社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
这是一个(不止一个)来自在校大学生的python爬虫项目,项目通过很多个项目来进行python爬虫的一步一步学习。严肃脸:从简单到复杂,了解我像一个傻子到一个聪明一点的傻子的一步步摸索。笑…
说在前面:环境安装可以跳过但是请大家务必看看…
如果有安装Anaconda Navigator集成环境的coder 这一节就可以跳过了
讲个笑话 说要学一个东西 到现在配置不来环境的 还是大有人在…所以我还是简单地说下,环境配置的重要性还有爬虫需要的环境…
首先你总得有一个python的环境吧…先去官网下一个:python官网
Like this:
下载我就不多说了 随便下个地方就好了然后是安装:
划重点:记得把python加到系统目录,也就是path里面,别点快了
然后我就不多说了,一直next next next next…
还有记得默认添加功能的时候 记的加上pip这个
好了 有谁还记得我这个博客是为了讲python爬虫而不是python安装呢?
上个小结我讲过勾上pip库 好了 现在是时候体现他功能的时候了!
如果没有安装的没关系!请疯狂点击:python pip库安装
好了现在默认大家都安装好了pip库 接下来我们就安装requests库
请打开cmd 也就是windows的控制台:输入pip install requests
好了现在我们来介绍下request库:requests库
好了介绍完了
真的好用真的好用真的好用!
重要的事情说三遍!
请手动链接pycharm官网:PyCharm官网
点击下载就好了 至于激活码—— 戳这里
这是一个功能还是比较强大的解析器 通过request获取网页源码之后 这个库就可以帮助解析网页中的各种元素 目前是我爬虫中用得最多的解析器 其他的解析器我就不说了 因为…我自己还没有学哈哈哈
一样的 在cmd环境下 输入pip install beautifulsoup4
然后介绍下BeautifulSoup库…BeautifulSoup库
感谢崔老师的介绍
后面我们统一讲一下用法
好东西啊好东西 学会正则表达式 相当于拥有了全世界!
正则表达式
再次感谢崔老师的教程
这个嘛 主要是因为…有些网站比较顽劣 没有办法通过request直接获得源码 所以我就需要selenium来模仿人工操作来设置 所以我们就用到了selenium
selenium是一个可以操作浏览器的库 是一个特别强大的库
至于他有多强大 玩儿过网页游戏的人都知道
这个东西 可以用来写网页游戏的脚本
你需要准备的: 谷歌chrome浏览器 selenium库 还有chromedriver驱动
版本对照表
版本下载地址
当你下载完成后 在任意一个地方新建一个命名为chromedriver文件夹 将解压的chromedriver.exe放进文件夹 再配置进path环境变量
至于怎么弄进环境变量…
进入我的电脑 右键点击进入属性 然后是高级系统环境 环境变量 上面是用户变量 下面是系统变量 在下面找到path 哦应该是Path 会出来所有的系统变量path 然后点击右边的浏览 然后指向你放驱动的文件夹 确定确定确定确定确定就好了…
因为懒 所以不放图了 做不到就是你悟性不够
import os
import requests
from bs4 import BeautifulSoup
