社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
原文链接:http://www.nicemxp.com/articles/12
背景:抓取捧腹网首页的段子和搞笑图片链接
如图:
地址:https://www.pengfu.com/
首页中有很多子页面:
这里抓取前10页的段子和图片链接。
首先写一个获取页面的接口,捧腹网页面可以直接获取,不需要做特殊处理,代码如下:
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
#读取数据
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
获取页面之后对页面进行提取处理,捧腹网的每一个段子是一个整体,在一个块级结构里,所以先对一个页面提取出所有的段子,然后在提取每个段子的文字描述和图片链接。
首先提取所有的段子,代码:
#捧腹网地址
PENGFU_URL = "https://www.pengfu.com/index_{0}.html"
#获取页面
html = getHtml(PENGFU_URL.format(1))
#提取段子的正则表达式
pattern = re.compile('<dl class="clearfix dl-con">(.*?)</dl>', re.S)
#获得所有的段子
articleRes = re.findall(pattern, html)
获取的所有的段子后,提取内容,捧腹网的段子要么是搞笑文字描述,要么是图片,其中图片有动图gif和静图,所以接下来循环遍历所有的段子,提取搞笑内容。代码:
#遍历段子
for article in articleRes:
#取图片或内容,有图片则提取图片,没有图片则提取文字描述
#静图链接正则表达式
pattern = re.compile('<div class="content-img.*?<img.*?jpgsrc="(.*?)".*?>.*?</div>', re.S)
#提取静图链接
jpg = re.search(pattern, article)
#动图链接正则表达式
pattern = re.compile('<div class="content-img.*?<img.*?gifsrc="(.*?)".*?>.*?</div>', re.S)
#提取动图链接
gif = re.search(pattern, article)
#判断是否有图片
if (jpg != None) or (gif != None):
#取链接
link = (gif != None) and gif.group(1) or jpg.group(1)
#存入结果
Res.append(link)
else: #没有图片,提取文字描述
#文字描述正则表达式
pattern = re.compile('<div class="content-img.*?>(.*?)</div>', re.S)
#提取文字描述
content = re.search(pattern, article)
if content == None:
continue
else:
#存入结果
Res.append(content.group(1))
这样获取了一个页面的所有的段子,获取前10页的段子同理,只需写一个遍历生成10个地址,逐一获取这10个地址的段子就好了。
接下来打印出提取的内容,代码:
#打印结果
for v in Res:
print(v.decode('utf8'))
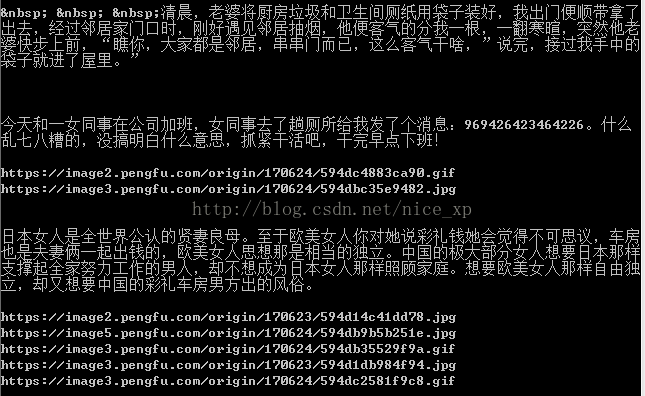
结果如下:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!