社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
一.安装爬虫
1、在搜索栏中输入anaconda,鼠标移至Anaconda Prompt上右键,选择打开文件位置,如图1所示。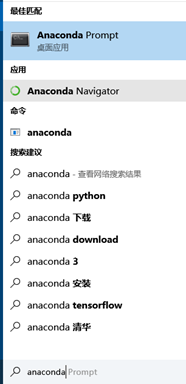
图 1
2、右键点击Anaconda Prompt,选择以管理员身份运行,如图2所示。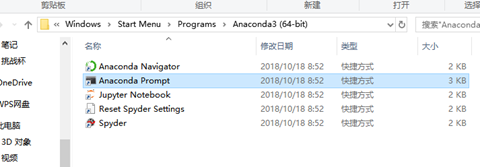
图 2
3、加载完成,输入:conda install scrapy并按回车,如图3所示。
图 3
4、加载完成后,输入y,确认安装,如图4所示。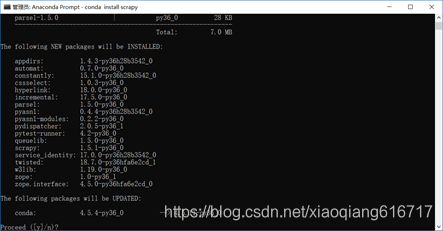
图4
5、安装完成后,输入scrapy,查看是否安装成功,如图5所示。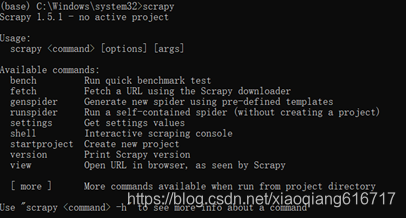
图5
二、用anaconda创建爬虫框架。
1、在除C以外的任意盘符下创建文件夹,并命名为scrapy,如图2.1所示。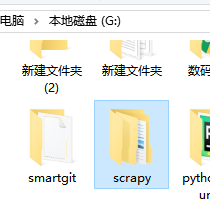
图2.1
2、用一中的方式打开Anaconda Prompt,输入创建文件夹的盘符+冒号 如图2.2所示。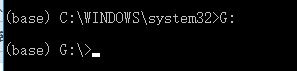
图2.2
3、用cd指令进入1中创建的文件夹,如图2.3所示。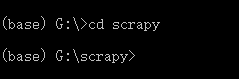
图2.3
4、输入scrapy startproject 文件夹名(jd_scrapy),如图2.4所示。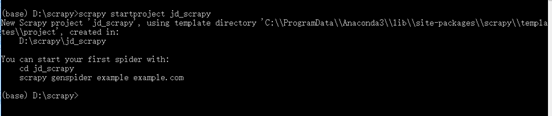
图2.4
5、输入图2.4中最后两行命令,将两个example换成自己创建项目的名称,如图2.5。
图2.5
三、打开项目。
1、打开pycharm,在左上角file中,选择open,如图3.1。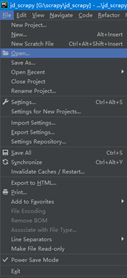
图3.1
2、在open中找到刚才创建文件夹的路径,选择第一个jd_scrapy点击ok,如图3.2。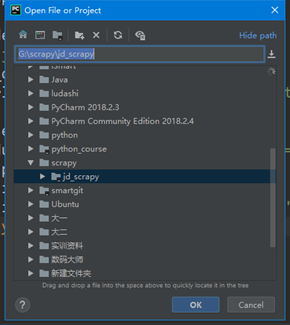
图3.2
3、选择new_window,如图3.3所示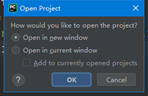
图3.3
四、配置环境。
1、选择file中的settings,如图4.1所示。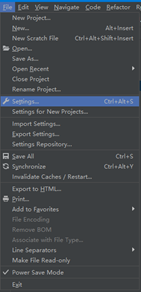
图4.1
2、在Project Interpreter中,将环境改为python3.6,如图4.2所示。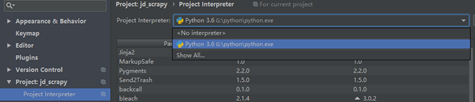
图4.2
五、修改程序。
1、右键第二个jd_scrapy选择new下的python file,如图5.1所示。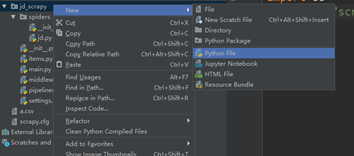