# 保存文件夹目录
folder = "C:\UsersYYFLCYJDesktopImage"
# 判断是否创建文件夹
if not os.path.exists(folder):
# 创建文件夹
os.mkdir(folder)
# 改变操作目录
os.chdir(folder)
for i in range(2, 40):
# 创建网络链接
url = "http://pic.ali213.net/html/2018-11-23/84797_" + str(i) + ".html"
# 获取网站requests对象
r = requests.get(url)
# 改变编码格式
r.encoding = "utf-8"
# 获取soup对象
soup = BeautifulSoup(r.text, "lxml")
# 寻找图片img标签
a = soup.find('img', id="bigImg")
# 获取img对象的src对象内容
img = requests.get(a.get("src"))
# 保存图片
f = open(str(i) + ".jpg", "wb")
f.write(img.content)
f.close()
PS:这个是最原始的 我最开始学的时候写的 注释和代码都差不多长…
而且还有一些bug也懒得改了
该有的地方已经打上了注释 大家可以自己尝试运行一下
这一步不需要使用浏览器驱动 如果上一步安装驱动没有成功的 也能实现
好了 这个简单的爬虫就讲完了 如果你们不会 那就是没看清楚 再看一遍 你可能就清楚了
(就算是我的锅 我也不认)
来看看小姐姐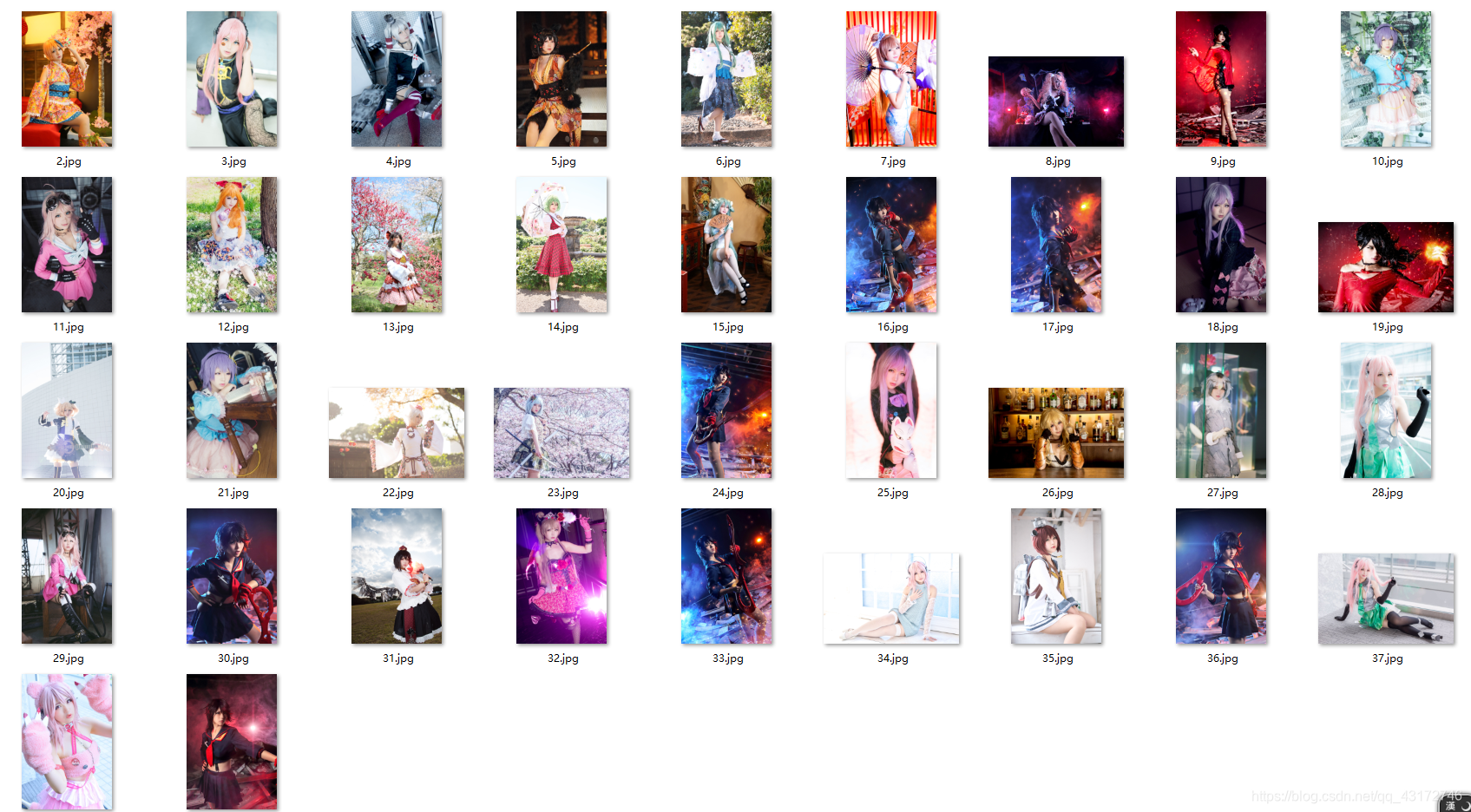
想想啊 如果以后你们需要获取很多的soup对象 不可能每次都去一步一步写 所以我们需要函数
这个可以大大地减少代码量 也可以让人看起来 头不疼…
Like this:
# 获取soup对象
def get_soup(url):
r = requests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r.text, "lxml")
return soup
# 检测文件夹目录
def check_and_change_folder(folder):
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
把检测文件目录和获取soup对象都封装进了函数 这样要用的时候直接调用 你就知道 比那些什么复制粘贴爽多了
import os
import requests
import re
import time
from bs4 import BeautifulSoup
# 获取soup对象
def get_soup(url):
r = requests.get(url)
r.encoding = "gbk"
soup = BeautifulSoup(r.text, "lxml")
return soup
# 检测文件 夹目录
def check_and_change_folder(folder):
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
folder = "E:Spider_data摸鱼Spider"
check_and_change_folder(folder)
