m.update(sign_before)
sign=m.hexdigest()
sign=sign.upper()
params='app_id='+app_id+'&time_stamp='+str(time_stamp)+'&nonce_str='+nonce_str+'&sign='+sign+'&text='+text
return params注意事项
1、app_id、app_key替换成自己应用详情里的相应内容
2、plus_item是你要输入的文本内容
3、文件名:md5sign
上一段代码得到的是请求参数,这里我们需要将API地址和请求参数拼接起来,然后采用请求方法GET,并用BeautifulSoup去解析(简单的爬虫知识)。
由于响应格式是JSON格式,我们采用json.loads来转换为字典,以便获取我们想要的内容(情感倾向、极性与文本内容)
代码如下:
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: tencent_api
Description :
Author : YOUQING
date: 2017/11/20
-------------------------------------------------
Change Activity:
2017/11/20:
-------------------------------------------------
"""
import requests
import md5sign
from bs4 import BeautifulSoup
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def get_content(plus_item):
url = "https://api.ai.qq.com/fcgi-bin/nlp/nlp_textpolar" # API地址
params = md5sign.get_params(plus_item)#获取请求参数
url=url+'?'+params#请求地址拼接
try:
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
allcontents=soup.select('body')[0].text.strip()
allcontents_json=json.loads(allcontents)#str转成dict
return allcontents_json["data"]["polar"],allcontents_json["data"]["confd"],allcontents_json["data"]["text"]
except Exception, e:
print 'a', str(e)
return 0,0,0
if __name__ == '__main__':
polar,confd,text=get_content('今天天气真好')
print '情感倾向:'+str(polar)+'n'+'程度:'+str(confd)+'n'+'文本:'+text运行结果
极性:1
程度:0.90936
文本:今天天气真好
(注:1代表正面情感;0代表中性;-1代表负面情感)
腾讯的情感分析号称是依托于腾讯千亿级社交语料的支撑,但我认为在使用过程中的准确性还是要看使用的场景,反正我用来分析酒店评论时并不是很满意得到的结果(可能需要专门的酒店语料库才能更加准确)。且text的长度上限200字节,这就造成了使用时较大的限制。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!