图5.1
2、新建main.py程序,如图5.2所示。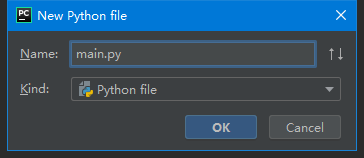
图5.2
3、在main.py中输入图5.3中代码,如图5.3所示。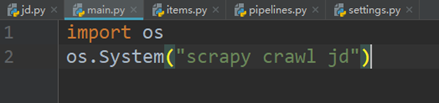
图5.3
4、双击打开items.py,将代码修改为图5.4所示。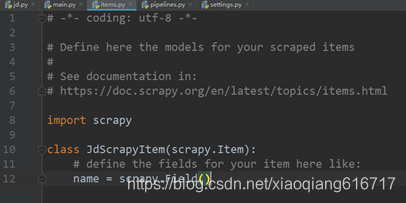
图5.4
5、双击打开pipelines.py,将代码修改为如图5.5所示。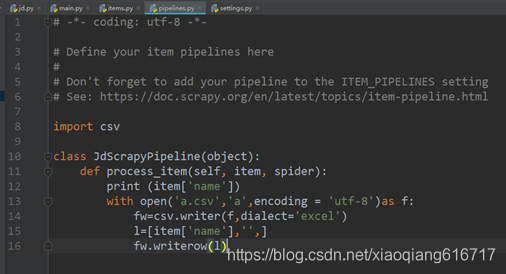
图5.5
6、双击打开settings.py文件,按ctrl+f打开搜索框,输入pip,并将后三行的注释去掉,如图5.6所示。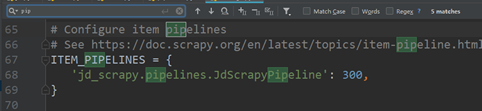
图5.6
7、双击打开jd.py文件,将代码修改为如图5.7所示。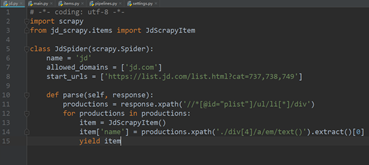
图5.7
注:图中第8行start_urls后的绿色区域改为要爬取的网址。
图中第11行后的绿色区域为所要爬取的区域的xpath。
图中第14行后的绿色区域为爬取内容的xpath。
建议使用谷歌浏览器。
六、xpath爬取方法。
1、打开要爬取的网址,按f12或者fn+f12,打开开发者工具,如图6.1所示。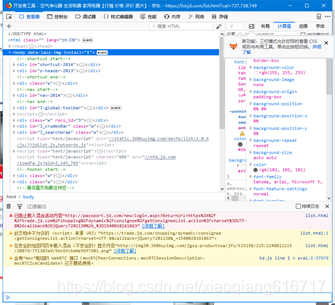
图6.1
2、点击左上角的图标(图6.2)选择爬取区域(图6.3)后单击,所选区域代码会变蓝(图6.4)。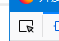
图6.2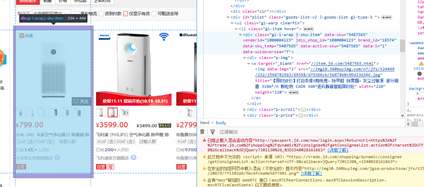
图6.3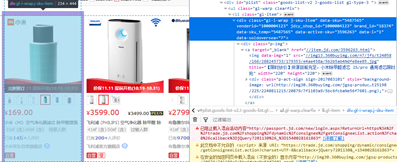
图6.4
3、右键所选区域,复制xpath如图6.5所示。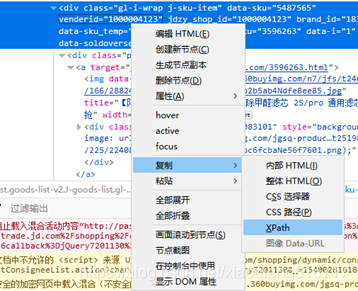
图6.5
3、直接将区域的xpath和爬取内容的xpath粘进jd.py,如图6.6所示。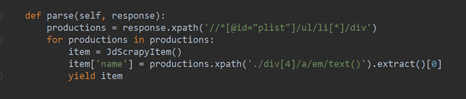
图6.6
七、爬取代码。
1、在pycharm左下角单击图标,打开Terminal,如图7.1所示。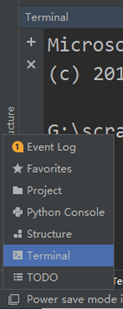
图7.1
2、在框内输入scrapy crawl jd,运行项目。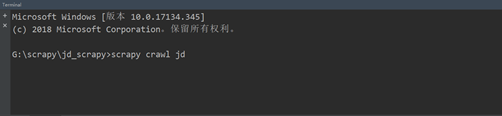
图7.2
八、爬取成功,双击打开左侧a.csv查看结果,如图8.1所示。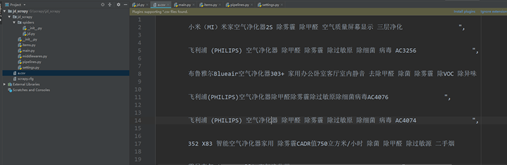
图8.1
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