for e in range(4224, 60, -1):
url = "https://www.mooyuu.com/illust/" + str(e)
soup = get_soup(url)
pic = soup.find_all("a", class_="piclink")
a = soup.find("h1", class_="wname")
if a is None:
continue
name = list(a.text)
for ele in name:
if ele in ["\", "/", "*", ":", "<", ">", """, "|"]:
name.pop(name.index(ele))
name = "".join(name)
i = 1
for each_one in pic:
srcc = each_one.img.get("src")
if srcc[-3] == "g":
Format = ".gif"
elif srcc[-3] == "j":
Format = ".jpg"
elif srcc[-3] == "p":
Format = ".png"
src = requests.get(each_one.img.get("src"))
try:
f = open(name + "(" + str(i) + ")" + Format, "wb")
except FileNotFoundError:
print(e, ":命名失败")
continue
except OSError:
print(e, ":命名失败")
continue
except AttributeError:
print(e, ":命名失败")
continue
except ValueError:
print(e, ":命名失败")
continue
finally:
try:
f.write(src.content)
f.close()
except NameError:
print(e, ":命名失败")
pass
except ValueError:
print(e, ":命名失败")
pass
i += 1
time.sleep(0.5)
大致的过程还是和之前的一样 不过我进阶了很多的东西
首先 是文件命名问题
我最开始也是像游侠网一样 是用的1 2 3 4 5这样的命名 一张图就加一个 后面我觉得这样不行…
感觉很low…所以我多了一层爬虫 我获取了这类组图的名字 作为名字来命名 这已经在我代码中体现了
然后是同组的图 加上了(1)(2)这样的后缀用来区分
完美!
当然 你看到了我那一堆命名失败 一堆异常处理机制 就知道这个事情并不简单
首先 有些人在对自己图片命名的时候 是用了一些无法作为文件名的字符 就像* /这种
name = list(a.text)
for ele in name:
if ele in ["\", "/", "*", ":", "<", ">", """, "|"]:
name.pop(name.index(ele))
name = "".join(name)
这一段 就是在处理那些稀奇古怪的名字…转换成列表 然后去掉特殊字符 然后再转换成字符串
完美!
真香!
我又滚回来了 那一堆命名错误是我没有办法处理的 因为…
那个网页 根本没有东西
很恐怖是不是
这不是因为我没有联网什么的 也不是因为什么404啊什么的
因为那个网页…
你看是不是很恐怖 这个怎么爬?
告辞 我们下一节见
莫慌 我给你们看看我的成果 给你们一点信心: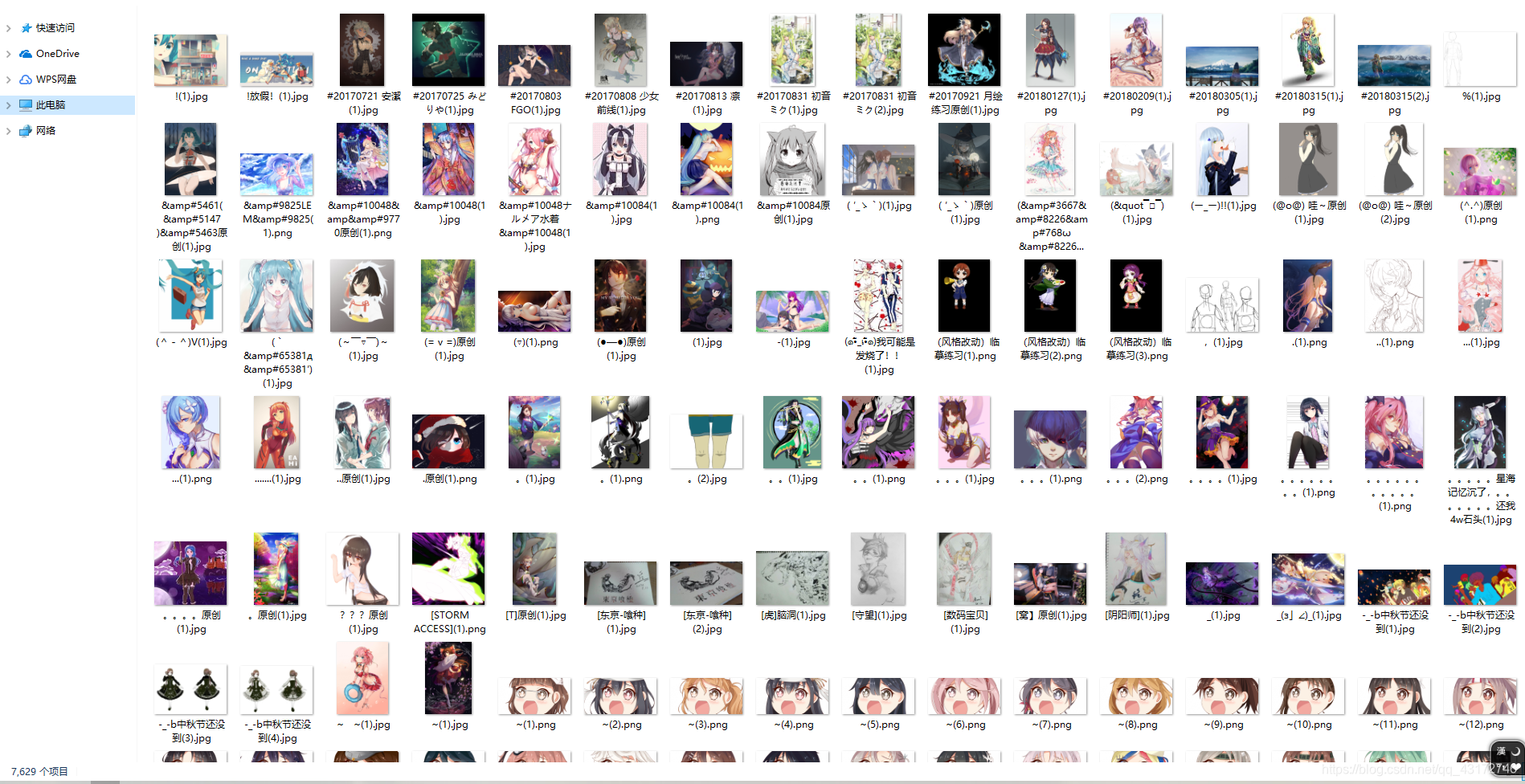
看到左下角的项目数了吗 收获颇丰哈哈哈
import os
import requests
import re
import time
from bs4 import BeautifulSoup
# 获取soup对象
def get_soup(url):
r = requests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r.text, "lxml")
return soup
# 检测文件夹目录
def check_and_change_folder(folder):
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
# 页码获取
def get_page(url):
soup = get_soup(url)
page_part = soup.find("span", class_="pages")
pages = page_part.string
print("页面总", end="")
for i in range(6, len(pages)):
print(pages[i], end="")
print()
# 爬虫主程序
def spider(chance, folder, page_num):
next_folder = folder + "\" + class_list_cn[chance]
check_and_change_folder(next_folder)
page = [""]
if page_num != 1:
page_num += 1
for each in range(2, page_num):
page.append("/page/" + str(each))
for index in page:
url = "http://sudasuta.com/category/" + class_list[chance] + index
soup = get_soup(url)
a = soup.find_all("a", class_="img_preview")
# 获取图片集合的网址
link_list = []
for each in a:
aa = each.get("href")
link_list.append(aa)
for each in link_list:
soup = get_soup(each)
href = soup.find("a", href=each)
name = href.get("title")
new_folder = next_folder + "\" + name
check_and_change_folder(new_folder)
i = 1
img = soup.find_all("img", alt=name)
# 保存每张图片
for each_one in img:
src = requests.get(each_one.get("src"))
f = open(str(i) + ".jpg", "wb")
f.write(src.content)
f.close()
i += 1
time.sleep(0.5)
class_list = {"1": "art", "2": "photo", "3": "life", "4": "ins", "5": "design",
"6": "ui", "7": "post", "8": "freeby", "9": "tutrial", "0": "tao"}
class_list_cn = {"1": "插画", "2": "摄影", "3": "生活", "4": "灵感", "5": "产品设计",
"6": "界面设计", "7": "原创", "8": "下载", "9": "教程", "0": "淘生活"}
folder = "E:Spider_data苏打苏塔Spider"
check_and_change_folder(folder)
while True:
print("(1)插画 (2)摄影 (3)生活 (4)灵感 (5)产品设计n(6)界面设计 (7)原创 (8)下载 (9)教程 (0)淘生活")
chance = input("请输入需要爬取的分类:")
get_page("http://sudasuta.com/category/" + class_list[chance])
page_num = int(input("请输入需要爬取的页数:"))
print("正在爬取 请稍等(根据您的网速 您可以去看个电影什么的再回来 我觉得差不多了)")
spider(chance, folder, page_num)
c = int(input("爬取完成 请输入(1)继续爬取 或 (2)退出程序"))
if c != 1:
print("感谢使用,下次见")
break
这个项目呢 我加入了很多自己的东西 比如类似界面的设计
可以操作的爬虫选项
我们先来看看苏打苏塔的网站
我爬取的项目就是根据首页的导航栏进行爬取
我们再继续看看里面的东西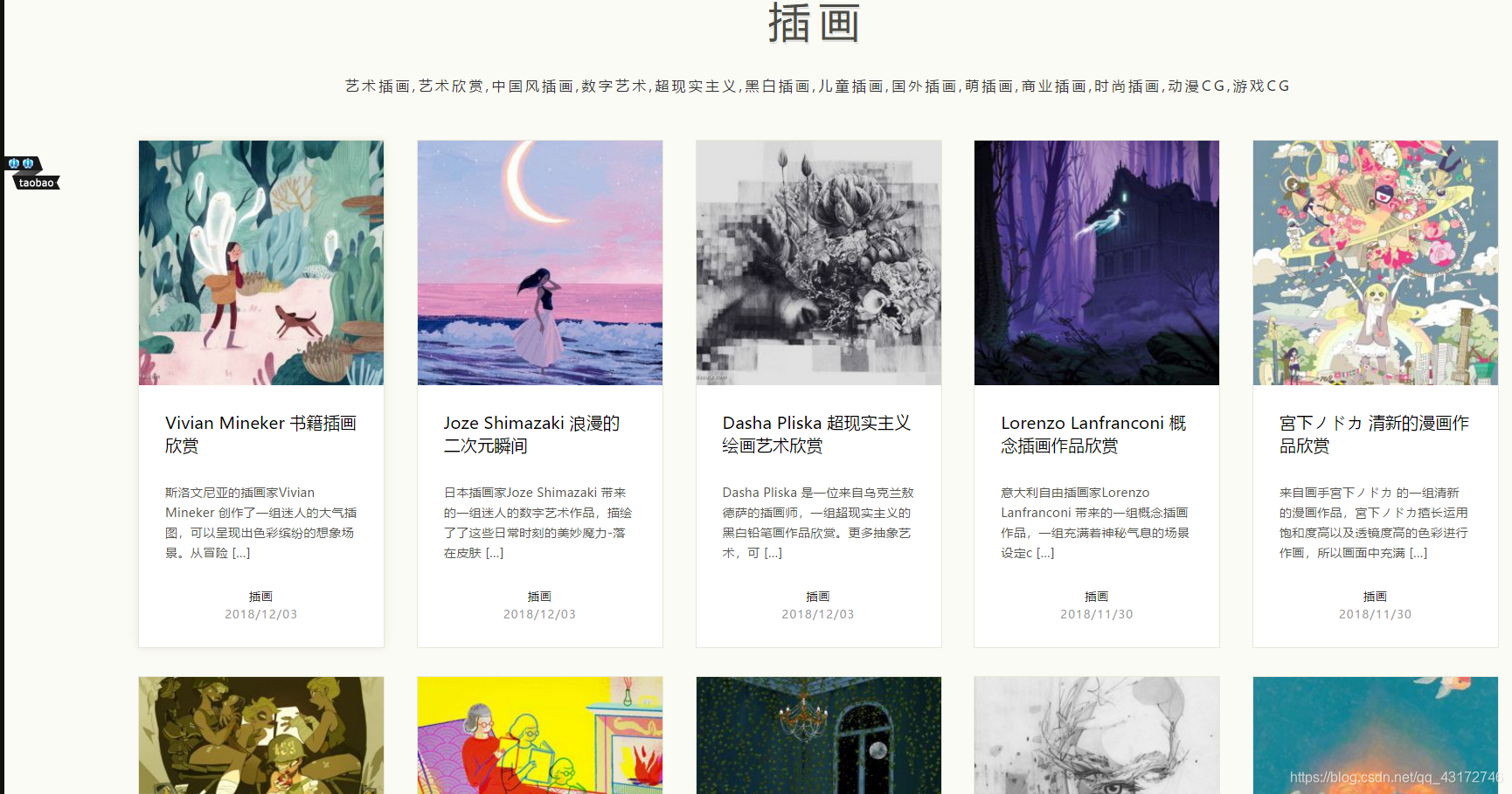
大概就是这样的界面 每一张图片就是一个图库
所以我通过首页索引 找到了上面一堆索引的后缀 直接根据需要拼接链接
然后通过我代码的导引 用户…咳咳…使用者可以设定想爬取的分类
确定分类之后 我又获取了页码元素
当然 这种网站 随便都是几百页图
所以不可能全部爬下来 最多也就一部分
所以就可以选择需要的页码
之后就是爬取了
还是那种思路
获取图库链接
然后找到每一张图的src(通过class 通过target什么的 找到img对象 然后通过img.get(“src”)获得)
通过src保存图片
好了 这个项目的新功能又来了
单独命名文件夹 把图片保存在文件夹中
就像这样的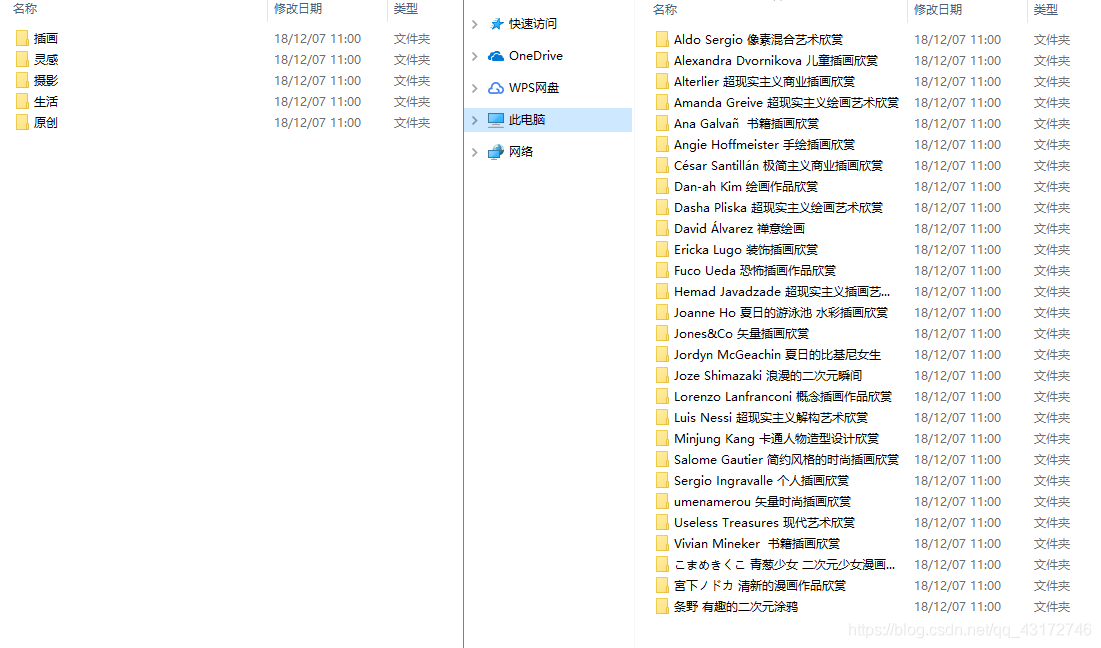
什么的日文俄文的 都能用 只要能用来命名文件的都可以
而且苏打苏塔这个网站 比摸鱼那个坑人的东西好多了
因为他们命名很规范
所以我不用再额外加入规范格式的代码
这就让我很省心
反正写起来就是各种舒服
from selenium import webdriver
import time
from bs4 import BeautifulSoup
import re
import os
import requests
# 检测文件 夹目录
def check_and_change_folder(folder):
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
# 通过browser获取网页soup元素
def get_soup(link, buttom):
browser = webdriver.Chrome()
browser.get(link)
if buttom:
move_down(browser, times=20)
time.sleep(2)
soup = BeautifulSoup(browser.page_source, "lxml")
browser.close()
return soup
def move_down(browser, times):
# 将滚动条移动到页面的底部
js = "var q=document.documentElement.scrollTop=100000"
for i in range(times):
browser.execute_script(js)
time.sleep(1.5)
# # 将滚动条移动到页面的顶部
# js = "var q=document.documentElement.scrollTop=0"
# browser.execute_script(js)
# time.sleep(3)
# # 若要对页面中的内嵌窗口中的滚动条进行操作,要先定位到该内嵌窗口,在进行滚动条操作
# js = "var q=document.getElementById('id').scrollTop=100000"
# browser.execute_script(js)
# time.sleep(3)
# 储存图片并命名
def save_image(url, i, name):
Format = ""
if url[-1] == "p":
li = url.split("@")
print(li)
url = li[0]
if url[-3] == "g":
Format = ".gif"
elif url[-3] == "j":
Format = ".jpg"
elif url[-3] == "p":
Format = ".png"
if not Format:
return
f = open(name + "(" + str(i) + ")" + Format, "wb")
f.write(requests.get(image).content)
f.close()
# 获取图片名字
def get_name(soup):
div = soup.find("div", class_="title-ctnr")
name = div.h1.text
return name
folder = "C:\UsersYYFLCYJDesktopBilibili"
check_and_change_folder(folder)
url = "https://h.bilibili.com/eden/draw_area#/all/hot"
k = 0
soup = get_soup(url, buttom=1)
a = soup.find_all("a", {"href": re.compile("//h.bilibili.com/" + "[0-9]")})
for each in a:
i = 1
k = k ^ 1
if not k:
continue
src = each.get("href")
src = "https:" + src
soup = get_soup(src, buttom=0)
name = get_name(soup)
name = list(name)
for ele in name:
if ele in ["\", "/", "*", ":", "<", ">", """, "|"]:
name.pop(name.index(ele))
name = "".join(name)
b
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_43172746/article/details/84943102
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
